L21) The Economy of Laziness and the Ecological Oracle
Reading Note
This article only develops a thesis. It assembles known elements (information theory, grammar learning, psycholinguistics) into a coherent framework. When statement is a hypothesis, it is noted as such. Useful prerequisite: L20 (inference and Gold’s wall).
How do we learn a grammar?
Generating a sentence, recognizing its structure, inferring the grammar from examples, and learning that grammar are not four separate operations. They are points of the same process, driven by prediction error, paid for in compression, and fueled by an economy of laziness.
This is the thesis of this article. It does not claim a new mechanism—each of its pieces already exists in the literature. Its proposal is a framing: showing that these pieces, put together, describe a single coherent system. Let’s unpack it term by term.
A reference point, first, inherited from L20: the knowledge gradient $\kappa$ (kappa). This is the amount of grammatical knowledge available to the analyzer. At $\kappa = 1$, the grammar is fully known: this is recognition (verifying that a sentence belongs to the language). At $\kappa = 0$, nothing is known: this is pure inference (guessing the grammar from examples alone). Between the two lies a continuum. Learning is moving along this axis, from low $\kappa$ toward high $\kappa$.
Lazinesses: An Economy of Effort
The thesis rests on a fertile asymmetry between two actors: the one who emits (the speaker, the generator) and the one who receives and learns (the listener, the analyst). Both are lazy—but there are actually several lazinesses, some of which complement each other and others that oppose each other.
The speaker’s laziness: saying as little as possible
An efficient speaker does not transmit everything. They under-specify: they omit what the listener can reconstruct, they leave ambiguities, they abbreviate. Umberto Eco gave this idea a lasting image, the meccanismo pigro—the lazy text that requires the reader’s inferential cooperation to fill in its blanks (Lector in Fabula, 1979). Important: for Eco, this laziness is a matter of intended communication—the author omits intentionally, betting on the reader. We keep Eco here as inspiration, not as proof.
Beneath the image lies a measurable phenomenon: compressing at the source. Reducing the number of signifiers for the same signified means spending less effort to produce and transmit. The theory that exactly describes this trade-off is Shannon’s rate-distortion theory (Coding theorems for a discrete source with a fidelity criterion, 1959): what is the minimum number of bits required to transmit a message at a given fidelity? The less loss one tolerates, the more bits are needed; accepting a little loss allows for more compression.
A computer analogy clarifies the stakes. Transmitting a message without an error-detecting code (CRCs, cyclic redundancy checks, those redundant bits that signal corruption) costs less—fewer bits, less transcoding effort—but it is riskier: if the channel is noisy, or if the receiver lacks the model to reconstruct, the error goes unnoticed. Removing redundancy is a trade-off of compression versus robustness.
And the cost one seeks to reduce—effort, energy—depends on the environment. The transmission speed of neurons has nothing to do with the density of air: producing an articulatory gesture, propagating an acoustic wave, and decoding a nerve signal do not cost the same. The optimum of laziness forms where the bottleneck is most costly. A direct consequence, and a point specific to this thesis:
The effective compression rate—how many signifiers for one signified—is not fixed. It depends on the environment (the energy cost of the channel) and on the shared knowledge between the sender and the receiver.
And—apparent paradox—it is also at the bottleneck, where the channel is most costly, that the most uncertainty is concentrated: compressing heavily means leaving the most to be reconstructed. The system does not respond by hardening (adding redundancy) but by relying on shared knowledge; where this is lacking, the residual uncertainty surfaces as an error. The most costly bottleneck is therefore also the place of the greatest surprise—and thus, as we shall see, of the greatest learning. This is not a contradiction but a consequence of rate-distortion: with a costly channel, one accepts more loss. Energy savings and learning friction reside in the same place.
The more the receiver shares the grammar, the lazier the speaker can be: the receiver reconstructs the omitted bits with their own model. We observe this everywhere—jargon between experts, ellipsis between intimates, the codes of a group: all instances of shared knowledge that allow for extreme compression. Facing a novice, we “add CRC”: we make things explicit. That languages themselves are sculpted by this pressure for efficiency—a trade-off between speaker effort and listener need—is now a documented result (Gibson et al., How Efficiency Shapes Human Language, 2019; Zaslavsky et al., 2018, show that naming systems achieve near-optimal compression in the information-theoretic sense).
The receiver’s three lazinesses
On the receiving side, laziness is not unique: there are three, which do not pull in the same direction.
- Representation laziness—not carrying useless information. The receiver retains what is relevant and discards the rest: this is the information bottleneck (Tishby), compressing the input by keeping only what informs about what matters.
- Model laziness—preferring the simplest grammar among those compatible with the examples. This is Occam’s razor, quantified by MDL (Minimum Description Length; Rissanen, 1978; Grünwald, 2007): minimize (model size) + (data encoded by it). “Learning is compression,” radicalized by Chaitin (2005).
- Processing laziness—avoiding the update effort: decoding with the current model, not paying to learn. Unlike the other two, this one opposes learning (we will return to this below).
The first two orient learning (they bound it: compact representation, simple model); the third resists it.
Common laziness: not starting over
A final laziness is shared by both actors: not having to start over. Pay once, reuse later. This is what pushes toward stable routines (Pickering & Garrod’s “dialogue routines”), habits, a shared grammar that is not renegotiated. And this is what makes processing laziness give way: one accepts the effort of learning now precisely to avoid doing it forever. Learning is an investment of laziness.
Three compressions, three objects
Several of these lazinesses are compressions—but they do not apply to the same object, and they must not be conflated (merged into one): Shannon-channel compresses the message (transmitting at lower cost—communication); the information bottleneck compresses the representation (discarding the useless); MDL compresses the model (which grammar is best—inference). Same word, three questions.
The Map of Lazinesses
Laid out, the “economy of laziness” comprises five forces:
| # | Actor | Laziness | On what | Formal framework |
|---|---|---|---|---|
| 1 | speaker | production—saying the least | the message | rate-distortion (Shannon) |
| 2 | receiver | representation—discarding the useless | the input | information bottleneck (Tishby) |
| 3 | receiver | model—staying simple | the model | MDL / Occam |
| 4 | receiver | processing—avoiding effort | the act of learning | (resists learning) |
| 5 | common | reiteration—not starting over | the future | amortization, routines |
And here is where each acts, once the two actors, their internal systems, and the transactions between them are distinguished:
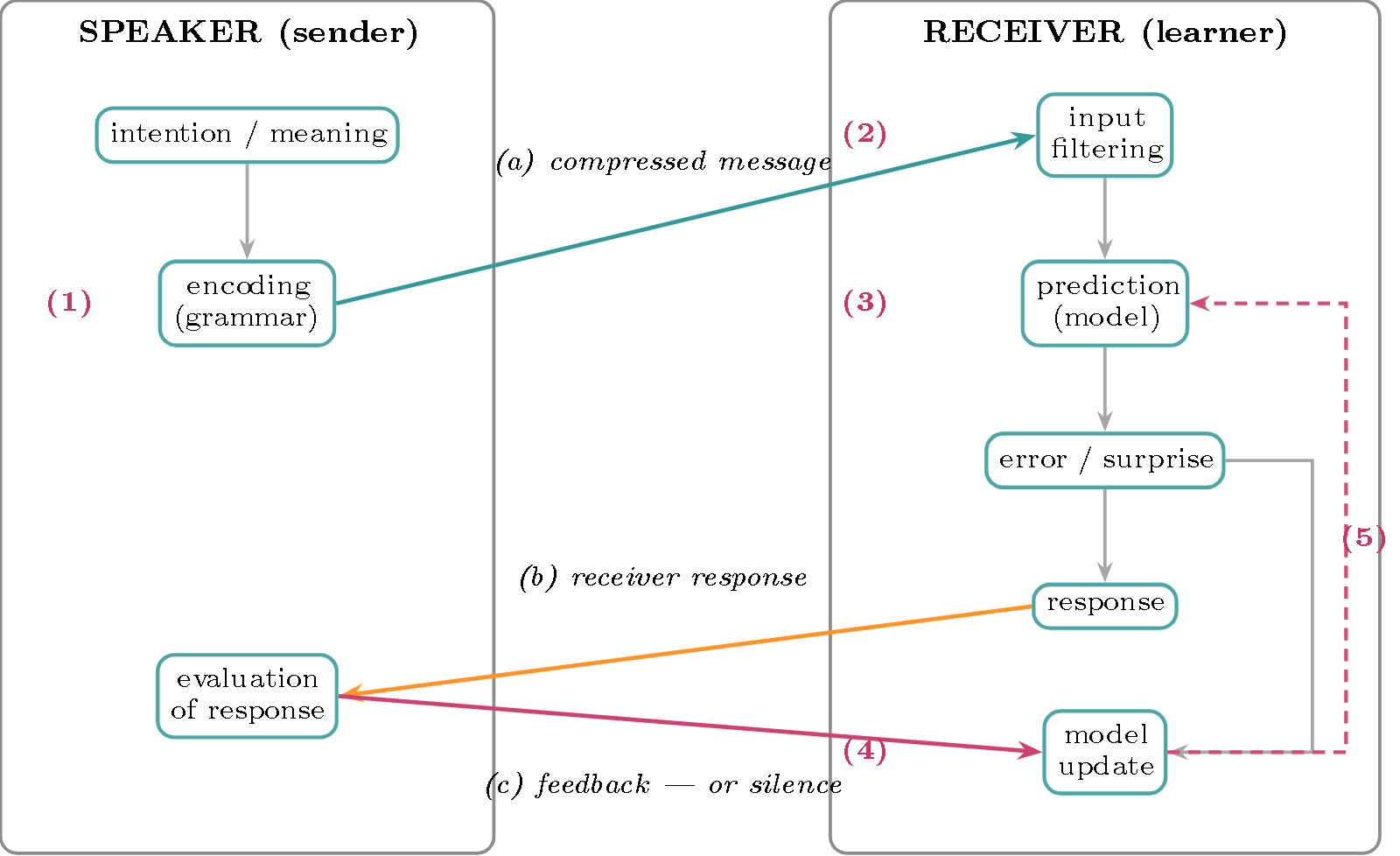
Figure 1 — Where each laziness acts. Two actors (boxes), their internal systems, and the transactions between them. The numbers refer to the table: (1) at the speaker’s encoding, (2) at the input filtering, (3) on the model, (4) on the update, (5) on the reuse of the model from one episode to the next (also shared with the speaker’s encoding).
→ Laziness is therefore not a monolith but a system of forces: one creates error (1), two orient learning (2, 3), one resists it (4), and one amortizes it over time (5). It is their interplay that sets the actual error rate—and, as we shall see, the optimal rate.
The Engine: Prediction Error
What drives this system? Prediction error. In psycholinguistics, Dell & Chang’s (2014) P-chain summarizes the principle: prediction error drives learning—we are constantly predicting what will come next, and the gap between prediction and reality is the signal that updates the model. This is also the heart of predictive coding in neuroscience (Friston, The free-energy principle, 2010): perceiving, acting, and learning amount to minimizing surprise.
But how can one measure surprise when the grammar is unknown? This is the natural objection—and its answer strengthens the thesis instead of weakening it: surprise is never measured against the true grammar; it is always measured against the learner’s current model.
Predictive surprisal (Hale, 2001; Levy, 2008) is the astonishment caused by an event, given what the model expected just before:
$S(x) = -\log_2 P_t(x \mid \text{context})$
where $P_t$ is the current model, however imperfect. Example: after “the cat is on the…”, if my model assigns $P(\text{mat}) = 0.5$ and $P(\text{roof}) = 0.01$, then mat surprises me by $1$ bit, roof by $6.6$ bits. Musically: after a ii–V cadence (subdominant → dominant), a deceptive cadence (moving to vi instead of the expected tonic) produces high surprisal. Everything is calculated against my expectations—thus defined even without knowing the true grammar.
It remains to link this surprise to learning. We must distinguish between two surprises:
- predictive surprise (above, Shannon): on the next symbol, in bits;
- model surprise, called Bayesian (Itti & Baldi, 2009; Baldi & Itti, 2010, who measure it in bits—their “wows”): how much the model changes after the event, i.e., the information gained about the grammar, also in bits.
The first triggers the second: a highly surprising event is an event the model predicted poorly, thus an event that forces an update. If we denote $\kappa$ in bits (the information accumulated about the grammar), the thesis is stated as:
$\text{surprise} \;\approx\; \frac{d\kappa}{dt}$
surprise is the speed at which grammatical knowledge increases. Read backward: no surprise = no friction = no learning. Cognitive friction is the derivative of knowledge. (Honest status: this is a working formulation, not a theorem—it assumes a measure of $\kappa$ in bits that remains to be established.)
The Ecological Oracle
One piece is missing. At low $\kappa$—when one is truly learning—compression without redundancy produces errors: we decode poorly, we over-generalize, we make mistakes. What corrects these errors? In formal learning, we imagine an oracle: an instance that answers “yes, this sentence is correct” or “no.” But where does such an oracle come from in real life?
The false problem of explicit correction
The classic answer hits a famous objection: explicit corrective feedback (an adult saying “no, you don’t say it that way”) is rare and unreliable in actual acquisition (the debate opened by Brown & Hanlon, 1970; synthesized by Marcus, Negative evidence in language acquisition, 1993). If learning depended on it, it would not happen. This is the “problem of the absence of negative evidence.”
The thesis bypasses this: it does not need explicit correction. What it needs exists constantly—a multi-channel, primarily implicit flow of validation and invalidation signals, present in any joint activity.
The oracle is in the ecology of interaction
Several levels of communication, more or less conscious, coexist continuously: nodding and “mhm” (backchannels), gaze, expressions, bodily tension, movements. Added to these are better-described mechanisms: the recasting of an error, which provides indirect negative evidence—the child hears the correct form juxtaposed with their own and infers the correction (Chouinard & Clark, Adult reformulations of child errors as negative evidence, 2003); collaborative repair, where interlocutors negotiate meaning until success (Clark & Wilkes-Gibbs, Referring as a collaborative process, 1986); interactive alignment, through which interlocutors’ representations synchronize largely automatically (Pickering & Garrod, 2004).
The purest case is musical. In group improvisation, when a musician steps out of the frame—breaks the meter or takes up too much space—no one says “wrong.” It is the felt desynchronization that is the signal: the group’s shared expectation is violated, and this violation produces an immediate tension, audible and physical, that pulls the musician back into the frame. Joint musical action requires precisely “anticipating, following, and adjusting to the other’s actions in real time” (Keller, Novembre & Hove, Rhythm in joint action, 2014). This is prediction error made social: the shared model is disconfirmed, and everyone feels it.
We obtain a hierarchy of feedback, from weakest to strongest:
- explicit correction—rare, reserved for formal learning: we rely little on it;
- implicit validation/invalidation—omnipresent: backchannels, recasting, repair, alignment;
- structural disconfirmation—breaking the shared frame produces immediate tension: the strongest, and music is its clearest case.
Hence the name: the oracle is not a master who corrects, it is the ecology of interaction itself. The speaker’s laziness (under-specifying) creates errors; interaction provides, for free and continuously, the signal that corrects them.
The loop that regulates itself
Everything then closes into a loop. The lazy speaker removes redundancy and produces ambiguity; if shared knowledge is high, the receiver reconstructs without difficulty; if it is low (the learner), errors surface, the ecological oracle signals them, the model updates, $\kappa$ rises—and next time, the speaker can compress a little more. The system self-regulates toward the most compressed code still decodable, given the cost of the environment and the shared knowledge.
Feedback is double. Receiving the message is not enough to validate understanding. The receiver first exposes what they understood—they respond, act, or signal that they are stuck (flow b); and it is the speaker’s reaction to this response (flow c)—confirmation, correction, or silence—that validates or invalidates. Non-feedback is itself a signal: no correction = tacit ratification (“we are continuing, so it was correct”). This is the first axiom of the pragmatics of communication—one cannot not communicate (Watzlawick, Beavin & Jackson, 1967): even the absence of reaction signifies. This is conversational grounding (Clark & Wilkes-Gibbs, 1986): we agree through turns, and recasting (Chouinard & Clark, 2003) is precisely this feedback c to an erroneous response. Beautifully, silence is the thesis applied to the validation channel—zero bits that still carry “understood,” because shared knowledge reconstructs it: compression pushed to its limit. The model update is thus fed by two sources: internal prediction error (the message contradicts the model) and external validation (the speaker’s reaction to the response).
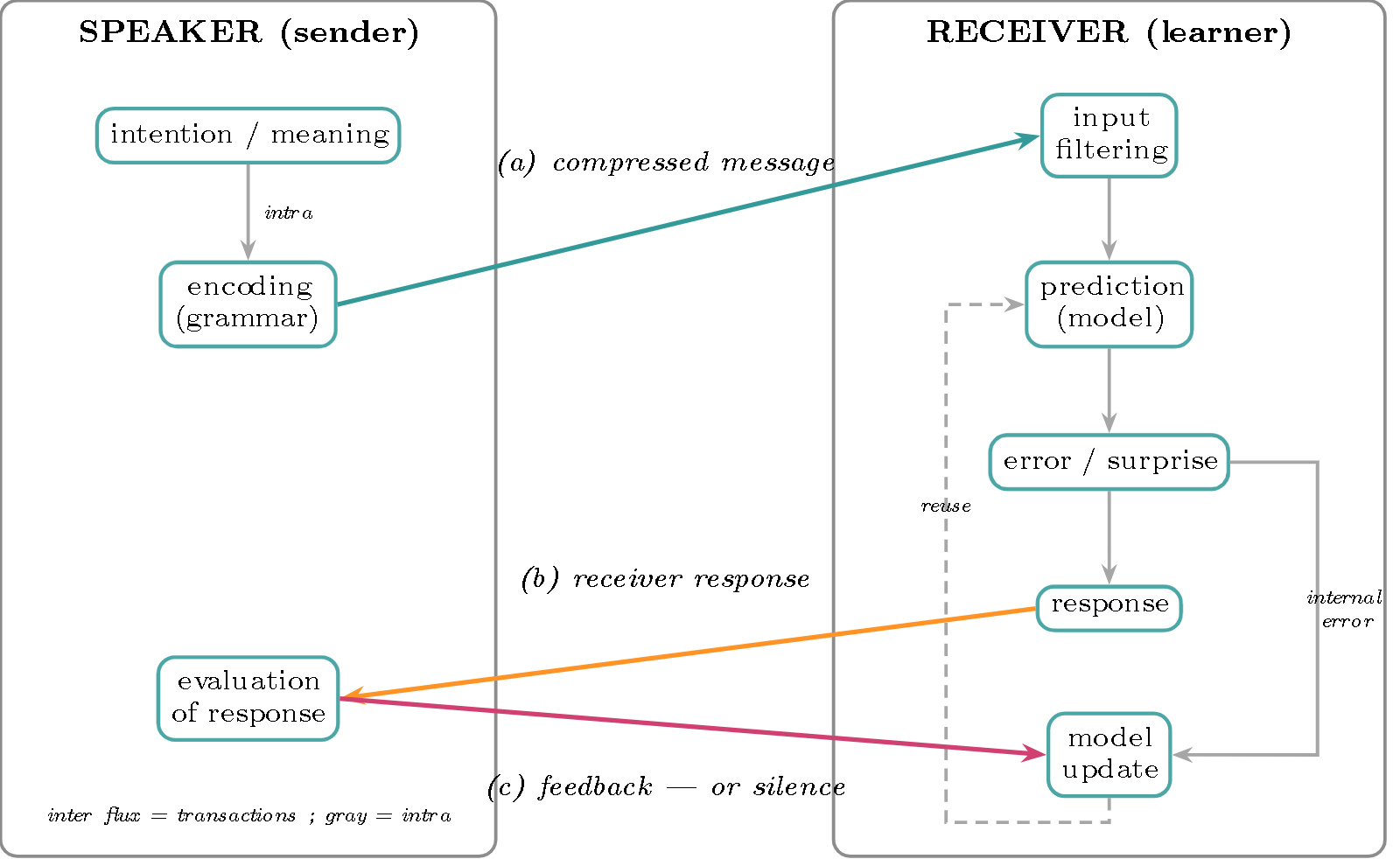
Figure 2 — The flows. Inter-actor (colored transactions): (a) message, (b) receiver response, (c) speaker feedback—or silence. Intra-actor (gray): internal pipelines (encoding for the speaker; filtering → prediction → error → response → update for the receiver, plus model reuse). The update is fed by two sources: internal prediction error and external validation (c).
Where this stands relative to Gold
L20 recalled Gold’s wall (1967): from positive data alone, in adversarial presentation, the inference of superfinite classes (which contain all finite languages and at least one infinite one) is impossible. The literature knows two escapes: injecting a Bayesian prior (Horning, 1969—an internal hypothesis about the grammar space), or assuming a perfect formal oracle (Angluin’s L* algorithm, 1987, which queries a membership and equivalence oracle).
The ecological oracle proposes a third type: a noisy, partial, collaborative oracle that emerges from the communicative process itself. We must be honest about what it is and what it is not:
This is not “breaking Gold.” It is entering the informant regime that Gold himself distinguishes from passive text—and which he shows to be more powerful. The contribution is not the existence of this regime, but the explanation of why it emerges naturally: the speaker’s laziness manufactures errors, and interaction provides the oracle that corrects them.
That distributional hypotheses are sufficient to escape Gold’s pessimism for human acquisition has long been defended (Clark & Lappin, Linguistic Nativism and the Poverty of the Stimulus, 2011); the ecological oracle provides an interactional rather than purely statistical reading of this. For the general framework of grammatical inference, the reference remains de la Higuera (2010).
Toward a Formalization: What is the Optimal Error Rate?
The thesis only takes on its full meaning if we explicitly link three quantities.
– the compression rate $R$ (bits per signified)—the speaker’s laziness: the more we compress, the less energy $E(R)$ is required to transmit;
- the error rate $\varepsilon$ (distortion)—a consequence of compression, modulated by shared knowledge: $\varepsilon(R, \kappa)$ increases with $R$, decreases with $\kappa$;
- the extracted learning $G$ (the knowledge gain $d\kappa$)—a function of $\varepsilon$ in an inverted U (too little error: nothing to learn; too much: noise that the oracle cannot resolve) and the power of the oracle.
The crucial point: communicating and learning do not have the same error optimum. To communicate, we minimize $\varepsilon$—error is a cost. To learn, we want a non-zero, optimal $\varepsilon$—error is the signal. This leads to open questions that can at least be clearly formulated:
- Communicative optimum: given environment cost and shared $\kappa$, what $R$ minimizes energy for a tolerable error? (Known territory: rate-distortion, communicative efficiency.)
- Learning optimum (the question specific to this thesis): what error rate $\varepsilon^{*}$ maximizes learning per unit of energy spent?
- Do the two optima coincide? If not, their gap measures the extra cost a “good teacher” accepts: producing on purpose more error than pure communication would require, because this error teaches. Oral transmission is the very site of this trade-off.
- What does $\varepsilon^{*}$ depend on? On the power of the oracle (how many errors it can resolve) and current $\kappa$—the optimum shifts as one learns.
Formalization perspective. A formalization should write a single objective trading off energy × distortion × information gain about the grammar, then derive $\varepsilon^{*}$ as the point where the marginal learning gain per unit of energy is maximal. Three formal frameworks are natural candidates—and already mobilized here: rate-distortion (Shannon), the information bottleneck (to which the work of Zaslavsky et al. belongs), and free energy / active inference (Friston). On the empirical side, the notion of desirable difficulties (R. & E. Bjork) suggests that such a non-trivial optimum exists. All this remains to be established: it is a program, not a result.
The effort to learn, and its amortization. The balance sheet above only counted transmission energy (speaker side). But learning has its own cost—processing laziness: updating the model requires effort, which laziness seeks to avoid. $\varepsilon^{*}$ therefore does not just trade off gain vs. transmission energy, but learning gain vs. learning effort, and the error must be non-ignorable enough to be worth that effort. What tips the scales is partly reiteration laziness: we pay the effort once to avoid starting over—learning is an investment amortized over future uses. (Even model laziness has a hidden cost: finding the simplest grammar is NP-hard—cf. L20, Pitt & Warmuth.)
Current status: can we quantify each laziness? In two currencies—information (bits) and energy (effort)—here is where we stand.
| Laziness | Formal translation | Quantifiable today? |
|---|---|---|
| (1) production | message length, in bits (rate-distortion) | Yes—mature theory |
| (2) representation | $I(\text{input};\text{relevant})$ (information bottleneck) | In principle—but “relevant” depends on the task, often unspecified |
| (3) model | description length, in bits (MDL) | Yes—but the exact optimum is NP-hard |
| (4) processing | cost (energy/time) of update | Partial—no unified metric; proxies (computation, number of updates) |
| (5) reiteration | avoided future cost, discounted | Open—requires a horizon and a discount rate to be set |
→ We can quantify compression well (1, 2, 3, in bits); we struggle with effort (4) and time (5), for lack of a common currency. The missing bridge—how much energy is a learned bit worth?—is not just a flight of fancy: it may have a substrate, as suggested by the embodied dimension.
What the Economy of Laziness Changes
If we take this thesis seriously, several properties of ideal interactive learning follow.
- Lazy generation is the right behavior. A generator that under-specifies is not producing a defect: they are manufacturing the productive errors the learner needs to progress. Too much explicitness teaches nothing; a little ambiguity forces inference.
- The most informative question is asked first. Since the oracle is costly (each solicitation of the partner takes time and energy), one must maximize $d\kappa/dt$: ask the question whose answer reduces uncertainty the most. This is useful friction, not gratuitous friction.
- Structural priors cross Gold’s wall cheaply. Regularities known in advance (e.g., metrics) inject $\kappa > 0$ and reduce what must be asked of the oracle.
- The more we share, the more elliptical we can be. The allowed ellipsis grows with shared knowledge—observable and testable (see predictions).
Efficiency, or Laziness? The Embodied Dimension
One could say everything in terms of efficiency: energy, bits, optima. This is the normative description—the “computational level,” what should be optimized (rate-distortion, MDL, information bottleneck). But “laziness” names the same thing differently: no longer a calculation, but a drive—the animal, embodied dimension of the effort one is reluctant to provide. And this dimension has an organ.
The striatum (at the heart of the basal ganglia, modulated by dopamine) is precisely the machinery for effort cost—deciding if an action is “worth it” (Salamone & Correa, 2012)—and for habit formation, i.e., “non-reiteration”: automating to avoid starting over (Yin & Knowlton, 2006). Neurally, two of our lazinesses (processing and reiteration).
Now—and this is the point—the learning signal inhabits the same substrate. Reward prediction error, carried by dopaminergic neurons (Schultz, Dayan & Montague, 1997), is the neural version of our surprisal: the gap between the expected and the real, which drives the update. Minimizing effort (laziness) and learning (prediction error) are thus arbitrated by the same circuitry.
Hence a hypothesis—perhaps not a coincidence. The animal resolves the effort ↔ learning conflict from the inside, by making learning intrinsically rewarding. Curiosity itself is modeled as a search for learning progress (in short, maximizing $d\kappa/dt$) treated as an intrinsic utility (Gottlieb & Oudeyer, 2018). The system that says “don’t tire yourself out” is then the same one that says “it was worth it” when an error is resolved—and this is what allows learning to win against laziness and guarantee its optimal efficiency.
Status. This convergence—effort, habit, and prediction error in a common substrate—is an interpretative reading, not a demonstrated identity. But it suggests that the “optimal error rate” of the previous section is not just a metaphor: it may have a biological support, tailored so that the quest for $\varepsilon^{*}$ is pleasant.
Honest Limits
A thesis is only solid if it exposes its weak points.
- The exact power of the ecological oracle remains to be characterized. Learnability depends entirely on what the feedback provides. The communicative oracle is weaker than Angluin’s equivalence oracle, richer than Gold’s text: where exactly does it sit, and what class of languages does it make learnable? Open question.
- Ambiguity is a signal only in a loop. More laziness = more errors, but not necessarily more learning. The complete loop of prediction → disconfirmation → proof is needed to convert error into evidence. Without it, ambiguity is just noise.
- Do not conflate compressions. MDL (inference) and Shannon-channel (transmission) must remain distinct, even if united under “fewer bits.”
- The formal core is a hypothesis.
surprise ≈ dκ/dtand the self-regulating loop are working formulations, not demonstrated results.
Key Takeaways
- A single process: generating, recognizing, inferring, and learning are points on a continuum parameterized by grammatical knowledge $\kappa$.
- Five lazinesses, one system of forces: production (message), representation (input), and model (grammar) orient learning; processing (effort) resists it; reiteration (not starting over) amortizes it.
- The effective compression rate depends on the environment and shared knowledge—not a constant.
- The engine is prediction error, measured against the current model; surprise is the speed of learning.
- The oracle is not a master but the ecology of interaction—multi-channel implicit feedback, of which joint music is the purest case.
- This is not breaking Gold: it is explaining why the informant regime emerges naturally.
- Intentional framing: an unification of existing building blocks, not a new mechanism.
- Learning goes against the grain of reception laziness: it is an effort, justified by reiteration (learning once to avoid doing it again)—and effort and learning may share a substrate (striatum, reward prediction error).
Falsifiable Predictions
The framework benefits from risking testable predictions.
- Optimal under-specification (inverted U): a moderately under-specified input leads to faster learning than a totally explicit or overly ambiguous input.
- Feedback tuned to surprisal: a validation/invalidation signal given at moments of high surprisal teaches more, per unit of feedback, than a signal given at low surprisal.
- Entrainment as an oracle (the most specific): in group improvisation, whoever breaks the metric frame receives faster and stronger implicit corrective signals (measurable: timing adjustments from others, gazes, their own correction); and this implicit signal is sufficient to converge, without any explicit instruction.
- Repair = negative evidence: corrective reformulations concentrate at points of high learner surprisal, who over-generalizes less the more they receive at these points.
- Ellipsis ∝ shared knowledge: a speaker’s degree of ellipsis increases with what they share with their interlocutor (measurable on expert↔expert vs. expert↔novice corpora).
Further Reading
Compression and Information
- Shannon, C. E. (1959). “Coding Theorems for a Discrete Source with a Fidelity Criterion.” IRE Convention Record 7 — rate-distortion theory.
- Rissanen, J. (1978). “Modeling by Shortest Data Description.” Automatica 14(5), 465-471 — the MDL principle.
- Grünwald, P. (2007). The Minimum Description Length Principle. MIT Press.
- Chaitin, G. J. (2005). Meta Math! Pantheon — understanding as compressing.
- Tishby, N. & Zaslavsky, N. (2015). “Deep learning and the information bottleneck principle.” IEEE ITW. DOI:10.1109/itw.2015.7133169 — the information bottleneck.
Language Efficiency
- Gibson, E. et al. (2019). “How Efficiency Shapes Human Language.” Trends in Cognitive Sciences 23(12). DOI:10.1016/j.tics.2019.09.005
- Zaslavsky, N. et al. (2018). “Efficient compression in color naming and its evolution.” PNAS 115(31), 7937-7942. DOI:10.1073/pnas.1800521115
Prediction and Surprise
- Dell, G. S. & Chang, F. (2014). “The P-chain: relating sentence production and its disorders to comprehension and acquisition.” Phil. Trans. R. Soc. B 369. DOI:10.1098/rstb.2012.0394
- Friston, K. (2010). “The free-energy principle: a unified brain theory?” Nature Reviews Neuroscience 11(2), 127-138. DOI:10.1038/nrn2787
- Itti, L. & Baldi, P. (2009). “Bayesian surprise attracts human attention.” Vision Research 49(10), 1295-1306. DOI:10.1016/j.visres.2008.09.007
- Hale, J. (2001). “A Probabilistic Earley Parser as a Psycholinguistic Model.” NAACL — surprisal.
- Levy, R. (2008). “Expectation-Based Syntactic Comprehension.” Cognition 106(3), 1126-1177.
Feedback, Interaction, Joint Action
- Marcus, G. F. (1993). “Negative evidence in language acquisition.” Cognition 46(1), 53-85. DOI:10.1016/0010-0277(93)90022-N90022-N)
- Chouinard, M. M. & Clark, E. V. (2003). “Adult reformulations of child errors as negative evidence.” Journal of Child Language 30(3), 637-669. DOI:10.1017/S0305000903005701
- Clark, H. H. & Wilkes-Gibbs, D. (1986). “Referring as a collaborative process.” Cognition 22(1), 1-39. DOI:10.1016/0010-0277(86)90010-790010-7)
- Watzlawick, P., Beavin, J. H. & Jackson, D. D. (1967). Pragmatics of Human Communication. Norton — first axiom: “one cannot not communicate.” DOI:10.4324/9781315080918-7 (chap. axioms)
- Pickering, M. J. & Garrod, S. (2004). “Toward a mechanistic psychology of dialogue.” Behavioral and Brain Sciences 27(2), 169-190. DOI:10.1017/S0140525X04000056
- Keller, P. E., Novembre, G. & Hove, M. J. (2014). “Rhythm in joint action.” Phil. Trans. R. Soc. B 369(1658), 20130394. DOI:10.1098/rstb.2013.0394
Grammatical Inference and Learnability
- Gold, E. M. (1967). “Language Identification in the Limit.” Information and Control 10(5), 447-474.
- Angluin, D. (1987). “Learning Regular Sets from Queries and Counterexamples.” Information and Computation 75(2), 87-106.
- Clark, A. & Lappin, S. (2011). Linguistic Nativism and the Poverty of the Stimulus. Wiley. DOI:10.1002/9781444390568
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press.
Neural Substrate (Embodied Dimension)
- Schultz, W., Dayan, P. & Montague, P. R. (1997). “A Neural Substrate of Prediction and Reward.” Science 275(5306), 1593-1599. DOI:10.1126/science.275.5306.1593
- Salamone, J. D. & Correa, M. (2012). “The Mysterious Motivational Functions of Mesolimbic Dopamine.” Neuron 76(3), 470-485. DOI:10.1016/j.neuron.2012.10.021
- Yin, H. H. & Knowlton, B. J. (2006). “The role of the basal ganglia in habit formation.” Nature Reviews Neuroscience 7(6), 464-476. DOI:10.1038/nrn1919
- Gottlieb, J. & Oudeyer, P.-Y. (2018). “Towards a neuroscience of active sampling and curiosity.” Nature Reviews Neuroscience 19(12), 758-770. DOI:10.1038/s41583-018-0078-0
Inspiration
- Eco, U. (1979). Lector in Fabula. Bompiani — the meccanismo pigro, metaphor of the lazy text (cited as inspiration, in the context of intended communication).
Glossary
- Knowledge gradient ($\kappa$): amount of grammatical knowledge available, from 1 (known grammar, recognition) to 0 (nothing known, pure inference).
- Rate-distortion: theory (Shannon) of the minimum number of bits to transmit a message at a given fidelity. Tolerating a little loss allows for more compression.
- MDL (Minimum Description Length): criterion for choosing a model; the best one minimizes (model size) + (data encoded by it). Quantified Occam.
- CRC (cyclic redundancy check): redundant bits added to detect corruption. Removing them compresses but reduces robustness.
- Under-specification: omitting, in a message, what the receiver can reconstruct—compressing at the source.
- Surprisal (predictive surprise): $-\log_2$ of the probability an event had under the current model. In bits. Measurable without knowing the true grammar.
- Model surprise (Bayesian): magnitude of model change after an event = information gained about the grammar. In bits.
- P-chain: psycholinguistic framework (Dell & Chang) where prediction links production, comprehension, and acquisition; prediction error drives learning.
- Predictive coding / free energy: principle (Friston) according to which the brain minimizes surprise (prediction error).
- Oracle: instance that answers “is this string in the language?” (and sometimes provides counter-examples). Presupposes a form of recognition.
- Ecological oracle: here, the non-formal oracle formed by interaction feedback (repair, alignment, desynchronization), primarily implicit.
- Informant regime (vs. text): in Gold, learning with access to answers/counter-examples, more powerful than positive data alone.
- Superfinite class: class containing all finite languages and at least one infinite one; not identifiable from positives alone (Gold’s wall).
- Entrainment: synchronization of rhythmic behaviors between interacting individuals (here, in joint music).
- Communicative efficiency: pressure shaping languages toward a speaker-effort / informativeness trade-off.
- Compression rate ($R$): number of signifiers (bits) per transmitted signified. Compressing = lowering $R$ = spending less energy $E(R)$.
- Error rate / distortion ($\varepsilon$): proportion of what the receiver does not correctly reconstruct. Increases with compression $R$, decreases with shared knowledge $\kappa$.
- Extracted learning ($G$): knowledge gain $d\kappa$ derived from resolved errors. Function of $\varepsilon$ in an inverted U (neither too little nor too much) and the power of the oracle.
- Optimal error rate ($\varepsilon^{*}$): error rate that maximizes learning per unit of energy. Distinct from the communicative optimum (which minimizes error).
- Information bottleneck: formal framework (Tishby) for the trade-off between compressing a variable and information retained about another—candidate for formalizing $\varepsilon^{*}$.
- Desirable difficulty (desirable difficulties, R. & E. Bjork): observation that well-calibrated learning obstacles improve retention—the empirical idea of a non-trivial error optimum.
- Striatum / basal ganglia: brain structures (modulated by dopamine) that calculate effort cost and form habits.
- Reward prediction error: gap between expected and received reward, signaled by dopamine (Schultz); neural substrate of surprisal and update.
- Learning progress: speed at which one learns ($\approx d\kappa/dt$); models curiosity as intrinsic utility (Gottlieb & Oudeyer).
Related Links
- L20 — Inference, the third direction — Gold, gradient $\kappa$, MDL: the foundation of this essay
- L18 — The sign reversal — generating under constraint = decompression, the counterpart of inference
- L19 — The P-chain — prediction error as the engine of learning
- M10 — Induction of musical grammars — Gold, Sequitur, MDL in practice
Prerequisites: L20 (recommended), L19
Reading time: 24 min
Tags: #double-laziness #ecological-oracle #compression #rate-distortion #prediction-error #entrainment #grammatical-inference