L20) L’inférence
[!info] Série « Asymétrie génération-reconnaissance »
Cet article accompagne l’article de recherche The Generation-Recognition Asymmetry: Six Dimensions of a Fundamental Divide in Formal Language Theory (📄 arXiv).
Fil de lecture : L13 · L14 · L15 · L16 · L17 · L18 · L19 · L20 — ou l’index complet.
La troisième direction
Quand la grammaire elle-même est inconnue
Générer suppose qu’on connaît les règles. Reconnaître aussi. Mais que se passe-t-il quand on ne dispose que d’exemples — et qu’il faut deviner les règles ? Ce troisième usage d’une grammaire est le plus difficile des trois. Au point qu’à partir d’exemples positifs seuls, c’est tout simplement impossible.
Où se situe cet article ?
L13 a posé la triade : une grammaire peut servir à générer, à reconnaître, ou à inférer. Les articles précédents ont creusé les deux premières directions. Celui-ci s’attaque à la troisième — la moins étudiée, la plus dure — et montre qu’elle n’est pas un domaine à part, mais l’extrémité d’un continuum dont la reconnaissance occupe l’autre bout. C’est la dimension D5 de l’article de recherche que cette série vulgarise.
Pourquoi c’est important ?
L’inférence grammaticale, c’est le problème de l’acquisition : comment un enfant apprend sa langue, comment un système découvre la structure d’un corpus sans qu’on la lui donne. C’est aussi, en musique, le rêve de l’analyste computationnel : faire émerger la grammaire d’un style à partir d’un corpus d’œuvres (M10).
Or ce problème a une réputation trompeuse. On l’imagine « difficile mais faisable ». La théorie dit autre chose : dans son cadre le plus pur, il est impossible — et les échappatoires qui le rendent praticable révèlent exactement ce qu’il faut savoir d’avance pour apprendre.
L’idée en une phrase
L’inférence n’est pas une opération séparée mais le cas extrême de la reconnaissance lorsque la connaissance de la grammaire tombe à zéro — un régime où le théorème de Gold interdit l’apprentissage à partir d’exemples positifs seuls, et où apprendre revient à compresser.
Expliquons pas à pas
1. Trois usages, pas deux
Rappel de L13 :
| Opération | Donné | Cherché |
|---|---|---|
| Génération | la grammaire $G$ | une chaîne $s$ |
| Reconnaissance | $G$ + une chaîne $s$ | la structure de $s$ |
| Inférence | un corpus $\{s_1, \dots, s_k\}$ | la grammaire $G$ |
La différence saute aux yeux : dans les deux premières, la grammaire est connue. Dans la troisième, c’est précisément elle qu’on cherche. L’inférence ne présuppose rien — ni la grammaire, ni la structure. Tout est à découvrir.
2. L’inférence comme cas extrême de la reconnaissance
Plutôt que d’opposer reconnaissance et inférence, on peut les placer sur un même axe : celui de la connaissance grammaticale disponible, que nous noterons $\kappa$ (kappa).
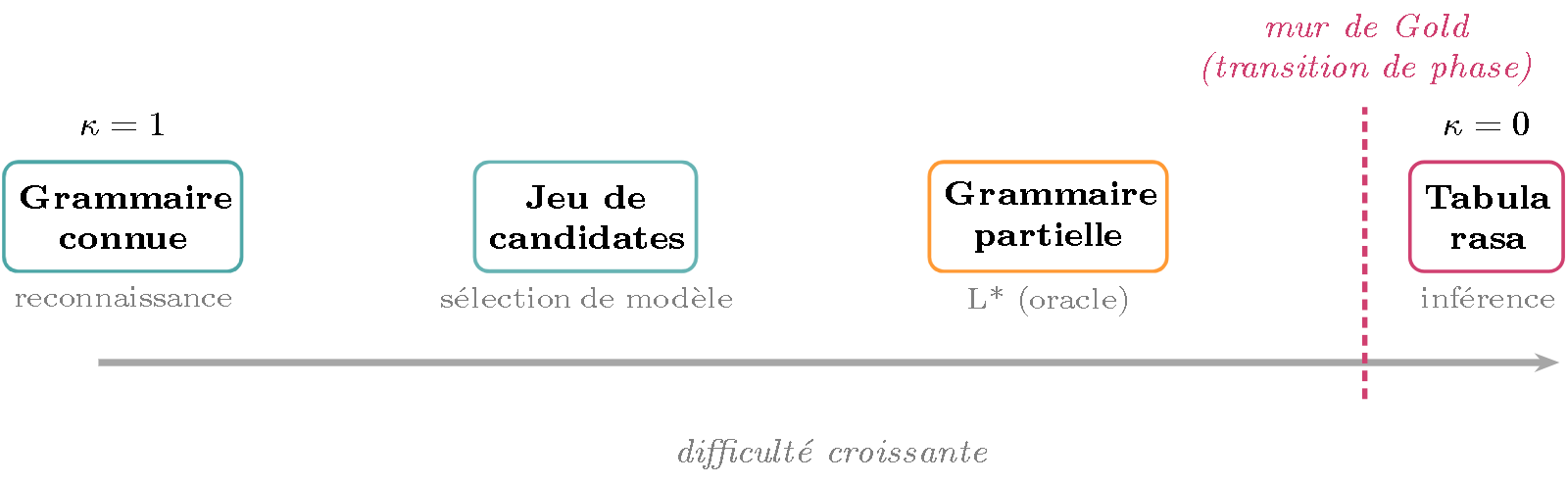
Figure 1 — Le gradient de connaissance $\kappa$. À gauche ($\kappa = 1$), la grammaire est entièrement connue : c’est la reconnaissance standard. À droite ($\kappa = 0$), aucune connaissance préalable : c’est l’inférence pure. Entre les deux, des régimes intermédiaires (jeu de grammaires candidates, grammaire partielle avec oracle). Le mur de Gold marque une transition de phase près de $\kappa = 0$ : juste avant, l’apprentissage reste possible en principe ; à $\kappa = 0$, il devient impossible pour les classes riches.
L’inférence n’est donc pas « autre chose » que la reconnaissance : c’est ce qu’elle devient quand on lui retire toute connaissance préalable. Et cette retraite n’est pas graduelle — elle bute sur un mur.
3. Le théorème de Gold : l’impossibilité
En 1967, E. Mark Gold démontre un résultat fondateur, l’identification à la limite :
Théorème (Gold, 1967). Soit une classe de langages contenant tous les langages finis et au moins un langage infini (une classe dite superfinie). Alors cette classe n’est pas identifiable à la limite à partir de données positives seules : aucun algorithme ne peut garantir la convergence vers la grammaire correcte en ne voyant que des exemples valides.
Décryptage — « identification à la limite ». L’apprenant reçoit les exemples un à un, et propose une grammaire après chacun. Il « identifie à la limite » s’il finit, au bout d’un nombre fini d’exemples, par proposer la bonne grammaire et ne plus en changer. Gold prouve que pour les classes intéressantes (qui incluent les langages réguliers et au-delà), aucun apprenant ne peut le garantir.
Pourquoi ? Parce qu’avec des exemples positifs seuls, rien n’interdit jamais de surgénéraliser : si on a vu ab, aabb, aaabbb, faut-il conjecturer $\{a^n b^n\}$, ou $\{a^m b^n\}$, ou « toutes les chaînes » ? Sans contre-exemples (des chaînes hors du langage), on ne peut pas trancher. C’est la transition de phase de la Figure 1 : un soupçon de savoir préalable rend l’apprentissage possible ; zéro savoir le rend impossible.
4. Pourquoi c’est qualitativement plus dur
L’écart entre reconnaissance et inférence est plus profond que celui entre génération et reconnaissance. Deux résultats le quantifient.
Pitt & Warmuth (1993) : le problème du plus petit automate déterministe (DFA) consistant avec les données n’est pas seulement NP-difficile — il est non approximable à l’intérieur d’aucun polynôme. Même trouver une solution approchée est hors de portée.
Kearns & Valiant (1994) : apprendre des DFA dans le cadre PAC est aussi difficile que casser le chiffrement RSA. Autrement dit, un apprenant efficace fournirait un algorithme efficace pour briser la cryptographie à clé publique — ce qu’on tient pour impossible. C’est une borne inférieure cryptographique sur la difficulté de l’inférence.
Décryptage — PAC. Probably Approximately Correct : un cadre d’apprentissage où l’on demande, avec haute probabilité, une hypothèse approximativement correcte. C’est le cadre standard de la théorie de l’apprentissage.
Là où le parsing est polynomial pour les grammaires usuelles, l’inférence se heurte à des murs d’impossibilité et de cryptographie. Elle n’est pas « plus lente » : elle est d’une autre nature.
5. Les échappatoires — et ce qu’elles coûtent
L’inférence est donc impossible dans le cadre de Gold. Mais on apprend bien des langues, et les machines induisent bien des modèles. Comment ? En changeant le cadre — et chaque changement révèle ce qu’il faut savoir d’avance.
- Le cadre probabiliste / bayésien. Si l’on apprend des grammaires stochastiques (PCFG — voir B1) avec une distribution a priori, cet a priori brise la symétrie que Gold exploitait : il pénalise les grammaires trop générales. L’apprentissage redevient possible en principe (de la Higuera 2010, ch. 16), mais le coût computationnel reste prohibitif pour de grandes grammaires.
- L’oracle d’appartenance. L’algorithme L\ d’Angluin (1987) apprend efficacement les langages réguliers — mais il exige un oracle* qui répond « cette chaîne est-elle dans le langage ? ». Or répondre à cette question, c’est… reconnaître. L’inférence efficace présuppose la reconnaissance. On est au point $\kappa$ intermédiaire de la Figure 1, pas à $\kappa = 0$.
Chaque échappatoire confirme la leçon : on n’apprend pas à partir de rien. Il faut un biais (l’a priori) ou une capacité de reconnaissance (l’oracle).
6. Inférer, c’est compresser
Il existe une façon élégante de comprendre pourquoi l’inférence est l’inverse de la génération. Le principe MDL (Minimum Description Length, Rissanen 1978 ; Grünwald 2007) reformule l’apprentissage comme compression : la meilleure grammaire est celle qui minimise la description totale = taille de la grammaire + taille des données encodées avec elle.
Gregory Chaitin l’énonce sans détour :
« A theory is good to the extent that it compresses the data into a much smaller set of theoretical assumptions. The greater the compression, the better! »
— Chaitin (2005)
D’où une symétrie limpide avec L18 :
- Générer = décompresser : déployer une description compacte (la grammaire) en données (les chaînes).
- Inférer = compresser : trouver la description compacte qui rend compte des données.
Et compresser est notoirement plus difficile que décompresser. L’asymétrie compression/décompression est une autre manifestation du même clivage — celui qui traverse tout l’article.
7. En musique : l’oreille qui apprend un style
L’inférence grammaticale musicale, c’est le problème inverse de la composition par grammaire. Au lieu d’écrire les règles d’un style et de générer, on part d’un corpus (des improvisations, un répertoire) et on infère les règles. C’est le sujet de M10 : Gold, Sequitur, MDL, COSIATEC, et le système QAVAID de Bernard Bel pour l’analyse des bols.
Le mur de Gold y est concret : un corpus, ce sont des exemples positifs (ce qui a été joué), rarement des contre-exemples explicites (ce qui serait « faux » dans le style). D’où la difficulté à inférer une grammaire de style sans biais fort — exactement ce que prédit la théorie.
Et l’oreille humaine ? Elle s’en sort parce qu’elle n’est jamais à $\kappa = 0$ : elle arrive avec des biais (préférence pour la régularité, attentes tonales — voir L19) et un oracle implicite (le sentiment que « ça sonne juste » ou « faux »). L’apprenant musical n’infère pas dans le vide : il infère depuis un riche $\kappa > 0$.
Ce qu’il faut retenir
- L’inférence est le troisième usage d’une grammaire : deviner les règles à partir d’exemples seuls.
- Elle n’est pas un domaine séparé mais le cas extrême de la reconnaissance, au bout du gradient de connaissance $\kappa$ (de la grammaire connue à la tabula rasa).
- Le théorème de Gold (1967) : à partir de données positives seules, les classes riches ne sont pas identifiables — une transition de phase, pas une dégradation graduelle.
- Elle est qualitativement plus dure : non approximable (Pitt & Warmuth), aussi difficile que casser RSA (Kearns & Valiant).
- Les échappatoires (a priori bayésien, oracle d’appartenance de L*) confirment qu’on n’apprend pas à partir de rien : il faut un biais ou une capacité de reconnaissance.
- Inférer = compresser (MDL) ; générer = décompresser. La même asymétrie, vue sous l’angle de la théorie de l’information.
- En musique, le mur de Gold explique la difficulté d’induire une grammaire de style ; l’oreille humaine y échappe parce qu’elle n’est jamais à $\kappa = 0$.
Pour aller plus loin
L’inférence grammaticale
- Gold, E.M. (1967). « Language Identification in the Limit. » Information and Control 10(5), 447-474 — le théorème d’impossibilité.
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press — la référence du domaine.
- de la Higuera, C. (2005). « A Bibliographical Study of Grammatical Inference. » Pattern Recognition 38(9), 1332-1348. DOI:10.1016/j.patcog.2005.01.003
- Angluin, D. (1987). « Learning Regular Sets from Queries and Counterexamples. » Information and Computation 75(2), 87-106 — l’algorithme L*.
Les bornes de dureté
- Pitt, L. & Warmuth, M.K. (1993). « The Minimum Consistent DFA Problem Cannot Be Approximated within Any Polynomial. » Journal of the ACM 40(1), 95-142.
- Kearns, M. & Valiant, L. (1994). « Cryptographic Limitations on Learning Boolean Formulae and Finite Automata. » Journal of the ACM 41(1), 67-95.
Compression et MDL
- Rissanen, J. (1978). « Modeling by Shortest Data Description. » Automatica 14(5), 465-471.
- Grünwald, P. (2007). The Minimum Description Length Principle. MIT Press.
- Chaitin, G.J. (2005). Meta Math!: The Quest for Omega. Pantheon Books.
L’article de recherche vulgarisé
- Peyrichou, R. (2026). The Generation-Recognition Asymmetry… §4.5 développe l’inférence comme dimension D5 et le gradient de connaissance. Préprint arXiv:2603.10139 — https://arxiv.org/abs/2603.10139
Dans le corpus
- L13 — Les trois usages d’une grammaire
- M10 — L’induction de grammaires musicales (Gold, Sequitur, MDL, QAVAID)
- L18 — Génération = décompression, le pendant de l’inférence
- L19 — La prédiction d’erreur comme moteur de l’apprentissage
- B1 — Les grammaires probabilistes
Glossaire
- Inférence grammaticale (induction) : découvrir une grammaire à partir d’un corpus d’exemples, sans qu’elle soit donnée.
- Identification à la limite : critère de Gold ; l’apprenant converge vers la bonne grammaire après un nombre fini d’exemples et n’en change plus.
- Classe superfinie : classe de langages contenant tous les langages finis et au moins un infini ; non identifiable à partir de positifs seuls.
- Données positives : exemples appartenant au langage (sans contre-exemples explicites de ce qui en est exclu).
- Gradient de connaissance ($\kappa$) : quantité de connaissance grammaticale disponible, de 1 (grammaire connue, reconnaissance) à 0 (tabula rasa, inférence).
- PAC (Probably Approximately Correct) : cadre d’apprentissage exigeant une hypothèse approximativement correcte avec haute probabilité.
- Oracle d’appartenance : procédure répondant « cette chaîne est-elle dans le langage ? » ; requise par L*, donc présuppose la reconnaissance.
- MDL (Minimum Description Length) : principe selon lequel le meilleur modèle minimise la taille totale (modèle + données encodées). Apprendre = compresser.
Liens dans la série
- L13 — Générer ou reconnaître — la triade et la dimension D5
- M10 — Induction de grammaires musicales — l’inférence appliquée à la musique
- L18 — Le renversement de signe — compression vs décompression
- L19 — Le P-chain — l’apprentissage par prédiction d’erreur
Prérequis : L13, L1
Temps de lecture : 11 min
Tags : #inférence-grammaticale #Gold #MDL #compression #apprentissage #gradient-de-connaissance