L18) Le renversement de signe
[!info] Série « Asymétrie génération-reconnaissance »
Cet article accompagne l’article de recherche The Generation-Recognition Asymmetry: Six Dimensions of a Fundamental Divide in Formal Language Theory (📄 arXiv).
Fil de lecture : L13 · L14 · L15 · L16 · L17 · L18 · L19 · L20 — ou l’index complet.
Pourquoi « générer est facile, analyser est difficile » est faux
Tout le monde le répète : produire une phrase est trivial, la comprendre est coûteux. C’est une demi-vérité qui devient un mensonge dès qu’on regarde de près. Sous la bonne contrainte, générer peut être strictement plus difficile que parser — et ce n’est pas une intuition, c’est un théorème.
Où se situe cet article ?
Cet article prolonge la première dimension (D1, Complexité) de l’asymétrie génération-reconnaissance étudiée dans L13 et L17. La matrice de complexité de L17 montrait déjà que la génération sous contrainte « chauffe » ; ici nous allons jusqu’au bout du raisonnement et nous nommons le phénomène : le renversement de signe. C’est le résultat le plus contre-intuitif de l’article de recherche que cette série vulgarise.
Pourquoi c’est important ?
Le slogan « generation is easy, parsing is hard » structure une grande partie de l’intuition en informatique et en linguistique computationnelle. Il justifie qu’on consacre des décennies de recherche aux algorithmes de parsing (LL, LR, Earley, CYK — voir L14) et beaucoup moins à la génération. Mais si le slogan est faux dans les cas qui comptent, alors notre carte mentale de la difficulté est fausse.
L’enjeu n’est pas rhétorique. Concevoir un système qui génère du texte, de la musique ou du code sous contraintes (un sens cible, un format imposé, une exigence de sécurité), c’est se confronter exactement au cas où la génération devient coûteuse. Comprendre quand et pourquoi évite de sous-dimensionner un système entier.
L’idée en une phrase
La génération non contrainte est triviale ($\mathcal{O}(n)$), mais la génération sous contrainte sémantique peut être exponentielle voire NP-complète — donc strictement plus difficile que le parsing — parce que le vrai facteur n’est pas « quelle opération », mais « qui impose la contrainte ».
Expliquons pas à pas
1. La vision naïve, et pourquoi elle séduit
L’intuition derrière le slogan est réelle. Pour générer, il suffit de partir de l’axiome de la grammaire et d’appliquer des règles au hasard jusqu’à atteindre des symboles terminaux. Aucune décision difficile : à chaque étape, on choisit une règle et on l’applique. Pour parser, au contraire, il faut reconstruire une structure cachée à partir de la seule surface — résoudre des ambiguïtés, explorer des hypothèses concurrentes.
D’où le tableau mental : génération $= \mathcal{O}(n)$ (linéaire en la longueur de la dérivation), parsing $= \mathcal{O}(n^3)$ pour les grammaires context-free (la borne de l’algorithme CYK — voir L15). Génération facile, parsing dur. Fin de l’histoire ?
2. Oui, la génération non contrainte est bien triviale
Commençons par accorder ce qui est vrai. La génération libre — appliquer les règles sans viser de sortie particulière — est effectivement en $\mathcal{O}(n)$ pour tout formalisme, du plus simple au plus puissant. C’est la première ligne de la matrice de L17, uniformément verte.
Le problème, c’est que ce résultat est inutile. Une chaîne tirée au hasard est « grammaticale » (elle appartient au langage $L(G)$) mais ne dit rien. Personne ne génère au hasard. Un compositeur ne pose pas des notes aléatoires ; un système de dialogue ne répond pas par une phrase quelconque de la langue française. La génération réelle opère toujours sous contraintes : un sens à exprimer, une forme à respecter, un registre à tenir.
3. La génération sous contrainte change tout
Formalisons la contrainte. On ne demande plus « produis une chaîne quelconque de $L(G)$ », mais « produis une chaîne de $L(G)$ qui satisfait en plus une condition externe $C$ » — par exemple : « qui exprime ce sens précis », « qui contient exactement ces unités lexicales », « qui respecte ce format ».
Pour les langages réguliers ($k=3$ dans la hiérarchie de Chomsky — voir L1), tout va encore bien. La contrainte s’encode comme un second automate $A_C$, et générer revient à produire une chaîne dans l’intersection des deux langages, $L(G) \cap L(A_C)$ — calculable par produit d’automates en temps polynomial. Mohri (1997) montre que la sortie d’un transducteur déterministe reste linéaire en la taille de l’entrée. Pas de drame.
Le drame commence un cran plus haut, avec les grammaires context-free enrichies — celles qui portent des structures de traits (feature structures : des annotations attribut-valeur attachées aux constituants, pour exprimer l’accord sujet-verbe, le genre, le nombre, ou la sous-catégorisation d’un verbe). Ce sont les grammaires des linguistes : LFG, HPSG, FTAG. Et là, la complexité explose.
4. Le résultat de Kay (1996) : exponentiel
Martin Kay, l’un des fondateurs de la linguistique computationnelle, a établi que générer à partir d’une représentation sémantique « plate » est intrinsèquement exponentiel dans le pire cas. Sa formulation est limpide :
« The process is exponential in the worst case because, if a sentence contains a word with $k$ modifiers, then a version will be generated with each of the $2^k$ subsets of those modifiers, all but one of them being rejected when it is finally discovered that their semantics does not subsume the entire input. »
— Kay (1996, p. 202)
L’intuition : en parsing, la chaîne fournit un index positionnel — « entre la position 3 et la position 7, il y a un syntagme nominal ». Cet index est exactement ce qui rend le parsing polynomial (la programmation dynamique de CYK exploite les positions). En génération, la chaîne n’existe pas encore : c’est la sortie qu’on construit. Sans index positionnel, le générateur doit envisager tous les regroupements sémantiques compatibles — et il y en a un nombre exponentiel ($2^k$ pour $k$ modificateurs).
Décryptage — « subsume ». Une représentation sémantique en subsume une autre si elle la contient comme cas particulier. Le générateur ne sait qu’à la fin si le sous-ensemble de modificateurs qu’il a assemblé recouvre exactement le sens visé — d’où le gâchis : $2^k – 1$ tentatives jetées.
5. Le résultat de Brew (1992) : NP-complet, prouvé
L’analyse de Kay décrit une difficulté en pire cas. Chris Brew va plus loin : il démontre que le problème est NP-complet, sur un schéma minimal de génération à partir d’un sac (multi-ensemble) de signes lexicaux. La preuve passe par une réduction polynomiale depuis un problème NP-complet connu, le 3-Dimensional Matching :
« We now provide a polynomial-time reduction from an arbitrary instance of MENAGE A TROIS to an instance of Shake-and-Bake generation, which allows the same conclusion to be drawn for this problem. »
— Brew (1992, §2.1.3, p. 611)
Décryptage — réduction. Réduire un problème A à un problème B, c’est montrer que résoudre B permettrait de résoudre A. Si A est déjà connu pour être NP-complet (comme le 3-Dimensional Matching), alors B est au moins aussi difficile. La réduction de Brew transforme toute instance du 3-Dimensional Matching en une instance de génération : donc générer est NP-complet.
Pourquoi Brew est important au-delà de Kay ? Parce qu’il établit la difficulté intrinsèque — une propriété du problème lui-même, indépendante de l’algorithme — et non une simple lenteur en pire cas d’une méthode particulière. Sur un schéma dépouillé de toute machinerie auxiliaire, générer reste NP-complet.
Et en remontant encore la hiérarchie, vers les grammaires context-sensitive ($k=1$), Barton, Berwick & Ristad (1987) montrent que la décision d’appartenance pour des grammaires d’accord (CFG enrichies de traits limités) est déjà NP-complète par réduction depuis 3-SAT — ce qui se transfère à la génération sous contrainte.
6. Le renversement de signe
Mettons les deux côtés face à face. Côté reconnaissance, la complexité croît avec le pouvoir expressif de la grammaire : $\Theta(n)$ pour les réguliers, $\mathcal{O}(n^3)$ pour les context-free, et ainsi de suite (voir L17). Côté génération, libre ou simplement terminante, on reste polynomial partout. Jusqu’ici, le slogan tient.
Mais pour la génération sous contrainte sémantique, l’asymétrie change de signe dès $k=2$ avec traits : la génération devient exponentielle (Kay) ou NP-complète (Brew), tandis que la reconnaissance, elle, reste polynomiale ($\mathcal{O}(n^3)$). Autrement dit : pour la même classe de grammaire, générer dépasse parser.
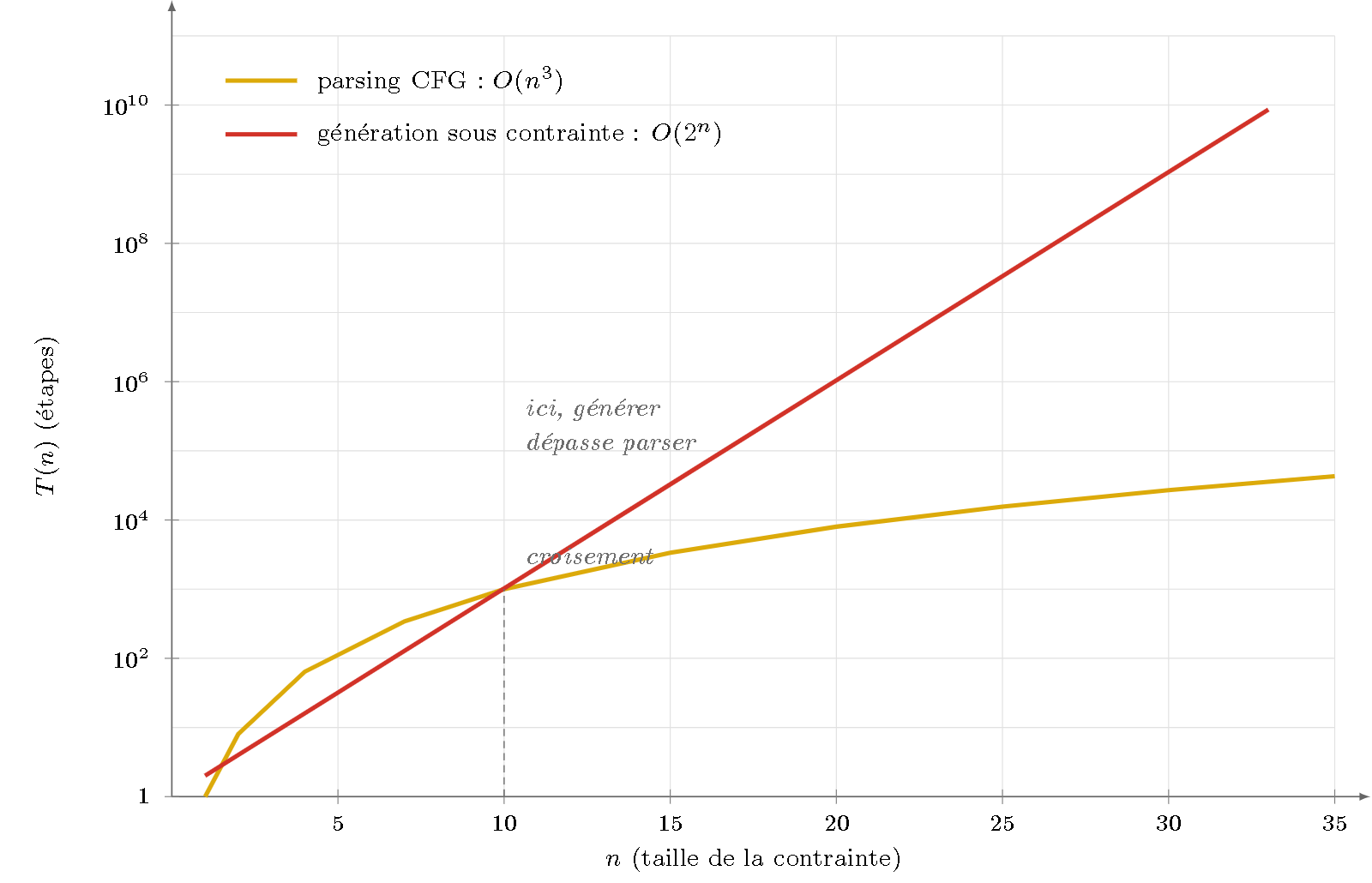
Figure 1 — Le renversement de signe (échelle semi-logarithmique). Pour les petites contraintes, la génération paraît plus rapide ; mais sa courbe exponentielle ($\mathcal{O}(2^n)$, rouge) croise puis dépasse la courbe polynomiale du parsing ($\mathcal{O}(n^3)$, jaune) autour de $n \approx 10$. Au-delà, générer sous contrainte coûte plus cher que parser — l’exact inverse du slogan.
7. La vraie asymétrie est structurelle
Si le slogan est faux, qu’est-ce qui est vrai ? L’asymétrie n’est pas un écart de difficulté entre deux opérations ; elle réside dans le locus de la contrainte :
- Le parser est toujours contraint : l’entrée lui est donnée, non négociable. Il n’a pas le choix de sa difficulté — elle lui est imposée par la chaîne reçue.
- Le générateur peut être contraint, ou non, selon la tâche. Sans contrainte, il jouit du $\mathcal{O}(n)$. Sous contrainte forte, il rejoint ou dépasse le parsing.
La fracture n’est donc pas « génération vs reconnaissance » mais « contrainte choisie vs contrainte subie ». C’est la formulation rigoureuse de l’intuition de L13 : le récepteur n’a pas le luxe du choix.
8. En musique et dans les grands modèles de langue
Le renversement se lit directement dans les systèmes réels.
En composition assistée : générer une mélodie quelconque dans une grammaire de style est trivial. Générer une mélodie qui module vers un ton cible, respecte une métrique imposée et cite un motif donné — c’est de la génération sous contraintes multiples, exactement le régime coûteux. Le compositeur qui utilise BP3 en mode production le ressent : plus il ajoute de garde-fous, plus l’espace de recherche se resserre et se complique.
Dans les grands modèles de langue (GPT et consorts) : l’échantillonnage autorégressif paraît instantané, en $\mathcal{O}(n)$ par jeton. Mais dès qu’on contraint la sortie — conformité de format (JSON valide), exactitude factuelle, filtres de sécurité —, on réintroduit le coût analytique. La génération contrainte des LLM matérialise le renversement de signe dans les architectures modernes : ce qui semblait gratuit redevient cher dès qu’on exige quelque chose de précis.
Ce qu’il faut retenir
- La génération non contrainte est triviale ($\mathcal{O}(n)$) mais inutile : personne ne génère au hasard.
- La génération sous contrainte sémantique peut être exponentielle (Kay 1996) ou NP-complète prouvée (Brew 1992, par réduction depuis le 3-Dimensional Matching).
- Le renversement de signe : pour une même grammaire, générer sous contrainte peut être strictement plus difficile que parser — l’inverse du slogan courant.
- La cause structurelle : sans la chaîne, le générateur n’a pas d’index positionnel et doit explorer un nombre exponentiel de recouvrements sémantiques.
- La vraie asymétrie n’est pas un écart de difficulté entre opérations, mais le locus de la contrainte : le parser la subit toujours, le générateur la choisit.
Pour aller plus loin
La génération contrainte
- Kay, M. (1996). « Chart Generation. » Proceedings of ACL, 200-204 — l’argument d’exponentialité.
- Brew, C. (1992). « Letting the Cat out of the Bag: Generation for Shake-and-Bake MT. » COLING 1992, 610-616 — la preuve de NP-complétude. DOI:10.3115/992133.992165
- Barton, G.E., Berwick, R.C. & Ristad, E.S. (1987). Computational Complexity and Natural Language. MIT Press — NP-complétude des grammaires d’accord (ch. 3).
- Mohri, M. (1997). « Finite-State Transducers in Language and Speech Processing. » Computational Linguistics 23(2), 269-311 — le cas régulier reste linéaire.
- Russell, G., Carroll, J. & Warwick-Armstrong, S. (1990). « Asymmetry in Parsing and Generating with Unification Grammars: Case Studies from ELU. » ACL 1990, 205-211 — études de cas (clitiques, têtes sémantiques vides). DOI:10.3115/981823.981849
L’article de recherche vulgarisé
- Peyrichou, R. (2026). The Generation-Recognition Asymmetry: Six Dimensions of a Fundamental Divide in Formal Language Theory. §4.1 développe le renversement de signe. Préprint arXiv:2603.10139 — https://arxiv.org/abs/2603.10139
Dans le corpus
- L13 — Vue d’ensemble de l’asymétrie (6 dimensions)
- L15 — Les formalisations mathématiques
- L17 — La matrice classe × tâche et le couplage différentiel
- L1 — Les classes de grammaires
- L9 — Les formalismes mildly context-sensitive
Glossaire
- Génération libre : appliquer les règles d’une grammaire sans viser de sortie particulière. Toujours $\mathcal{O}(n)$.
- Génération sous contrainte : produire une chaîne qui satisfait une condition externe $C$ (sens cible, format, occurrences lexicales). Peut être NP-complète dès les CFG enrichies de traits.
- Structure de traits (feature structure) : annotation attribut-valeur attachée à un constituant grammatical (accord, genre, nombre, sous-catégorisation).
- NP-complet : appartient à la classe des problèmes les plus difficiles parmi ceux dont une solution se vérifie en temps polynomial ; aucun algorithme polynomial connu, et il n’en existe vraisemblablement pas (sauf si $P = NP$).
- Réduction (polynomiale) : transformation, en temps polynomial, des instances d’un problème en instances d’un autre ; sert à transférer la difficulté.
- 3-Dimensional Matching : problème d’appariement à trois ensembles, NP-complet de référence, point de départ de la réduction de Brew.
- Index positionnel : information de position dans la chaîne d’entrée (« de la position $i$ à $j$ »), qui rend le parsing polynomial et fait défaut à la génération.
- Renversement de signe : le fait que, sous contrainte sémantique, l’asymétrie de difficulté s’inverse — la génération devient plus coûteuse que la reconnaissance.
Liens dans la série
- L13 — Générer ou reconnaître — l’asymétrie en 6 dimensions, dont la vision naïve (§1.3)
- L15 — Les formules de l’asymétrie — d’où viennent $\mathcal{O}(n^3)$ et les nombres de Catalan
- L17 — La matrice de complexité — la ligne « contrainte » que cet article approfondit
- L14 — La direction du parsing — pourquoi le parser a un degré de liberté
Prérequis : L13, L15, L17
Temps de lecture : 11 min
Tags : #asymétrie #génération-contrainte #NP-complétude #Kay #Brew #renversement-de-signe