L21) L’économie de la paresse et l’oracle écologique
[!info] Note de lecture
Cet article est une essai qui développe une thèse. Il assemble des éléments connues (théorie de l’information, apprentissage des grammaires, psycholinguistique) en un cadre cohérent. Si une affirmation est une hypothèse, c’est spécifié. Prérequis utile : L20 (l’inférence et le mur de Gold).
Comment apprend-on une grammaire ?
Générer une phrase, en reconnaître la structure, inférer la grammaire à partir d’exemples, et apprendre cette grammaire ne sont pas quatre opérations séparées. Ce sont des points d’un même processus, mû par l’erreur de prédiction, payé en compression, et alimenté par une économie de la paresse.
C’est la thèse de cet article. Elle ne prétend pas à un mécanisme nouveau — chacune de ses pièces existe déjà dans la littérature. Sa proposition est un cadrage : montrer que ces pièces, mises ensemble, décrivent un seul système cohérent. Déballons-le terme par terme.
Un repère, d’abord, hérité de L20 : le gradient de connaissance $\kappa$ (kappa). C’est la quantité de connaissance grammaticale dont dispose celui qui analyse. À $\kappa = 1$, la grammaire est entièrement connue : c’est la reconnaissance (vérifier qu’une phrase appartient au langage). À $\kappa = 0$, on ne connaît rien : c’est l’inférence pure (deviner la grammaire à partir d’exemples seuls). Entre les deux, un continuum. Apprendre, c’est se déplacer le long de cet axe, de $\kappa$ bas vers $\kappa$ haut.
Les paresses : une économie de l’effort
La thèse repose sur une dissymétrie féconde entre deux acteurs : celui qui émet (le locuteur, le générateur) et celui qui reçoit et apprend (l’auditeur, l’analyste). Tous deux sont paresseux — mais il y a en réalité plusieurs paresses, dont certaines se complètent et d’autres s’opposent.
La paresse du locuteur : en dire le moins possible
Un locuteur efficace ne transmet pas tout. Il sous-spécifie : il omet ce que l’auditeur peut reconstruire, il laisse des ambiguïtés, il abrège. Umberto Eco a donné à cette idée une image durable, le meccanismo pigro — le texte paresseux qui exige la coopération inférentielle du lecteur pour combler ses blancs (Lector in Fabula, 1979). Important : chez Eco, cette paresse relève d’une communication voulue — l’auteur omet intentionnellement, en pariant sur le lecteur. On garde ici Eco comme inspiration, pas comme preuve.
Sous l’image, un phénomène mesurable : comprimer à la source. Réduire le nombre de signifiants pour un même signifié, c’est dépenser moins d’effort à produire et à transmettre. La théorie qui décrit exactement ce compromis est la théorie débit-distorsion de Shannon (Coding theorems for a discrete source with a fidelity criterion, 1959) : combien de bits faut-il, au minimum, pour transmettre un message à une fidélité donnée ? Moins on tolère de pertes, plus il faut de bits ; accepter un peu de perte permet de comprimer davantage.
Une analogie informatique éclaire l’enjeu. Transmettre un message sans code de détection d’erreur (les CRC, cyclic redundancy checks, ces bits redondants qui signalent une corruption) coûte moins cher — moins de bits, moins d’effort de transcodage — mais c’est plus risqué : si le canal est bruité, ou si le récepteur n’a pas le modèle pour reconstruire, l’erreur passe inaperçue. Retirer la redondance, c’est arbitrer compression contre robustesse.
Et le coût qu’on cherche à réduire — l’effort, l’énergie — dépend du milieu. La vitesse de transmission des neurones n’a rien à voir avec la densité de l’air : produire un geste articulatoire, propager une onde acoustique, décoder un signal nerveux ne coûtent pas la même chose. L’optimum de paresse se forme là où le goulot est le plus coûteux. Conséquence directe, et c’est un point propre à cette thèse :
Le taux de compression efficace — combien de signifiants pour un signifié — n’est pas fixe. Il dépend du milieu (le coût énergétique du canal) et de la connaissance partagée entre l’émetteur et le récepteur.
Et — paradoxe apparent — c’est aussi au goulot, là où le canal est le plus coûteux, que se concentre le plus d’incertitude : comprimer fort, c’est laisser le plus à reconstruire. Le système n’y répond pas en blindant (en rajoutant de la redondance) mais en s’appuyant sur la connaissance partagée ; là où celle-ci manque, l’incertitude résiduelle fait surface comme erreur. Le goulot le plus coûteux est donc aussi le lieu de plus forte surprise — donc, on le verra, de plus fort apprentissage. Ce n’est pas une contradiction mais une conséquence de la débit-distorsion : à canal coûteux, on accepte davantage de perte. L’économie d’énergie et la friction d’apprentissage se logent au même endroit.
Plus le récepteur partage la grammaire, plus le locuteur peut être paresseux : le récepteur reconstruit les bits omis avec son propre modèle. On l’observe partout — le jargon entre experts, l’ellipse entre proches, les codes d’un groupe : autant de connaissance partagée qui autorise une compression extrême. Face à un novice, on « rajoute du CRC » : on explicite. Que les langues elles-mêmes soient sculptées par cette pression d’efficacité — un compromis entre effort du locuteur et besoin de l’auditeur — est aujourd’hui un résultat documenté (Gibson et al., How Efficiency Shapes Human Language, 2019 ; Zaslavsky et al., 2018, montrent que les systèmes de dénomination atteignent une compression quasi-optimale au sens de la théorie de l’information).
Les trois paresses du récepteur
Côté réception, la paresse n’est pas unique : il y en a trois, qui ne tirent pas dans le même sens.
- Paresse de représentation — ne pas porter d’information inutile. Le récepteur retient le pertinent et jette le reste : c’est le goulot d’information (information bottleneck, Tishby), comprimer l’entrée en ne gardant que ce qui informe sur ce qui compte.
- Paresse de modèle — préférer la grammaire la plus simple parmi celles compatibles avec les exemples. C’est le rasoir d’Occam, quantifié par le MDL (Minimum Description Length, longueur de description minimale ; Rissanen, 1978 ; Grünwald, 2007) : minimiser (taille du modèle) + (données encodées par lui). « Apprendre, c’est compresser », radicalisé par Chaitin (2005).
- Paresse de traitement — éviter l’effort de mise à jour : décoder avec le modèle courant, ne pas payer pour apprendre. Contrairement aux deux autres, celle-ci s’oppose à l’apprentissage (on y revient plus bas).
Les deux premières orientent l’apprentissage (elles le bornent : représentation compacte, modèle simple) ; la troisième lui résiste.
La paresse commune : ne pas recommencer
Une dernière paresse est partagée par les deux acteurs : ne pas avoir à recommencer. Payer une fois, réutiliser ensuite. C’est elle qui pousse vers des routines stables (les « routines de dialogue » de Pickering & Garrod), des habitudes, une grammaire partagée qu’on ne renégocie pas. Et c’est elle qui fait céder la paresse de traitement : on accepte l’effort d’apprendre maintenant précisément pour ne pas refaire toujours. Apprendre est un investissement de paresse.
Trois compressions, trois objets
Plusieurs de ces paresses sont des compressions — mais elles ne portent pas sur le même objet, et il ne faut pas les conflater (les fondre en une) : Shannon-canal comprime le message (transmettre à moindre coût — communication) ; le goulot d’information comprime la représentation (jeter l’inutile) ; MDL comprime le modèle (quelle grammaire est la meilleure — inférence). Même mot, trois questions.
La carte des paresses
Mise à plat, l’« économie de la paresse » compte cinq forces :
| # | Acteur | Paresse | Sur quoi | Cadre formel |
|---|---|---|---|---|
| 1 | locuteur | production — en dire le moins | le message | débit-distorsion (Shannon) |
| 2 | récepteur | représentation — jeter l’inutile | l’entrée | goulot d’information (Tishby) |
| 3 | récepteur | modèle — rester simple | le modèle | MDL / Occam |
| 4 | récepteur | traitement — éviter l’effort | l’acte d’apprendre | (résiste à l’apprentissage) |
| 5 | commun | réitération — ne pas recommencer | le futur | amortissement, routines |
Et voici où chacune agit, une fois distingués les deux acteurs, leurs systèmes internes et les transactions entre eux :
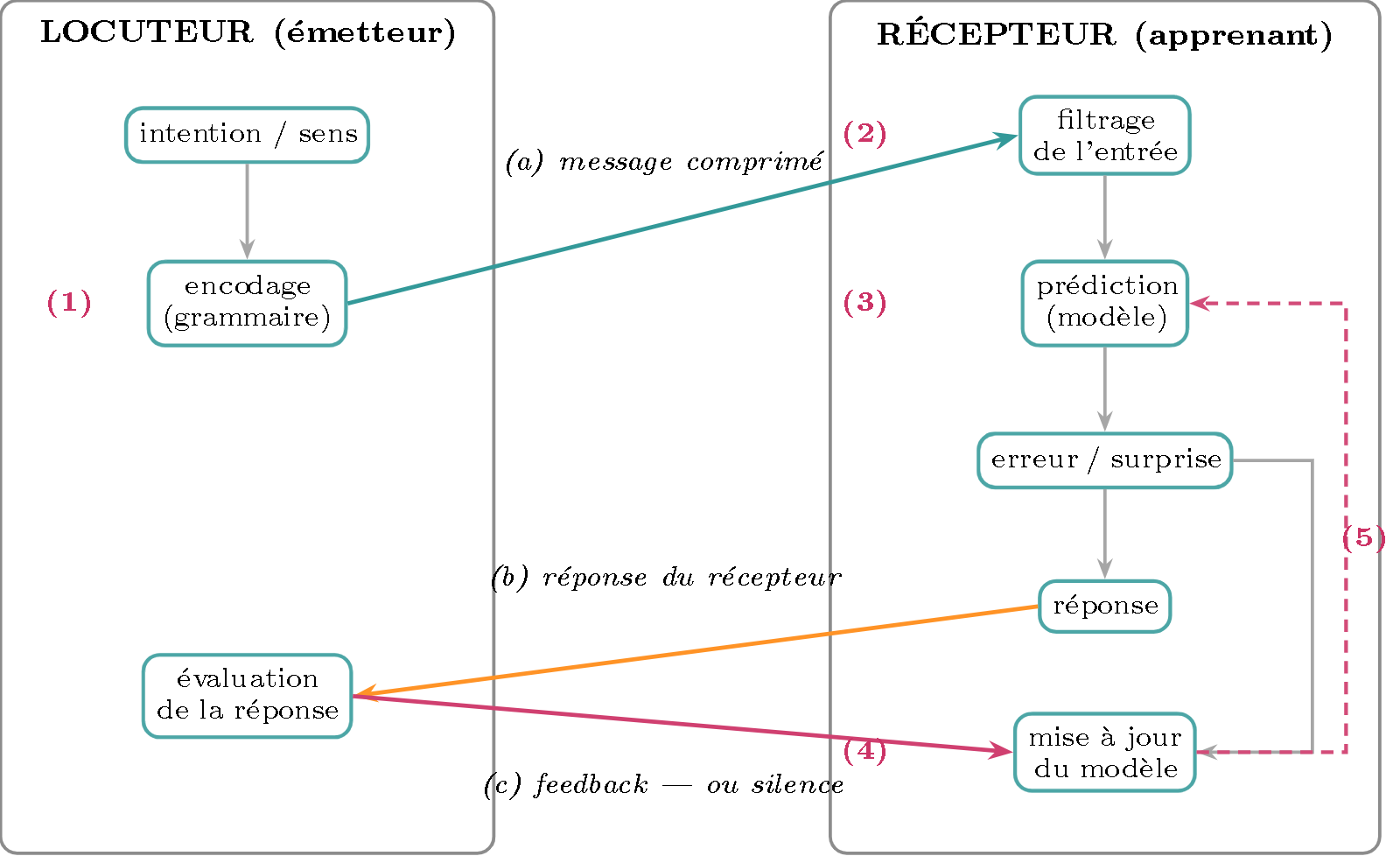
Figure 1 — Où agit chaque paresse. Deux acteurs (boîtes), leurs systèmes internes, et les transactions entre eux. Les numéros renvoient au tableau : (1) à l’encodage du locuteur, (2) au filtrage de l’entrée, (3) sur le modèle, (4) sur la mise à jour, (5) sur la réutilisation du modèle d’un épisode à l’autre (partagée aussi avec l’encodage du locuteur).
→ La paresse n’est donc pas un bloc mais un système de forces : une crée l’erreur (1), deux orientent l’apprentissage (2, 3), une lui résiste (4), une l’amortit dans le temps (5). C’est leur jeu qui fixe le taux d’erreur réel — et, on le verra, le taux optimal.
Le moteur : l’erreur de prédiction
Qu’est-ce qui fait tourner ce système ? L’erreur de prédiction. En psycholinguistique, la P-chain de Dell & Chang (2014) résume le principe : prediction error drives learning — on prédit en permanence ce qui va venir, et l’écart entre prédiction et réalité est le signal qui met à jour le modèle. C’est aussi le cœur du codage prédictif en neurosciences (Friston, The free-energy principle, 2010) : percevoir, agir et apprendre reviennent à minimiser la surprise.
Encore faut-il pouvoir mesurer la surprise quand on ne connaît pas la grammaire. C’est l’objection naturelle — et sa réponse renforce la thèse au lieu de l’affaiblir : on ne mesure jamais la surprise contre la grammaire vraie ; toujours contre le modèle courant de l’apprenant.
Le surprisal prédictif (Hale, 2001 ; Levy, 2008) est l’étonnement causé par un événement, étant donné ce que le modèle attendait juste avant :
$S(x) = -\log_2 P_t(x \mid \text{contexte})$
où $P_t$ est le modèle actuel, si imparfait soit-il. Exemple : après « le chat est sur le… », si mon modèle attribue $P(\text{tapis}) = 0{,}5$ et $P(\text{toit}) = 0{,}01$, alors tapis me surprend de $1$ bit, toit de $6{,}6$ bits. Musicalement : après une cadence ii–V (sous-dominante → dominante), une cadence rompue (on va sur le vi au lieu de la tonique attendue) produit un surprisal élevé. Tout est calculé contre mes attentes — donc défini même sans connaître la grammaire vraie.
Reste à relier cette surprise à l’apprentissage. Il faut distinguer deux surprises :
- la surprise prédictive (ci-dessus, Shannon) : sur le prochain symbole, en bits ;
- la surprise du modèle, dite bayésienne (Itti & Baldi, 2009 ; Baldi & Itti, 2010, qui la mesurent en bits — leurs « wows ») : de combien le modèle change après l’événement, c’est-à-dire l’information gagnée sur la grammaire, en bits elle aussi.
La première déclenche la seconde : un événement très surprenant est un événement que le modèle prédisait mal, donc un événement qui force une mise à jour. Si l’on note $\kappa$ en bits (l’information accumulée sur la grammaire), la thèse s’énonce :
$\text{surprise} \;\approx\; \frac{d\kappa}{dt}$
la surprise est la vitesse à laquelle la connaissance grammaticale augmente. Lue à l’envers : pas de surprise = pas de friction = pas d’apprentissage. La friction cognitive est la dérivée de la connaissance. (Statut honnête : c’est une formulation de travail, pas un théorème — elle suppose une mesure de $\kappa$ en bits qui reste à établir.)
L’oracle écologique
Il manque une pièce. À $\kappa$ bas — quand on apprend vraiment — la compression sans redondance produit des erreurs : on décode mal, on sur-généralise, on se trompe. Qu’est-ce qui corrige ces erreurs ? Dans l’apprentissage formel, on imagine un oracle : une instance qui répond « oui, cette phrase est correcte » ou « non ». Mais d’où vient un tel oracle dans la vraie vie ?
Le faux problème de la correction explicite
La réponse classique bute sur une objection célèbre : le feedback correctif explicite (un adulte qui dit « non, ça ne se dit pas ») est rare et peu fiable dans l’acquisition réelle (le débat ouvert par Brown & Hanlon, 1970 ; synthétisé par Marcus, Negative evidence in language acquisition, 1993). Si l’apprentissage en dépendait, il n’aurait pas lieu. C’est le « problème de l’absence de preuve négative ».
La thèse en sort par le haut : elle n’a pas besoin de correction explicite. Ce dont elle a besoin existe en permanence — un flux multi-canal, surtout implicite, de signaux de validation et d’invalidation, présent dans toute activité conjointe.
L’oracle est dans l’écologie de l’interaction
Plusieurs niveaux de communication, plus ou moins conscients, coexistent en continu : hochements et « mhm » (backchannels), regard, expressions, tension corporelle, mouvements. S’y ajoutent des mécanismes mieux décrits : la reformulation d’une erreur, qui fournit une preuve négative indirecte — l’enfant entend la forme correcte juxtaposée à la sienne et infère la correction (Chouinard & Clark, Adult reformulations of child errors as negative evidence, 2003) ; la réparation collaborative, où les interlocuteurs négocient le sens jusqu’au succès (Clark & Wilkes-Gibbs, Referring as a collaborative process, 1986) ; l’alignement interactif, par lequel les représentations des interlocuteurs se synchronisent largement automatiquement (Pickering & Garrod, 2004).
Le cas le plus pur est musical. Dans une improvisation de groupe, quand un musicien sort du cadre — rompt le mètre, ou prend trop de place — personne ne dit « faux ». C’est la désynchronisation ressentie qui est le signal : l’attente partagée du groupe est violée, et cette violation produit une tension immédiate, audible et corporelle, qui ramène le musicien dans le cadre. L’action musicale conjointe exige précisément d’« anticiper, suivre et s’ajuster aux actions de l’autre en temps réel » (Keller, Novembre & Hove, Rhythm in joint action, 2014). C’est l’erreur de prédiction rendue sociale : le modèle partagé est disconfirmé, et tout le monde le ressent.
On obtient une hiérarchie du feedback, du plus faible au plus fort :
- correction explicite — rare, réservée à l’apprentissage formel : on s’appuie peu dessus ;
- validation/invalidation implicite — omniprésente : backchannels, reformulation, réparation, alignement ;
- disconfirmation structurelle — briser le cadre partagé produit une tension immédiate : la plus forte, et la musique en est le cas le plus net.
D’où le nom : l’oracle n’est pas un maître qui corrige, c’est l’écologie de l’interaction elle-même. La paresse du locuteur (qui sous-spécifie) crée les erreurs ; l’interaction fournit, gratuitement et en continu, le signal qui les corrige.
La boucle qui se règle toute seule
Tout se referme alors en une boucle. Le locuteur paresseux retire de la redondance et produit de l’ambiguïté ; si la connaissance partagée est haute, le récepteur reconstruit sans peine ; si elle est basse (l’apprenant), les erreurs font surface, l’oracle écologique les signale, le modèle se met à jour, $\kappa$ monte — et la fois suivante, le locuteur peut comprimer un peu plus. Le système s’auto-régule vers le code le plus comprimé encore décodable, étant donné le coût du milieu et la connaissance partagée.
Le feedback est double. Recevoir le message ne suffit pas à valider la compréhension. Le récepteur expose d’abord ce qu’il a compris — il répond, agit, ou signale qu’il bloque (flux b) ; et c’est la réaction du locuteur à cette réponse (flux c) — confirmation, correction, ou silence — qui valide ou invalide. Le non-feedback est lui-même un signal : pas de correction = ratification tacite (« on continue, donc c’était juste »). C’est le premier axiome de la pragmatique de la communication — on ne peut pas ne pas communiquer (Watzlawick, Beavin & Jackson, 1967) : même l’absence de réaction signifie. C’est l’étayage conversationnel (grounding ; Clark & Wilkes-Gibbs, 1986) : on s’accorde par tours, et la reformulation (Chouinard & Clark, 2003) est précisément ce feedback c à une réponse erronée. Joliment, le silence est la thèse appliquée au canal de validation — zéro bit qui porte quand même « compris », parce que la connaissance partagée le reconstruit : la compression poussée à sa limite. La mise à jour du modèle est donc nourrie par deux sources : l’erreur de prédiction interne (le message contredit le modèle) et la validation externe (la réaction du locuteur à la réponse).
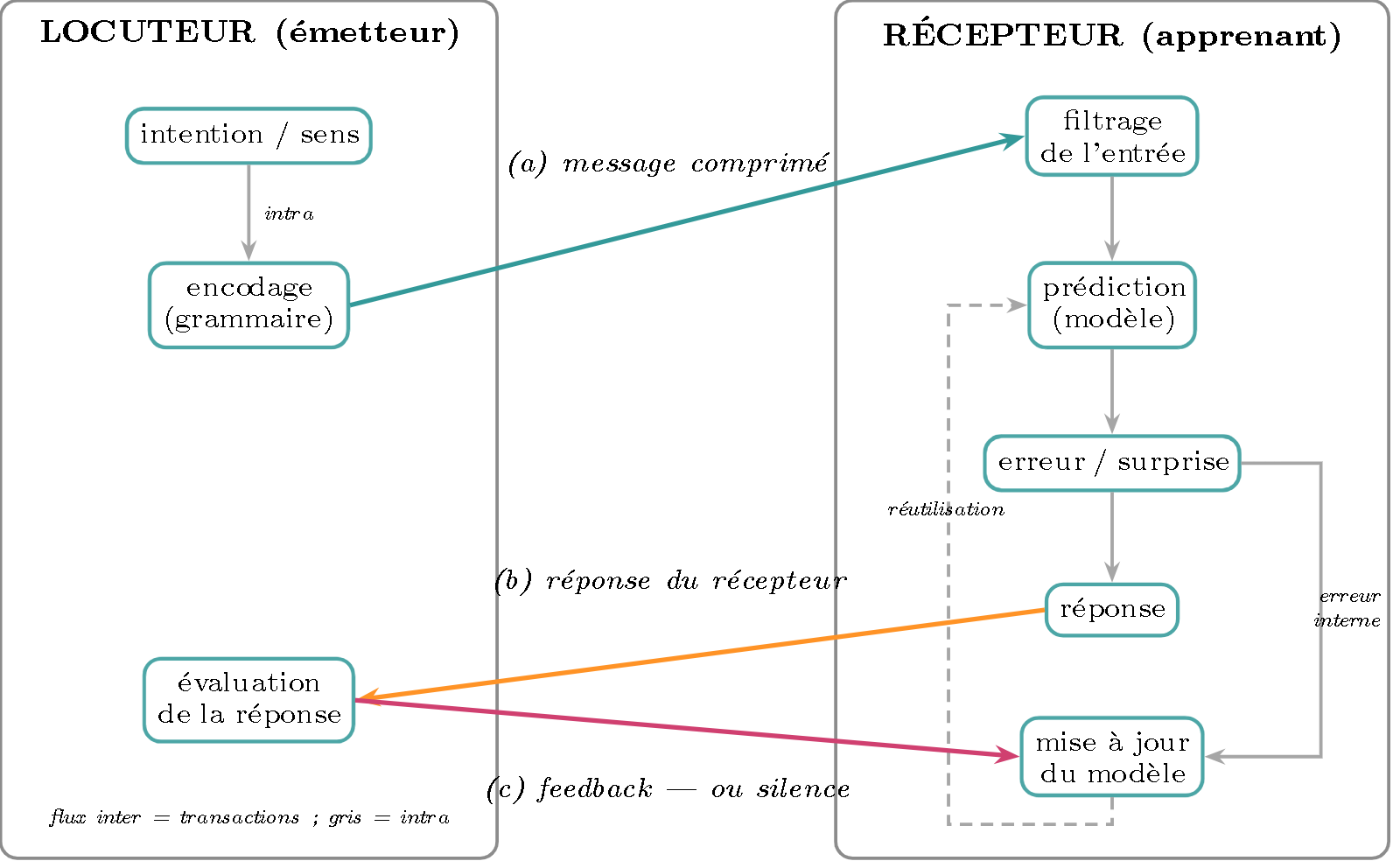
Figure 2 — Les flux. Inter-acteurs (transactions colorées) : (a) message, (b) réponse du récepteur, (c) feedback du locuteur — ou silence. Intra-acteur (gris) : les pipelines internes (encodage chez le locuteur ; filtrage → prédiction → erreur → réponse → mise à jour chez le récepteur, plus la réutilisation du modèle). La mise à jour est nourrie par deux sources : l’erreur de prédiction interne et la validation externe (c).
Où cela se place vis-à-vis de Gold
L20 rappelait le mur de Gold (1967) : à partir de données positives seules, en présentation adversariale, l’inférence des classes superfinies (qui contiennent tous les langages finis et au moins un infini) est impossible. La littérature connaît deux échappatoires : injecter un prior bayésien (Horning, 1969 — une hypothèse interne sur l’espace des grammaires), ou supposer un oracle formel parfait (l’algorithme L* d’Angluin, 1987, qui interroge un oracle d’appartenance et d’équivalence).
L’oracle écologique propose un troisième type : un oracle bruité, partiel, collaboratif, qui émerge du processus communicatif lui-même. Il faut être honnête sur ce que c’est, et sur ce que ce n’est pas :
Ce n’est pas « casser Gold ». C’est entrer dans le régime informant que Gold lui-même distingue du texte passif — et qu’il montre plus puissant. La contribution n’est pas l’existence de ce régime, mais l’explication de pourquoi il émerge naturellement : la paresse du locuteur fabrique les erreurs, et l’interaction fournit l’oracle qui les corrige.
Que des hypothèses distributionnelles suffisent à sortir du pessimisme de Gold pour l’acquisition humaine est par ailleurs défendu de longue date (Clark & Lappin, Linguistic Nativism and the Poverty of the Stimulus, 2011) ; l’oracle écologique en donne une lecture interactionnelle plutôt que purement statistique. Pour le cadre général de l’inférence grammaticale, la référence reste de la Higuera (2010).
Vers une formalisation : quel taux d’erreur optimal ?
La thèse ne prend tout son sens que si l’on relie explicitement trois grandeurs.
– le taux de compression $R$ (bits par signifié) — la paresse du locuteur : plus on comprime, moins d’énergie $E(R)$ à fournir pour transmettre ;
- le taux d’erreur $\varepsilon$ (la distorsion) — conséquence de la compression, modulée par la connaissance partagée : $\varepsilon(R, \kappa)$ croît avec $R$, décroît avec $\kappa$ ;
- l’apprentissage extrait $G$ (le gain de connaissance $d\kappa$) — fonction de $\varepsilon$ en U inversé (trop peu d’erreur : rien à apprendre ; trop : du bruit que l’oracle ne résout pas) et de la puissance de l’oracle.
Le point crucial : communiquer et apprendre n’ont pas le même optimum d’erreur. Pour communiquer, on minimise $\varepsilon$ — l’erreur est un coût. Pour apprendre, on veut un $\varepsilon$ non nul, optimal — l’erreur est le signal. D’où des questions ouvertes qu’on peut au moins formuler nettement :
- Optimum communicatif : à coût de milieu et $\kappa$ partagé donnés, quel $R$ minimise l’énergie pour une erreur tolérable ? (Territoire connu : débit-distorsion, efficacité communicative.)
- Optimum d’apprentissage (la question propre à cette thèse) : quel taux d’erreur $\varepsilon^{*}$ maximise l’apprentissage par unité d’énergie dépensée ?
- Les deux optima coïncident-ils ? Sinon, leur écart mesure le surcoût qu’un « bon professeur » accepte : produire exprès plus d’erreur que la communication pure n’en exigerait, parce que cette erreur enseigne. La transmission orale est le lieu même de cet arbitrage.
- De quoi dépend $\varepsilon^{*}$ ? De la puissance de l’oracle (combien d’erreurs il sait résoudre) et de $\kappa$ courant — l’optimum se déplace à mesure qu’on apprend.
Perspective de formalisation. Une formalisation devrait écrire un objectif unique arbitrant énergie × distorsion × gain d’information sur la grammaire, puis en déduire $\varepsilon^{*}$ comme le point où le gain d’apprentissage marginal par unité d’énergie est maximal. Trois cadres formels sont les candidats naturels — et déjà mobilisés ici : la débit-distorsion (Shannon), le goulot d’information (information bottleneck, dont relèvent les travaux de Zaslavsky et al.), et l’énergie libre / inférence active (Friston). Côté empirique, la notion de difficulté désirable (desirable difficulties, R. & E. Bjork) suggère qu’un tel optimum non trivial existe. Tout cela reste à établir : c’est un programme, pas un résultat.
L’effort d’apprendre, et son amortissement. Le bilan ci-dessus ne comptait que l’énergie de transmission (côté locuteur). Mais apprendre a son propre coût — la paresse de traitement : mettre à jour le modèle demande de l’effort, ce que la flemme cherche à éviter. $\varepsilon^{*}$ n’arbitre donc pas seulement gain vs énergie de transmission, mais gain d’apprentissage vs effort d’apprentissage, et l’erreur doit être assez non-ignorable pour valoir cet effort. Ce qui fait pencher la balance, c’est en partie la paresse de réitération : on paie l’effort une fois pour ne pas recommencer — apprendre est un investissement amorti sur les usages futurs. (Même la paresse de modèle a un coût caché : trouver la grammaire la plus simple est NP-dur — cf. L20, Pitt & Warmuth.)
État des lieux : sait-on chiffrer chaque paresse ? En deux monnaies — l’information (bits) et l’énergie (effort) — voici où l’on en est.
| Paresse | Traduction formelle | Chiffrable aujourd’hui ? |
|---|---|---|
| (1) production | longueur du message, en bits (débit-distorsion) | Oui — théorie mûre |
| (2) représentation | $I(\text{entrée};\text{pertinent})$ (goulot d’information) | En principe — mais « pertinent » dépend de la tâche, souvent non spécifié |
| (3) modèle | longueur de description, en bits (MDL) | Oui — mais l’optimum exact est NP-dur |
| (4) traitement | coût (énergie/temps) de la mise à jour | Partiel — pas de métrique unifiée ; proxys (calcul, nombre de mises à jour) |
| (5) réitération | coût futur évité, actualisé | Ouvert — exige un horizon et un taux d’actualisation à poser |
→ On sait bien chiffrer la compression (1, 2, 3, en bits) ; on bute sur l’effort (4) et le temps (5), faute de monnaie commune. Le pont manquant — combien d’énergie vaut un bit appris ? — n’est pas qu’une vue de l’esprit : il a peut-être un substrat, et c’est ce que suggère la dimension incarnée.
Ce que l’économie de la paresse change
Si l’on prend cette thèse au sérieux, plusieurs propriétés d’un apprentissage interactif idéal en découlent.
- La génération paresseuse est le bon comportement. Un générateur qui sous-spécifie ne produit pas un défaut : il fabrique les erreurs productives dont l’apprenant a besoin pour progresser. Trop d’explicite n’apprend rien ; un peu d’ambiguïté force l’inférence.
- On pose d’abord la question la plus informative. Puisque l’oracle est coûteux (chaque sollicitation du partenaire prend du temps et de l’énergie), il faut maximiser $d\kappa/dt$ : poser la question dont la réponse réduit le plus l’incertitude. C’est la friction utile, pas la friction gratuite.
- Les priors de structure font franchir le mur de Gold à bon compte. Des régularités connues d’avance (par exemple métriques) injectent du $\kappa > 0$ et réduisent ce qu’il faut demander à l’oracle.
- Plus on partage, plus on peut être elliptique. L’ellipse permise croît avec la connaissance partagée — observable, et testable (voir prédictions).
Efficacité, ou paresse ? La dimension incarnée
On pourrait tout dire en efficacité : énergie, bits, optima. C’est la description normative — le « niveau computationnel », ce qui devrait être optimisé (débit-distorsion, MDL, goulot d’information). Mais « paresse » nomme la même chose autrement : non plus un calcul, mais une pulsion — la dimension animale, incarnée, de l’effort qu’on rechigne à fournir. Et cette dimension a un organe.
Le striatum (au cœur des ganglions de la base, modulé par la dopamine) est précisément la machinerie du coût d’effort — décider si une action « vaut le coup » (Salamone & Correa, 2012) — et de la formation des habitudes, c’est-à-dire de la « non-réitération » : automatiser pour ne pas recommencer (Yin & Knowlton, 2006). Neuralement, deux de nos paresses (traitement et réitération).
Or — et c’est le point — le signal d’apprentissage habite le même substrat. L’erreur de prédiction de récompense, portée par les neurones dopaminergiques (Schultz, Dayan & Montague, 1997), est la version neuronale de notre surprisal : l’écart entre l’attendu et le réel, qui pilote la mise à jour. Minimiser l’effort (la paresse) et apprendre (l’erreur de prédiction) sont donc arbitrés par la même circuiterie.
D’où une hypothèse — peut-être pas une coïncidence. L’animal résout le conflit effort ↔ apprentissage de l’intérieur, en rendant l’apprentissage intrinsèquement récompensant. La curiosité elle-même se modélise comme une recherche de progrès d’apprentissage (learning progress — en somme, maximiser $d\kappa/dt$) traitée comme une utilité intrinsèque (Gottlieb & Oudeyer, 2018). Le système qui dit « ne te fatigue pas » est alors le même qui dit « ça valait le coup » quand une erreur se résout — et c’est ce qui permet à l’apprentissage de gagner contre la flemme et de garantir son efficacité optimale.
Statut. Cette convergence — effort, habitude et erreur de prédiction dans un substrat commun — est une lecture interprétative, pas une identité démontrée. Mais elle suggère que le « taux d’erreur optimal » de la section précédente n’est pas qu’une métaphore : il a peut-être un support biologique, taillé pour que la quête de $\varepsilon^{*}$ soit agréable.
Les limites honnêtes
Une thèse n’est solide que si elle expose ses points faibles.
- La puissance exacte de l’oracle écologique reste à caractériser. La learnability dépend entièrement de ce que le feedback fournit. L’oracle communicatif est plus faible que l’oracle d’équivalence d’Angluin, plus riche que le texte de Gold : où se situe-t-il exactement, et quelle classe de langages rend-il apprenable ? Question ouverte.
- L’ambiguïté n’est un signal que dans une boucle. Plus de paresse = plus d’erreurs, mais pas forcément plus d’apprentissage. Il faut la boucle complète prédiction → disconfirmation → preuve pour convertir l’erreur en évidence. Sans elle, l’ambiguïté n’est que du bruit.
- Ne pas conflater les compressions. MDL (inférence) et Shannon-canal (transmission) doivent rester distincts, même réunis sous « le moins de bits ».
- Le noyau formel est une hypothèse.
surprise ≈ dκ/dtet la boucle auto-régulatrice sont des formulations de travail, pas des résultats démontrés.
Ce qu’il faut retenir
- Un seul processus : générer, reconnaître, inférer, apprendre sont des points d’un continuum paramétré par la connaissance grammaticale $\kappa$.
- Cinq paresses, un système de forces : production (message), représentation (entrée) et modèle (grammaire) orientent l’apprentissage ; traitement (effort) lui résiste ; réitération (ne pas recommencer) l’amortit.
- Le taux de compression efficace dépend du milieu et de la connaissance partagée — pas une constante.
- Le moteur est l’erreur de prédiction, mesurée contre le modèle courant ; la surprise est la vitesse d’apprentissage.
- L’oracle n’est pas un maître mais l’écologie de l’interaction — feedback implicite multi-canal, dont la musique conjointe est le cas le plus pur.
- Ce n’est pas casser Gold : c’est expliquer pourquoi le régime informant émerge naturellement.
- Cadrage assumé : une unification de briques existantes, pas un mécanisme neuf.
- Apprendre va à contre-courant de la flemme de réception : c’est un effort, justifié par la réitération (apprendre une fois pour ne pas refaire) — et effort et apprentissage partagent peut-être un substrat (striatum, erreur de prédiction de récompense).
Prédictions falsifiables
Le cadre gagne à risquer des prédictions testables.
- Sous-spécification optimale (U inversé) : un input modérément sous-spécifié fait apprendre plus vite qu’un input totalement explicite ou trop ambigu.
- Feedback calé sur le surprisal : un signal de validation/invalidation donné aux moments de fort surprisal apprend plus, par unité de feedback, qu’un signal donné à faible surprisal.
- Entrainement comme oracle (la plus spécifique) : en improvisation de groupe, qui brise le cadre métrique reçoit des signaux correctifs implicites plus rapides et plus forts (mesurables : ajustements de timing des autres, regards, sa propre correction) ; et ce signal implicite suffit à converger, sans aucune instruction explicite.
- Réparation = preuve négative : les reformulations correctives se concentrent aux points de fort surprisal de l’apprenant, qui sur-généralise d’autant moins qu’il en reçoit à ces points.
- Ellipse ∝ connaissance partagée : le degré d’ellipse d’un locuteur croît avec ce qu’il partage avec son interlocuteur (mesurable sur corpus expert↔expert vs expert↔novice).
Pour aller plus loin
Compression et information
- Shannon, C. E. (1959). « Coding Theorems for a Discrete Source with a Fidelity Criterion. » IRE Convention Record 7 — la théorie débit-distorsion.
- Rissanen, J. (1978). « Modeling by Shortest Data Description. » Automatica 14(5), 465-471 — le principe MDL.
- Grünwald, P. (2007). The Minimum Description Length Principle. MIT Press.
- Chaitin, G. J. (2005). Meta Math! Pantheon — comprendre comme comprimer.
- Tishby, N. & Zaslavsky, N. (2015). « Deep learning and the information bottleneck principle. » IEEE ITW. DOI:10.1109/itw.2015.7133169 — le goulot d’information.
Efficacité du langage
- Gibson, E. et al. (2019). « How Efficiency Shapes Human Language. » Trends in Cognitive Sciences 23(12). DOI:10.1016/j.tics.2019.09.005
- Zaslavsky, N. et al. (2018). « Efficient compression in color naming and its evolution. » PNAS 115(31), 7937-7942. DOI:10.1073/pnas.1800521115
Prédiction et surprise
- Dell, G. S. & Chang, F. (2014). « The P-chain: relating sentence production and its disorders to comprehension and acquisition. » Phil. Trans. R. Soc. B 369. DOI:10.1098/rstb.2012.0394
- Friston, K. (2010). « The free-energy principle: a unified brain theory? » Nature Reviews Neuroscience 11(2), 127-138. DOI:10.1038/nrn2787
- Itti, L. & Baldi, P. (2009). « Bayesian surprise attracts human attention. » Vision Research 49(10), 1295-1306. DOI:10.1016/j.visres.2008.09.007
- Hale, J. (2001). « A Probabilistic Earley Parser as a Psycholinguistic Model. » NAACL — le surprisal.
- Levy, R. (2008). « Expectation-Based Syntactic Comprehension. » Cognition 106(3), 1126-1177.
Feedback, interaction, action conjointe
- Marcus, G. F. (1993). « Negative evidence in language acquisition. » Cognition 46(1), 53-85. DOI:10.1016/0010-0277(93)90022-N90022-N)
- Chouinard, M. M. & Clark, E. V. (2003). « Adult reformulations of child errors as negative evidence. » Journal of Child Language 30(3), 637-669. DOI:10.1017/S0305000903005701
- Clark, H. H. & Wilkes-Gibbs, D. (1986). « Referring as a collaborative process. » Cognition 22(1), 1-39. DOI:10.1016/0010-0277(86)90010-790010-7)
- Watzlawick, P., Beavin, J. H. & Jackson, D. D. (1967). Pragmatics of Human Communication. Norton — premier axiome : « on ne peut pas ne pas communiquer ». DOI:10.4324/9781315080918-7 (chap. axiomes)
- Pickering, M. J. & Garrod, S. (2004). « Toward a mechanistic psychology of dialogue. » Behavioral and Brain Sciences 27(2), 169-190. DOI:10.1017/S0140525X04000056
- Keller, P. E., Novembre, G. & Hove, M. J. (2014). « Rhythm in joint action. » Phil. Trans. R. Soc. B 369(1658), 20130394. DOI:10.1098/rstb.2013.0394
Inférence grammaticale et apprenabilité
- Gold, E. M. (1967). « Language Identification in the Limit. » Information and Control 10(5), 447-474.
- Angluin, D. (1987). « Learning Regular Sets from Queries and Counterexamples. » Information and Computation 75(2), 87-106.
- Clark, A. & Lappin, S. (2011). Linguistic Nativism and the Poverty of the Stimulus. Wiley. DOI:10.1002/9781444390568
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press.
Substrat neuronal (dimension incarnée)
- Schultz, W., Dayan, P. & Montague, P. R. (1997). « A Neural Substrate of Prediction and Reward. » Science 275(5306), 1593-1599. DOI:10.1126/science.275.5306.1593
- Salamone, J. D. & Correa, M. (2012). « The Mysterious Motivational Functions of Mesolimbic Dopamine. » Neuron 76(3), 470-485. DOI:10.1016/j.neuron.2012.10.021
- Yin, H. H. & Knowlton, B. J. (2006). « The role of the basal ganglia in habit formation. » Nature Reviews Neuroscience 7(6), 464-476. DOI:10.1038/nrn1919
- Gottlieb, J. & Oudeyer, P.-Y. (2018). « Towards a neuroscience of active sampling and curiosity. » Nature Reviews Neuroscience 19(12), 758-770. DOI:10.1038/s41583-018-0078-0
Inspiration
- Eco, U. (1979). Lector in Fabula. Bompiani — le meccanismo pigro, métaphore du texte paresseux (citée comme inspiration, dans le cadre d’une communication voulue).
Glossaire
- Gradient de connaissance ($\kappa$) : quantité de connaissance grammaticale disponible, de 1 (grammaire connue, reconnaissance) à 0 (rien connu, inférence pure).
- Débit-distorsion : théorie (Shannon) du nombre minimal de bits pour transmettre un message à une fidélité donnée. Tolérer un peu de perte permet de comprimer davantage.
- MDL (Minimum Description Length) : critère de choix d’un modèle ; le meilleur minimise (taille du modèle) + (données encodées par lui). Occam quantifié.
- CRC (cyclic redundancy check) : bits redondants ajoutés pour détecter une corruption. Les retirer comprime mais réduit la robustesse.
- Sous-spécification : omettre, dans un message, ce que le récepteur peut reconstruire — comprimer à la source.
- Surprisal (surprise prédictive) : $-\log_2$ de la probabilité qu’un événement avait sous le modèle courant. En bits. Mesurable sans connaître la grammaire vraie.
- Surprise du modèle (bayésienne) : ampleur du changement du modèle après un événement = information gagnée sur la grammaire. En bits.
- P-chain : cadre psycholinguistique (Dell & Chang) où la prédiction lie production, compréhension et acquisition ; l’erreur de prédiction pilote l’apprentissage.
- Codage prédictif / énergie libre : principe (Friston) selon lequel le cerveau minimise la surprise (l’erreur de prédiction).
- Oracle : instance qui répond « cette chaîne est-elle dans le langage ? » (et parfois fournit des contre-exemples). Présuppose une forme de reconnaissance.
- Oracle écologique : ici, l’oracle non formel formé par le feedback de l’interaction (réparation, alignement, désynchronisation), surtout implicite.
- Régime informant (vs texte) : chez Gold, apprentissage avec accès à des réponses/contre-exemples, plus puissant que les seules données positives.
- Classe superfinie : classe contenant tous les langages finis et au moins un infini ; non identifiable depuis des positifs seuls (mur de Gold).
- Entrainement (entrainment) : synchronisation des comportements rythmiques entre individus en interaction (ici, en musique conjointe).
- Efficacité communicative : pression façonnant les langues vers un compromis effort-du-locuteur / informativité.
- Taux de compression ($R$) : nombre de signifiants (bits) par signifié transmis. Comprimer = abaisser $R$ = dépenser moins d’énergie $E(R)$.
- Taux d’erreur / distorsion ($\varepsilon$) : proportion de ce que le récepteur ne reconstruit pas correctement. Croît avec la compression $R$, décroît avec la connaissance partagée $\kappa$.
- Apprentissage extrait ($G$) : gain de connaissance $d\kappa$ tiré des erreurs résolues. Fonction de $\varepsilon$ en U inversé (ni trop peu, ni trop) et de la puissance de l’oracle.
- Taux d’erreur optimal ($\varepsilon^{*}$) : taux d’erreur qui maximise l’apprentissage par unité d’énergie. Distinct de l’optimum communicatif (qui, lui, minimise l’erreur).
- Goulot d’information (information bottleneck) : cadre formel (Tishby) du compromis entre compression d’une variable et information conservée sur une autre — candidat pour formaliser $\varepsilon^{*}$.
- Difficulté désirable (desirable difficulties, R. & E. Bjork) : observation que des obstacles d’apprentissage bien dosés améliorent la rétention — l’idée empirique d’un optimum d’erreur non trivial.
- Striatum / ganglions de la base : structures cérébrales (modulées par la dopamine) qui calculent le coût d’effort et forment les habitudes.
- Erreur de prédiction de récompense : écart entre récompense attendue et reçue, signalé par la dopamine (Schultz) ; substrat neuronal du surprisal et de la mise à jour.
- Progrès d’apprentissage (learning progress) : vitesse à laquelle on apprend ($\approx d\kappa/dt$) ; modélise la curiosité comme utilité intrinsèque (Gottlieb & Oudeyer).
Liens connexes
- L20 — L’inférence, la troisième direction — Gold, gradient $\kappa$, MDL : le socle de cet essai
- L18 — Le renversement de signe — générer sous contrainte = décompression, le pendant de l’inférence
- L19 — Le P-chain — la prédiction d’erreur comme moteur de l’apprentissage
- M10 — L’induction de grammaires musicales — Gold, Sequitur, MDL en pratique
Prérequis : L20 (recommandé), L19
Temps de lecture : 24 min
Tags : #double-paresse #oracle-écologique #compression #débit-distorsion #erreur-de-prédiction #entrainement #inférence-grammaticale