L17) La matrice de complexité
[!info] Série « Asymétrie génération-reconnaissance »
Cet article accompagne l’article de recherche The Generation-Recognition Asymmetry: Six Dimensions of a Fundamental Divide in Formal Language Theory (📄 arXiv).
Fil de lecture : L13 · L14 · L15 · L16 · L17 · L18 · L19 · L20 — ou l’index complet.
Six sous-problèmes, deux axes, un renversement
Dans L15, nous avons posé l’écart de complexité comme un tableau simple : génération $\mathcal{O}(n)$, parsing $\mathcal{O}(n^\omega)$ ($\omega\approx2{,}37$ ; $O(n^3)$ avec CYK). Mais cette formulation réduit chaque opération à un seul nombre — et c’est trompeur. En réalité, « générer » et « analyser » recouvrent chacun trois sous-problèmes distincts, et la complexité de chacun dépend de deux axes orthogonaux : la classe de grammaire et la spécification de tâche. Quand on déplie tout, un mécanisme apparaît — le couplage différentiel — et, à un endroit précis, l’asymétrie change de signe.
Où se situe cet article ?
Cet article est l’approfondissement complet de la première dimension (D1, Complexité) de l’asymétrie génération-reconnaissance (L13, L15). C’est la vulgarisation fidèle de la section §4.1 de la publication : mêmes bornes, mêmes tableaux, mêmes figures, mais expliqués pas à pas.
Pourquoi c’est important ?
Dire « générer est facile, analyser est difficile » est un slogan, pas une explication. C’est même faux dans un cas précis : la génération sous contrainte sémantique peut être strictement plus difficile que le parsing (NP-complète, démontrée par Brew 1992 ; voir L18). Et le parsing des langages réguliers est aussi rapide que la génération (linéaire).
Ce qui est vrai, c’est que les deux opérations ne sont pas sensibles aux mêmes paramètres. La reconnaissance réagit au pouvoir expressif de la grammaire ; la génération réagit au degré de contrainte qu’on lui impose. Cette différence de sensibilité — le couplage différentiel — est le vrai mécanisme de l’asymétrie. Pour le voir, il faut d’abord arrêter de parler de « la » génération et de « la » reconnaissance comme de blocs monolithiques.
L’idée en une phrase
Génération et reconnaissance se décomposent chacune en trois sous-problèmes ; leur complexité est le produit de deux axes (classe de grammaire × spécification de tâche) ; et la sensibilité à ces axes est inversée — la reconnaissance suit la classe, la génération suit la tâche — au point que pour la génération contrainte, l’asymétrie s’inverse.
Expliquons pas à pas
1. Deux types de bornes, six sous-problèmes
Avant tout chiffre, deux mises au point.
Deux types de bornes. Une borne intrinsèque caractérise la difficulté du problème lui-même : aucun algorithme ne pourra faire mieux (sauf à renverser une conjecture de complexité réputée vraie, comme $\mathsf{P} \neq \mathsf{PSPACE}$). On la note souvent $\Theta(f(n))$ (borne « serrée », à la fois plancher et plafond) ou par une classe ($\mathsf{PSPACE}$-complet, indécidable). Une borne du meilleur algorithme connu est seulement le plafond qu’atteint le meilleur algorithme publié à ce jour — elle peut tomber demain. Cette distinction est cruciale : dire « le parsing CFG est en $O(n^3)$ » décrit l’algorithme CYK, pas la difficulté intrinsèque (qui est $O(n^\omega)$, et conjecturalement plus basse encore).
Six sous-problèmes. « Reconnaissance » et « génération » cachent chacune trois opérations de coûts très différents :
| Côté reconnaissance | Ce qu’on demande |
|---|---|
| Décision d’appartenance | La chaîne est-elle dans le langage ? (oui/non) |
| Construction d’un arbre | Produire une structure de dérivation |
| Énumération de tous les arbres | Lister toutes les structures valides |
| Côté génération | Ce qu’on demande |
|---|---|
| Génération libre | Appliquer des règles sans cible, s’arrêter quand on veut |
| Génération-exemple terminante | Produire une chaîne complète du langage |
| Génération sous contrainte sémantique | Produire une chaîne qui satisfait en plus une contrainte externe (un sens, un format) |
C’est en croisant ces six sous-problèmes avec les cinq classes de Chomsky ($k=3$ régulier, $k=2$ CFG, $k=2^+$ TAG/MCFG, $k=1$ context-sensitive, $k=0$ récursivement énumérable) qu’on obtient la vraie image.
2. Côté reconnaissance
Décision d’appartenance
C’est la borne de référence. Elle dépend fortement de la classe :
- Régulier ($k=3$) : temps linéaire $\Theta(n)$ avec un automate fini déterministe pré-compilé — il faut lire toute la chaîne, on ne peut pas faire moins. Borne intrinsèque serrée.
- CFG ($k=2$) : dans $\mathsf{P}$, mais la complexité exacte est un problème ouvert. CYK (Younger 1967) donne $O(n^3)$ ; Valiant (1975) ramène ça à $O(n^\omega)$ (réduction à la multiplication de matrices), soit $\approx O(n^{2{,}37})$ avec la meilleure valeur connue de $\omega$ (Williams et al. 2024). Lee (2002) montre la réciproque : parser plus vite que $n^3$, c’est multiplier des matrices plus vite. La difficulté du parsing CFG est donc conditionnellement équivalente à celle de la multiplication matricielle.
- TAG/MCFG ($k=2^+$) : dans $\mathsf{P}$, meilleure borne connue $O(n^6)$ (Joshi & Schabes 1997), conditionnellement serrée (Satta 1994 : faire mieux que $n^6$ améliorerait la multiplication booléenne).
- CSG ($k=1$) : PSPACE-complet (Kuroda 1964 + Savitch 1970 + Stockmeyer & Meyer 1973). Aucun algorithme polynomial en temps n’est connu ni vraisemblable ; la meilleure borne temps est $O(2^{n^2})$, pour une borne espace $O(n^2)$.
- RE ($k=0$) : indécidable (Turing 1936) — équivalent au problème de l’arrêt. Seulement semi-décidable.
Table 1 — Décision d’appartenance, par classe.
Classe Meilleur algorithme connu Caractérisation intrinsèque $k=3$ Régulier $\Theta(n)$ (DFA) serrée $\Theta(n)$ $k=2$ CFG $O(n^3)$ (CYK) ; $O(n^\omega)$, $\omega\le2{,}37$ (Valiant ; Williams 2024) dans $\mathsf{P}$, équiv. conditionnelle à la mult. matricielle $k=2^+$ TAG/MCFG $O(n^6)$ (Joshi & Schabes 1997) dans $\mathsf{P}$, conditionnellement serrée (Satta 1994) $k=1$ CSG $O(2^{n^2})$ temps, $O(n^2)$ espace PSPACE-complet (Kuroda ; Savitch ; Stockmeyer & Meyer) $k=0$ RE — indécidable (Turing 1936)
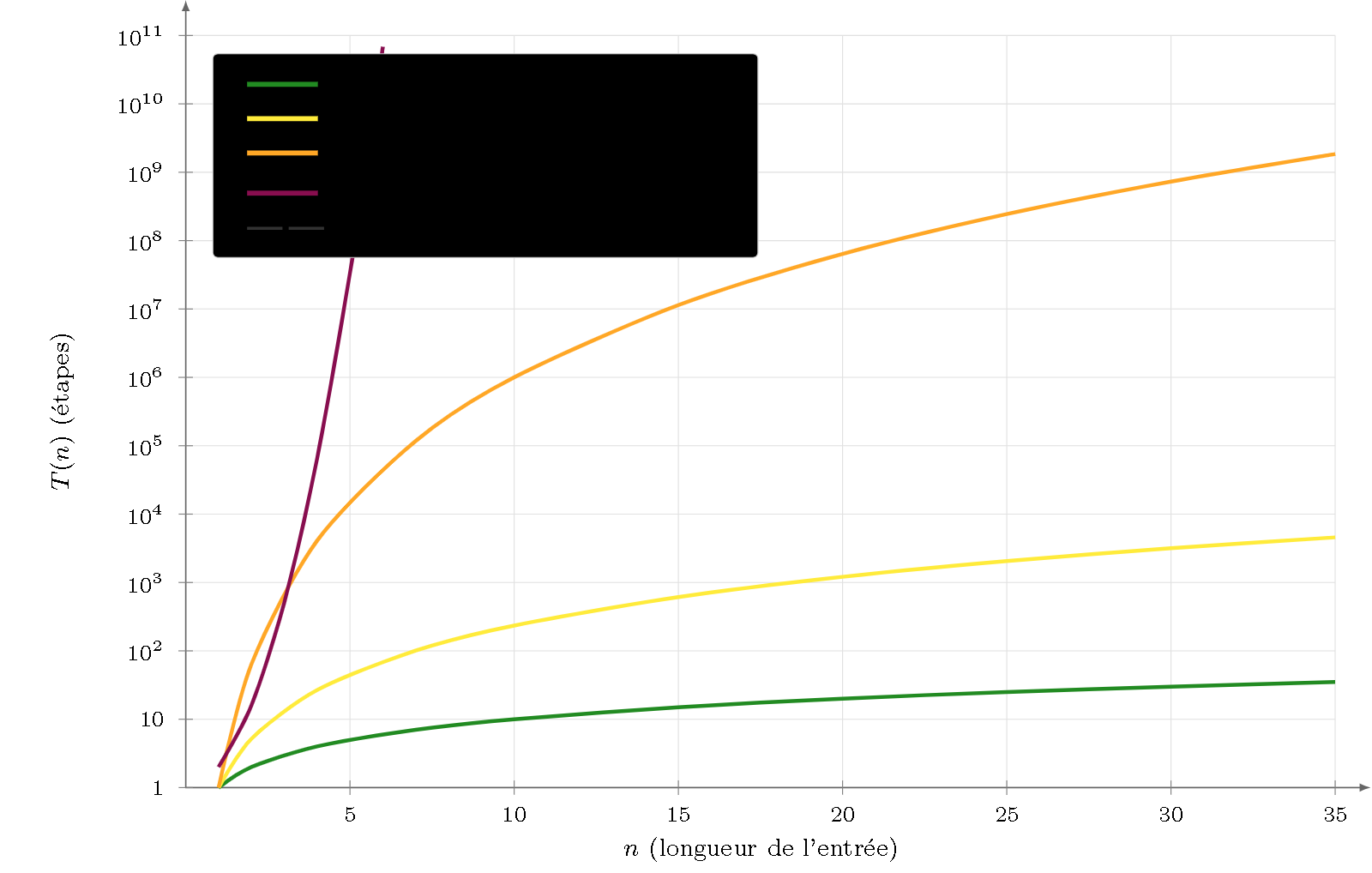
Figure 3 — Décision d’appartenance, échelle semi-logarithmique. Les bornes polynomiales ($k=3$ pente 1, $k=2$ pente 2,37, $k=2^+$ pente 6) sont des droites ; la borne exponentielle des CSG ($k=1$) diverge dès $n\approx6$. L’indécidabilité ($k=0$) n’est pas représentable sur l’axe.
Construction d’un arbre
Une fois l’appartenance décidée, produire un arbre témoin ne coûte qu’un facteur constant de plus que la décision, à tous les niveaux : les algorithmes de décision gardent une table de pointeurs (le chart) qu’il suffit de parcourir à rebours pour reconstruire l’arbre en $O(n)$ supplémentaire. Subtilité : si la chaîne est ambiguë (plusieurs arbres valides), produire un arbre exige un choix arbitraire — mais le coût asymptotique ne change pas.
Énumération de tous les arbres
Ici, le problème change de nature : il faut tout lister, donc le coût est borné par la sortie.
- Régulier : un seul arbre par chaîne → $O(n)$.
- CFG : le nombre d’arbres d’une chaîne ambiguë suit les nombres de Catalan, $C_n \sim 4^n/n^{3/2}\sqrt\pi$ — exponentiel. (Une phrase à $k$ syntagmes prépositionnels admet $C_k$ attachements : $C_3=5$, $C_4=14$, $C_{10}=16\,796$.) Billot & Lang (1989) compactent l’ensemble en une forêt partagée en $O(n^3)$ espace, mais extraire explicitement les arbres reste $O(4^n)$.
- TAG/MCFG : analogue, $O(4^n)$ ou pire ; forêt partagée en $O(n^6)$.
- CSG : $O(2^{n^2})$, comme la décision.
- RE : indécidable, et le nombre d’arbres peut être infini.
Table 2 — Énumération de tous les arbres.
Classe Énumération explicite Représentation compacte $k=3$ $O(n)$ $O(n)$ (un seul arbre) $k=2$ $O(4^n)$ (Catalan) $O(n^3)$ forêt partagée (Billot & Lang) $k=2^+$ $O(4^n)$ ou pire $O(n^6)$ forêt partagée $k=1$ $O(2^{n^2})$ — (même borne) $k=0$ indécidable / infini —
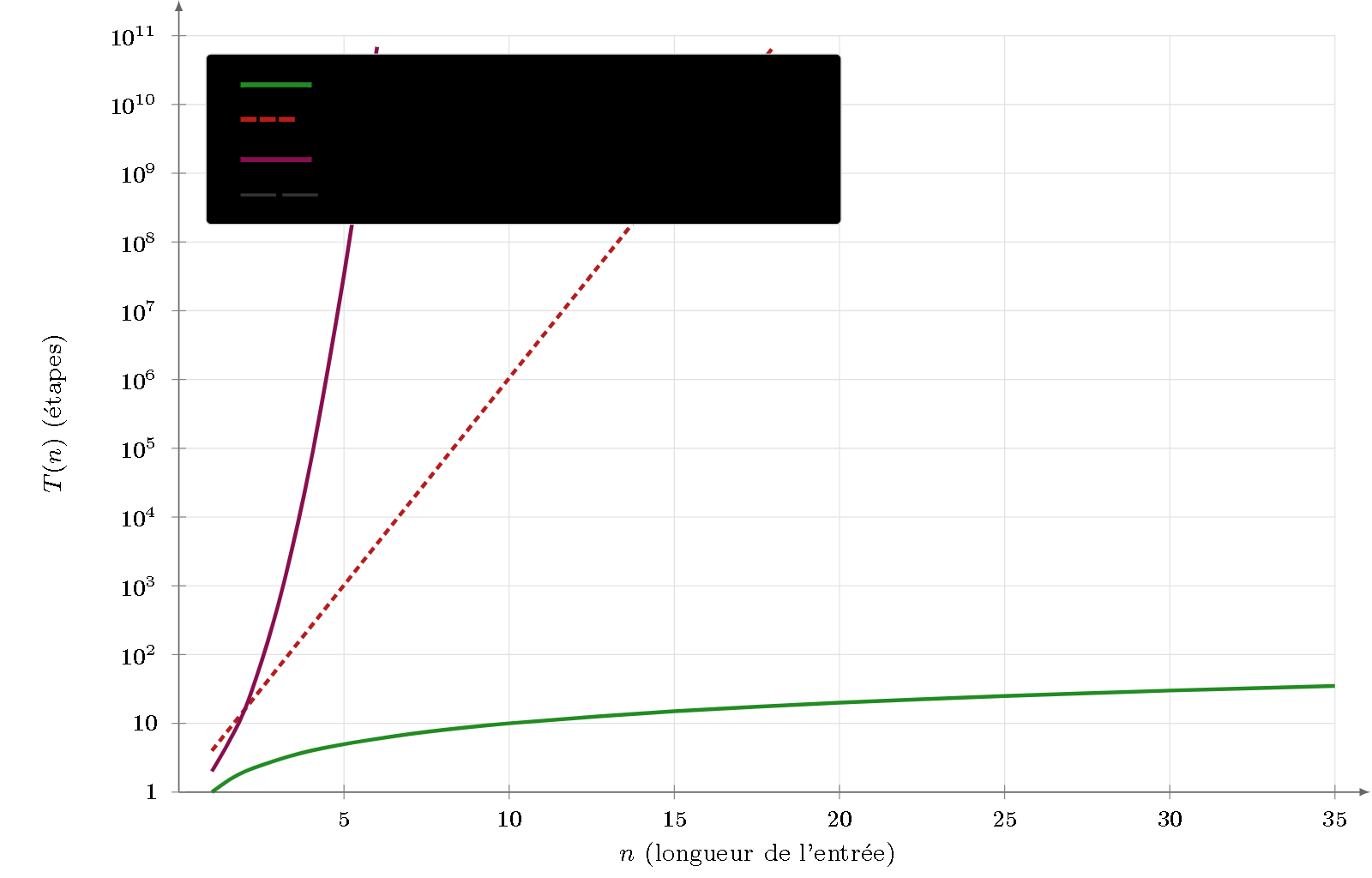
Figure 4 — Énumération explicite de tous les arbres. À comparer à la Figure 3 : pour $k=3$ la courbe est identique (un arbre par chaîne), mais dès $k=2$ la borne $O(4^n)$ (Catalan) diverge bien plus vite que le $O(n^{2,37})$ de la décision. C’est la « seconde dimension de difficulté » : l’explosion combinatoire du nombre d’arbres à produire.
3. Côté génération
Génération libre
Appliquer les règles sans cible, en comptant les étapes de dérivation : c’est $\mathcal{O}(n)$ à toutes les classes monotones ($k=3$ à $k=1$) — même une grammaire de Turing dérive librement en temps linéaire. La génération libre est immunisée contre la montée dans la hiérarchie. (Pour $k=0$ non monotone, la dérivation peut ne pas terminer.)
Génération-exemple terminante
Produire une chaîne complète du langage. Le coût reste polynomial partout où la dérivation termine :
- Régulier : $\Theta(n)$.
- CFG : $O(n)$ à $O(n^2)$.
- TAG/MCFG : $O(n^2)$ à $O(n^3)$.
- CSG : $O(n^3)$ — polynomial, alors que la décision CSG est PSPACE-complète. C’est la première manifestation forte de l’asymétrie en faveur de la génération.
Table 3 — Génération-exemple terminante.
Classe Coût total Caractérisation $k=3$ $\Theta(n)$ identique à la décision $k=2$ $O(n)$ à $O(n^2)$ dans $\mathsf{P}$ $k=2^+$ $O(n^2)$ à $O(n^3)$ dans $\mathsf{P}$ $k=1$ $O(n^3)$ dans $\mathsf{P}$ — contraste fort avec la décision PSPACE-complète $k=0$ non bornée semi-décidable
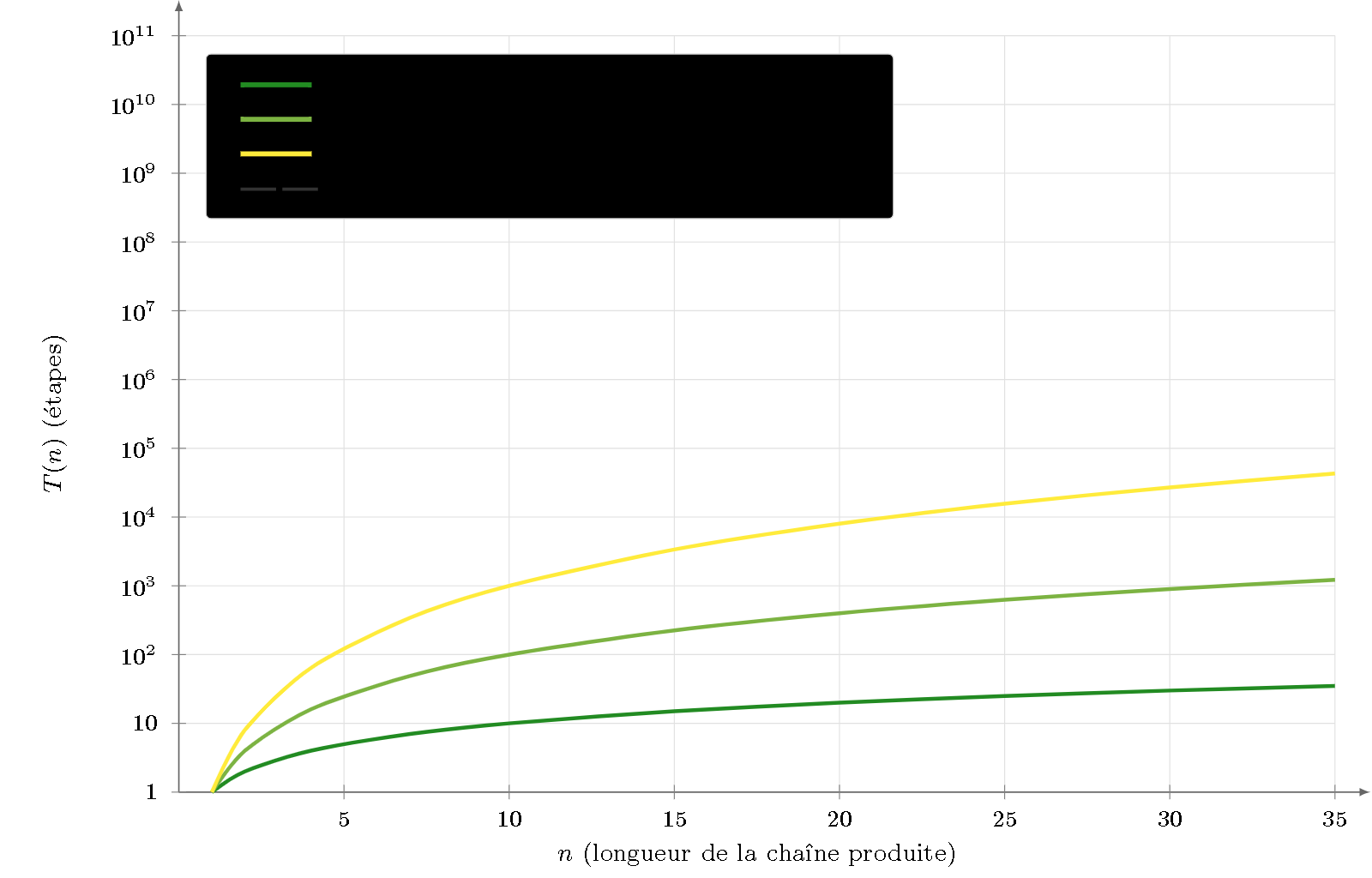
Figure 5 — Génération-exemple terminante. Tout reste polynomial (pentes 1, 2, 3) pour les classes monotones. À comparer à la Figure 3 : la génération est strictement plus rapide que la décision pour $k=2^+$ et $k=1$, et l’écart devient qualitatif à $k=1$ (polynomial vs PSPACE-complet).
Génération sous contrainte sémantique
Ici, la chaîne produite doit en plus satisfaire une contrainte externe (un sens cible, un format). Et le profil change radicalement :
- Régulier : reste polynomial (intersection d’automates, Mohri 1997).
- CFG pure : polynomial si la sémantique est compositionnelle. Mais avec des structures de traits / unification (le cas standard des grammaires linguistiques : LFG, HPSG), Kay (1996) montre que c’est exponentiel : un mot à $k$ modifieurs engendre $2^k$ candidats. Brew (1992) démontre formellement la NP-complétude (réduction depuis 3-Dimensional Matching) sur un schéma minimal.
- TAG/MCFG : héritage de l’argument exponentiel.
- CSG : NP-hard à PSPACE-hard (Barton et al. 1987).
- RE : indécidable.
Table 4 — Génération sous contrainte sémantique.
Classe Borne Source $k=3$ Régulier polynomial Mohri 1997 $k=2$ CFG pure polynomial folklore $k=2$ CFG + traits exponentielle ($2^k$) Kay 1996 $k=2$ CFG + multi-set NP-complète (prouvée) Brew 1992 $k=2^+$ TAG + traits exponentielle Kay/Brew $k=1$ CSG + traits NP-hard à PSPACE-hard Barton 1987 $k=0$ RE indécidable Turing 1936
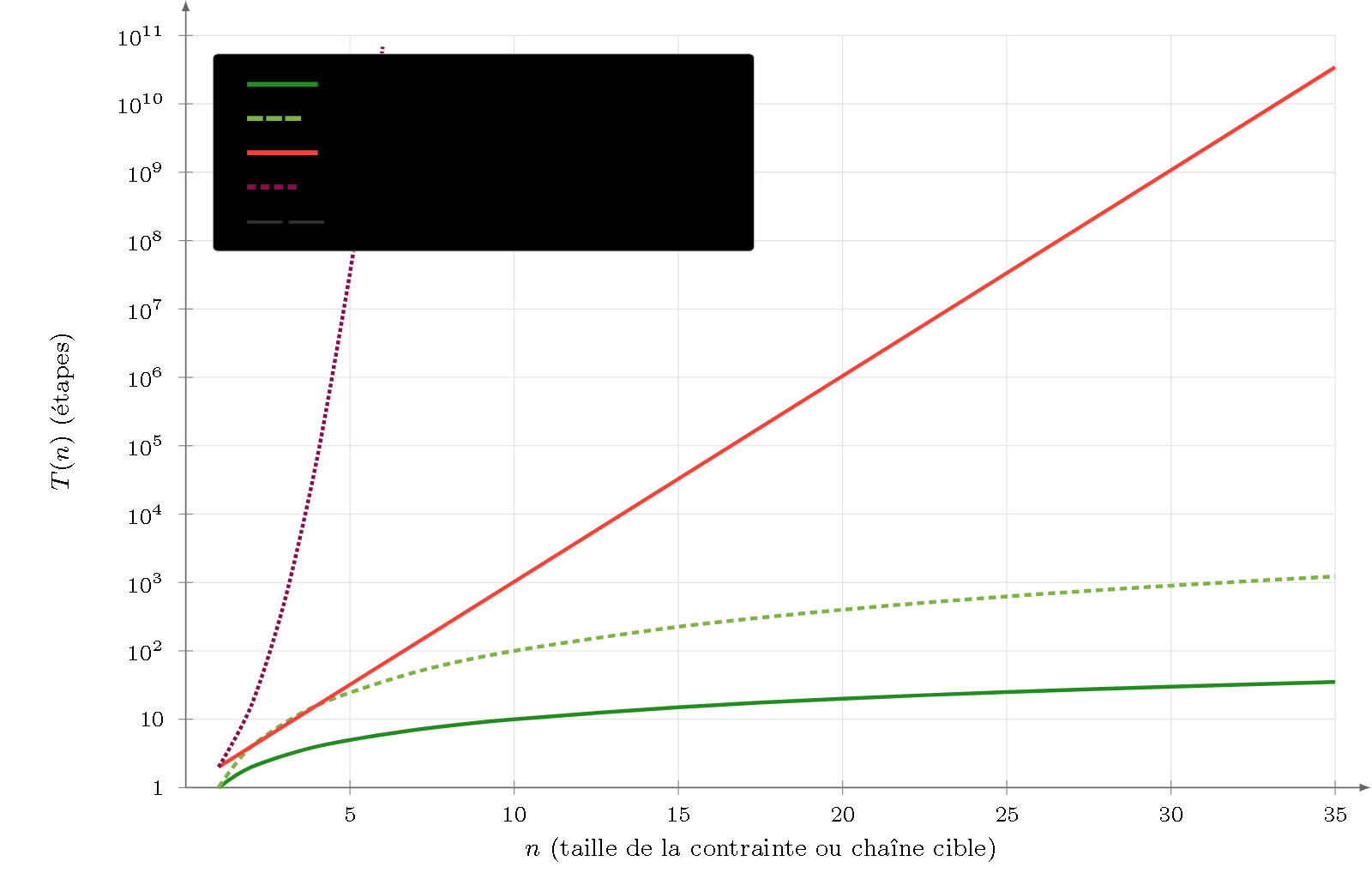
Figure 6 — Génération sous contrainte sémantique. Polynomiale pour le régulier et les CFG pures, mais l’ajout de traits fait basculer la complexité en exponentielle dès $k=2$ (NP-complète, Brew 1992). À comparer à la Figure 3 : ici la génération dépasse la décision dès $k=2$ — la manifestation visuelle du renversement de signe.
4. Le renversement de signe
Mettons les trois sous-problèmes de génération côte à côte avec la reconnaissance :
- Génération libre et génération-exemple : polynomiales jusqu’à $k=1$ inclus. Ici, « générer est facile » est vrai.
- Génération sous contrainte sémantique : NP-complète dès $k=2$ (avec traits), alors que la décision d’appartenance reste polynomiale jusqu’à $k=2^+$.
Autrement dit : pour la génération contrainte, l’asymétrie s’inverse — générer devient plus dur qu’analyser. Ce n’est pas une vue de l’esprit : Brew (1992) le prouve formellement. Le slogan « generation is easy, parsing is hard » est donc faux en général : l’asymétrie change de nature selon le sous-problème, pas seulement selon la classe. (Ce renversement se matérialise aujourd’hui dans les LLM contraints en format ou en factualité — voir L18.)
5. Synthèse : le couplage différentiel
On peut maintenant comparer les deux côtés. La Table 5 confronte les deux cas focaux les plus contrastés :
Table 5 — Décision d’appartenance vs génération-exemple terminante.
Classe Décision d’appartenance Génération-exemple Écart $k=3$ $\Theta(n)$ $O(n)$ nul $k=2$ $O(n^3)$ → $O(n^{2{,}37})$ $O(n)$ à $O(n^2)$ polynomial $k=2^+$ $O(n^6)$ $O(n^2)$ à $O(n^3)$ polynomial ($n^3$ à $n^4$) $k=1$ PSPACE-complet $O(n^3)$ séparation $\mathsf{P}$ vs $\mathsf{PSPACE}$ $k=0$ indécidable non bornée séparation de la décidabilité
Et les deux heatmaps (Figure 7) déploient les six sous-problèmes complets. C’est là que le couplage différentiel saute aux yeux : la matrice de génération varie surtout selon les lignes (sensible au sous-problème), celle de reconnaissance surtout selon les colonnes (sensible à la classe).
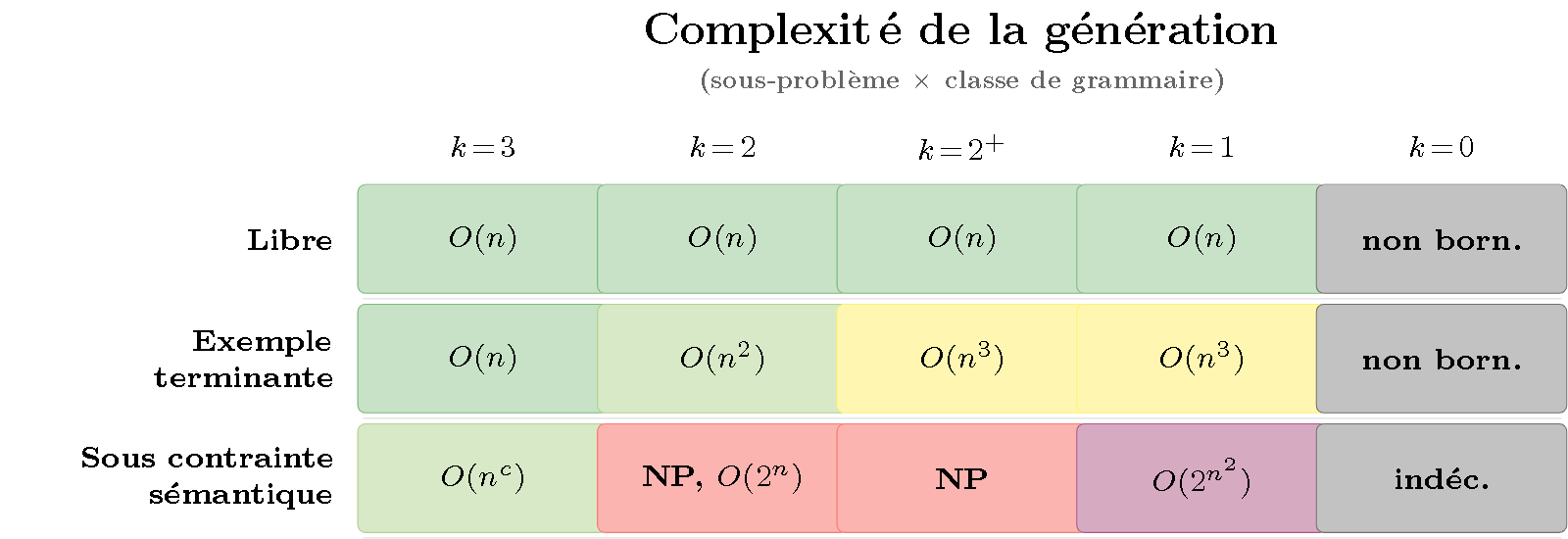

Figure 7 — Les deux heatmaps : génération (haut) et reconnaissance (bas). Lignes = les trois sous-problèmes de chaque côté ; colonnes = les cinq classes de Chomsky. La génération (haut) varie surtout selon les lignes (libre → terminante → contrainte) : elle est sensible au sous-problème. La reconnaissance (bas) varie surtout selon les colonnes : elle est sensible à la classe — sauf la ligne « tous les arbres », qui explose aussi avec la classe (Catalan). C’est le couplage différentiel.
Ce que ça veut dire concrètement :
- Augmenter le pouvoir expressif de la grammaire pénalise le parsing, mais laisse la génération libre intacte.
- Augmenter les contraintes sur la sortie pénalise la génération, mais pas le parsing (qui est toujours contraint par son entrée).
C’est la formalisation de l’intuition de L13 : le parser est toujours contraint (l’entrée est donnée, non négociable), tandis que le générateur peut ou non se contraindre.
6. Exemple musical suivi + un contre-argument honnête
Exemple suivi. Pour une grammaire musicale de niveau $k=2^+$ (typique des grammaires de structure polyphonique), reconnaître une partition de longueur $n$ coûte au pire $O(n^6)$, alors que générer un extrait arbitraire demande $O(n^2)$ à $O(n^3)$. Pour 100 mesures ($n\approx100$), l’écart est de $10^6$ à $10^8$ — significatif mais traitable. Si l’on ajoutait des contraintes globales arbitraires (passage à $k=1$), la reconnaissance deviendrait PSPACE-complète : plus aucun algorithme polynomial pour décider qu’un extrait appartient au langage.
Contre-argument. « Mais pour les CFG, l’écart n’est que $n^{0,37}$ si on retient Valiant, et il disparaît pour les sous-classes LL/LR qui parsent en $O(n)$. » C’est exact — et instructif.
Résolution. Cela illustre pourquoi il faut distinguer borne intrinsèque et meilleur algorithme connu. La borne $O(n^\omega)$ des CFG est conditionnelle à la conjecture sur $\omega$ ; si l’on prouvait $\omega=2$, l’asymétrie CFG s’effondrerait. Pour les sous-classes LL/LR, l’écart disparaît bien — ce qui confirme que D1 dépend de la classe précise, pas seulement du niveau $k$. Mais la séparation $\mathsf{P}$ vs $\mathsf{PSPACE}$ (CSG) et décidable vs indécidable (RE) ne dépendent, elles, d’aucune hypothèse algorithmique : elles sont intrinsèques.
7. En musique
Le couplage différentiel s’observe directement dans les systèmes musicaux :
- BP3 en mode PROD (I2) : génération libre — rapide quel que soit le pouvoir expressif des règles (première ligne de la heatmap génération, tout vert).
- BP3 en mode ANAL : la même grammaire analyse — la complexité dépend maintenant de la classe des règles (heatmap reconnaissance, sensible aux colonnes).
- GTTM (M6) : pur parsing analytique avec règles sensibles au contexte → colonnes droites de la matrice de reconnaissance.
- Génération neuronale contrainte (format, factualité) : illustration moderne du renversement de signe — générer sous contrainte redevient coûteux.
La matrice explique pourquoi les systèmes musicaux sont majoritairement unidirectionnels (L16) : pour une même grammaire, les deux directions ont des profils de performance radicalement différents.
Ce qu’il faut retenir
- « Génération » et « reconnaissance » cachent six sous-problèmes de coûts très différents — il faut les séparer avant tout chiffre.
- Toujours distinguer borne intrinsèque (la difficulté du problème) et meilleur algorithme connu (qui peut tomber). Le parsing CFG est $O(n^3)$ avec CYK, mais $O(n^\omega)$ intrinsèquement.
- Reconnaissance : décision et un-arbre suivent la classe ($\Theta(n)$ → $O(n^\omega)$ → $O(n^6)$ → PSPACE-c → indéc.) ; tous les arbres explose en $O(4^n)$ (Catalan).
- Génération : libre et terminante restent polynomiales partout où la dérivation termine — y compris à $k=1$, où la décision est pourtant PSPACE-complète.
- Renversement de signe : la génération sous contrainte sémantique devient NP-complète dès $k=2$ (Brew 1992) — plus dure que la reconnaissance. Le slogan « générer est facile » est faux.
- Couplage différentiel : reconnaissance ← sensible à la classe ; génération ← sensible au sous-problème. C’est le vrai mécanisme de l’asymétrie.
Pour aller plus loin
Complexité computationnelle
- Younger, D.H. (1967). « Recognition and Parsing of Context-Free Languages in Time $n^3$. » Information and Control, 10(2), 189–208 — CYK.
- Valiant, L.G. (1975). « General Context-Free Recognition in Less than Cubic Time. » JCSS, 10(2), 308–315 — réduction à la multiplication matricielle.
- Williams, V.V. et al. (2024). « New Bounds for Matrix Multiplication. » — $\omega \le 2{,}371552$.
- Satta, G. (1994). « Tree-Adjoining Grammar Parsing and Boolean Matrix Multiplication. » Computational Linguistics — $O(n^6)$ pour TAG.
- Savitch, W.J. (1970). « Relationships Between Nondeterministic and Deterministic Tape Complexities. » JCSS — CSL ⊆ DSPACE($n^2$).
- Kuroda, S.-Y. (1964). « Classes of Languages and Linear-Bounded Automata. » Information and Control — CSL = NLBA.
- Hopcroft, J.E., Motwani, R. & Ullman, J.D. (2006). Introduction to Automata Theory. Addison-Wesley.
Génération contrainte
- Kay, M. (1996). « Chart Generation. » ACL — génération exponentielle avec traits.
- Brew, C. (1992). « Letting the Cat Out of the Bag: Generation for Shake-and-Bake MT. » COLING — NP-complétude prouvée.
- Barton, G.E., Berwick, R.C. & Ristad, E.S. (1987). Computational Complexity and Natural Language. MIT Press.
- Mohri, M. (1997). « Finite-State Transducers in Language and Speech Processing. » Computational Linguistics — sortie linéaire des transducteurs.
Ambiguïté
- Billot, S. & Lang, B. (1989). « The Structure of Shared Forests in Ambiguous Parsing. » ACL — forêts partagées en $O(n^3)$.
Dans le corpus
- L1 — Les niveaux et leurs automates
- L9 — Type 2+ : TAG, CCG, MCFG
- L13 — Vue d’ensemble de l’asymétrie (6 dimensions)
- L15 — Les formalisations mathématiques
- L16 — Pourquoi la bidirectionnalité n’a pas été transférée
- L18 — Le renversement de signe : quand générer dépasse parser
- M6 — GTTM : le paradigme analytique appliqué
Glossaire
- Borne intrinsèque : caractérisation de la difficulté du problème lui-même ($\Theta(f)$ ou classe de complexité), qu’aucun algorithme ne peut battre sauf à renverser une conjecture.
- Borne du meilleur algorithme connu : plafond atteint par le meilleur algorithme publié à ce jour ; peut être amélioré.
- Couplage différentiel : génération et reconnaissance sont sensibles aux deux axes (classe × sous-problème), mais avec une sensibilité principale inversée.
- Décision d’appartenance : déterminer si une chaîne appartient au langage (oui/non) — la borne de référence côté reconnaissance.
- Génération sous contrainte sémantique : produire une chaîne qui satisfait en plus une contrainte externe. NP-complète dès $k=2$ avec traits (Brew 1992).
- Nombres de Catalan : $C_n \sim 4^n/n^{3/2}\sqrt\pi$ — comptent les arbres de dérivation d’une chaîne CFG ambiguë.
- PSPACE-complet : résoluble en espace polynomial, mais sans algorithme en temps polynomial connu ni vraisemblable. La décision d’appartenance des CSG l’est.
- Renversement de signe : pour la génération contrainte, l’asymétrie s’inverse — générer devient plus dur qu’analyser.
- $\omega$ : exposant de la multiplication matricielle, $\le 2{,}371552$ (Williams et al. 2024). Borne le parsing CFG via Valiant.
Prérequis : L1, L13, L15
Temps de lecture : 18 min
Tags : #complexité #asymétrie #heatmap #couplage-différentiel #Chomsky #matrice #renversement-de-signe