L17) La matrice de complexité
Deux axes orthogonaux pour comprendre l’asymétrie
Dans L15, nous avons vu que la génération est en $\mathcal{O}(n)$ et le parsing en $\mathcal{O}(n^3)$ pour les grammaires context-free. Mais cette formulation est trompeuse : elle réduit chaque opération à un seul nombre. En réalité, la complexité dépend de deux axes indépendants — la classe de grammaire et la spécification de tâche. Quand on croise ces deux axes dans une matrice, un pattern émerge qui révèle le vrai mécanisme de l’asymétrie.
Où se situe cet article ?
Cet article est un approfondissement de la première dimension (D1, Complexité) de l’asymétrie génération-reconnaissance (L13, L15). Là où L15 présentait un tableau simple — $T_{\text{gen}}$ linéaire contre $T_{\text{parse}}$ qui explose — cet article déploie la complexité sur deux axes et montre pourquoi l’asymétrie n’est pas un simple écart de vitesse mais un couplage différentiel entre les deux opérations et leurs paramètres.
Pourquoi c’est important ?
Dire « générer est facile, analyser est difficile » est un slogan, pas une explication. C’est même faux dans certains cas : la génération sous contraintes peut être aussi difficile que le parsing (NP-difficile). Et le parsing de langages réguliers est aussi rapide que la génération (linéaire).
Ce qui est vrai, c’est que les deux opérations ne sont pas sensibles aux mêmes paramètres. La génération réagit au degré de contrainte qu’on lui impose. La reconnaissance réagit au pouvoir expressif de la grammaire. Cette différence de sensibilité — le couplage différentiel — est le vrai mécanisme de l’asymétrie.
L’idée en une phrase
La complexité de chaque opération est un produit de deux axes orthogonaux — classe de grammaire (Chomsky) × spécification de tâche — mais la génération est principalement sensible à l’axe des tâches tandis que la reconnaissance est principalement sensible à l’axe des grammaires.
Expliquons pas à pas
1. Les deux axes
Chaque opération — génération ou reconnaissance — opère sur une grammaire d’une certaine classe ($k$, le niveau dans la hiérarchie de Chomsky : Type 3, Type 2, Type 2+, Type 1, Type 0 — cf. L1) et avec une certaine spécification de tâche — ce qu’on lui demande de faire.
Pour la génération, la spécification de tâche va du plus libre au plus contraint :
| Niveau de tâche | Ce qu’on demande |
|---|---|
| Libre | Appliquer des règles sans objectif — explorer le langage |
| Terminante | Produire une chaîne complète (sans non-terminaux) |
| Contrainte | Produire une chaîne spécifique $w \in L(G)$ |
Pour la reconnaissance, la spécification de tâche va de la question la plus simple à la plus complète :
| Niveau de tâche | Ce qu’on demande |
|---|---|
| Appartenance | La chaîne est-elle dans le langage ? (oui/non) |
| Un arbre | Trouver une structure de dérivation |
| Tous les arbres | Énumérer toutes les structures possibles |
2. La matrice de génération
Quand on croise les 3 niveaux de tâche avec les 5 classes de grammaires, on obtient une matrice 3×5. Chaque cellule contient la complexité en temps. Colorons-la comme une carte thermique — du vert ($\mathcal{O}(n)$, rapide) au gris foncé (indécidable) :
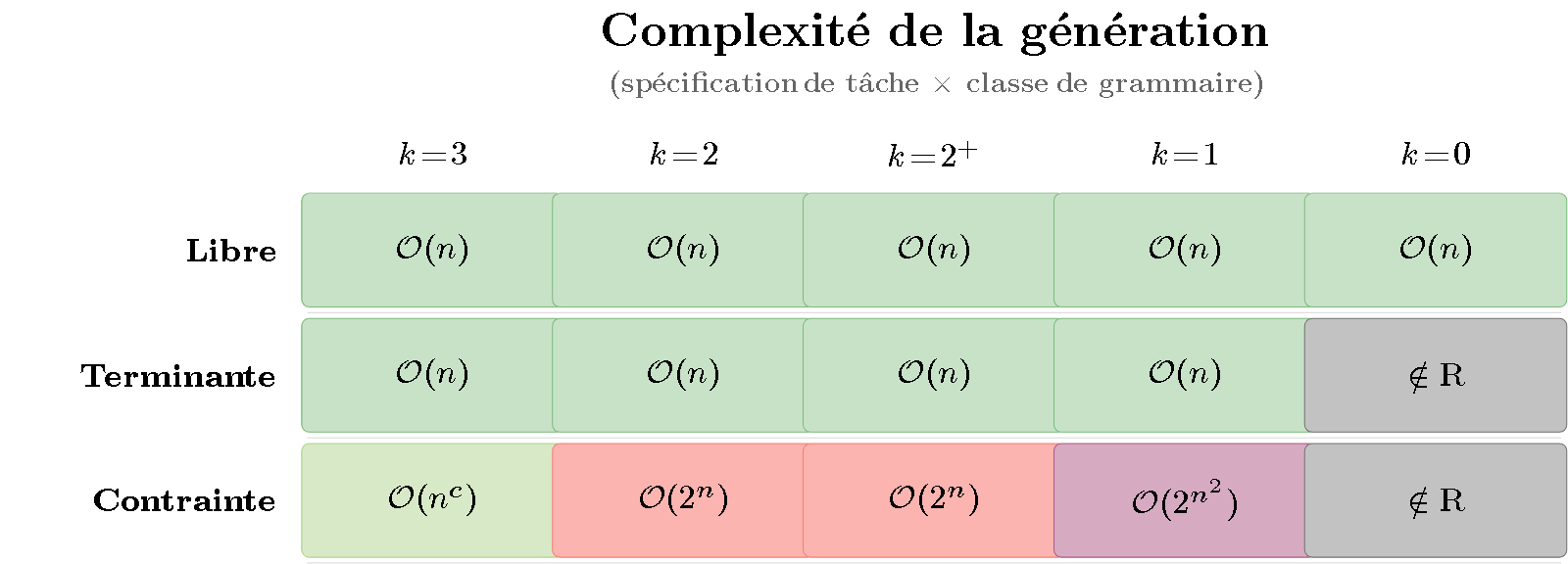
Figure 1 — Heatmap de la complexité de génération. Les lignes représentent la spécification de tâche (libre, terminante, contrainte) ; les colonnes la classe de grammaire (Type 3 à Type 0). La couleur va du vert ($\mathcal{O}(n)$, rapide) au gris foncé (indécidable). Observation clé : la couleur varie surtout le long des lignes — c’est le degré de contrainte, pas la classe de grammaire, qui détermine la difficulté.
Ce que montre la matrice :
- Ligne 1 (Libre) : tout est vert. La génération libre est linéaire quelle que soit la puissance de la grammaire — même une grammaire de Turing peut dériver librement en $\mathcal{O}(n)$.
- Ligne 2 (Terminante) : presque tout vert, sauf Type 0 (gris) — pour les grammaires récursivement énumérables, il est indécidable de savoir si une dérivation atteindra un mot terminal.
- Ligne 3 (Contrainte) : c’est ici que les couleurs chauffent. Produire une chaîne spécifique est NP-difficile dès Type 2 ($\mathcal{O}(2^n)$) et empire avec le pouvoir expressif.
Le gradient de couleur est horizontal : la difficulté varie d’une ligne à l’autre, pas d’une colonne à l’autre. La génération est sensible à la tâche.
3. La matrice de reconnaissance
Même exercice pour la reconnaissance :
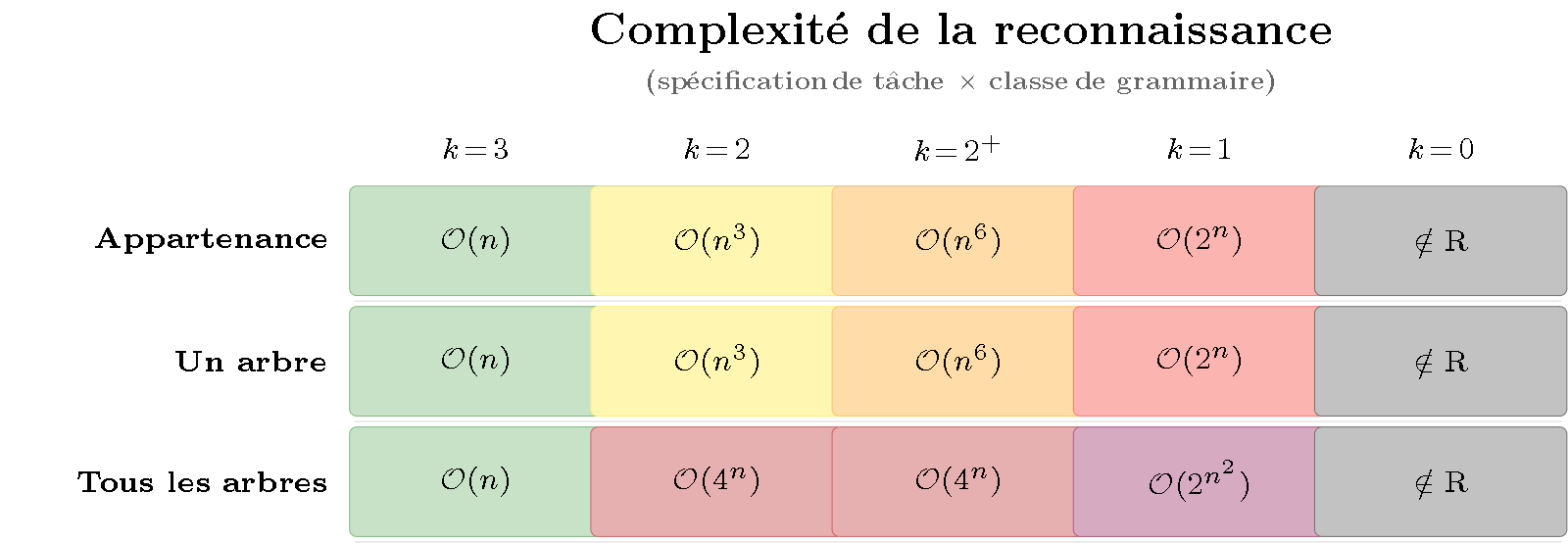
Figure 2 — Heatmap de la complexité de reconnaissance. Même structure que la Figure 1 mais pour le parsing. Observation clé : la couleur varie surtout le long des colonnes — c’est la classe de grammaire (hiérarchie de Chomsky), pas la spécification de tâche, qui détermine la difficulté.
Ce que montre la matrice :
- Colonne 1 ($k=3$, régulier) : tout est vert. Les langages réguliers se parsent aussi vite qu’ils se génèrent — pas d’asymétrie.
- Colonne 2 ($k=2$, context-free) : jaune pour l’appartenance et un arbre ($\mathcal{O}(n^3)$), rouge foncé pour tous les arbres ($\mathcal{O}(4^n)$ — les nombres de Catalan, cf. L15 §3).
- Colonnes 3-5 : le rouge et le gris dominent. Plus la grammaire est expressive, plus le parsing est coûteux — quelle que soit la spécification de tâche.
Le gradient de couleur est vertical : la difficulté varie d’une colonne à l’autre, pas d’une ligne à l’autre (sauf la troisième ligne qui ajoute l’explosion combinatoire des arbres multiples). La reconnaissance est sensible à la grammaire.
4. Le couplage différentiel
La comparaison des deux matrices fait apparaître le mécanisme fondamental :
| Axe principal de sensibilité | Axe secondaire |
|---|---|
| Génération | Spécification de tâche (lignes) |
| Reconnaissance | Classe de grammaire (colonnes) |
C’est ce que nous appelons le couplage différentiel : les deux opérations sont affectées par les deux axes, mais avec une sensibilité inversée. La génération libre reste en $\mathcal{O}(n)$ même pour une grammaire de Turing — elle est immunisée contre la montée en expressivité. Le parsing, lui, est immédiatement affecté par chaque saut dans la hiérarchie de Chomsky.
En d’autres termes :
- Augmenter le pouvoir expressif de la grammaire rend le parsing plus difficile mais laisse la génération libre intacte.
- Augmenter les contraintes sur la sortie rend la génération plus difficile mais n’affecte pas le parsing (qui est toujours contraint par l’entrée).
C’est la formalisation de l’intuition de L13 : le parser est toujours contraint (l’entrée est donnée, non négociable), tandis que le générateur peut ou non se contraindre.
5. La courbe de divergence
Les deux matrices se résument en une seule courbe quand on fixe la tâche la plus courante (appartenance pour le parsing, génération libre pour la production) et qu’on fait varier la classe de grammaire :
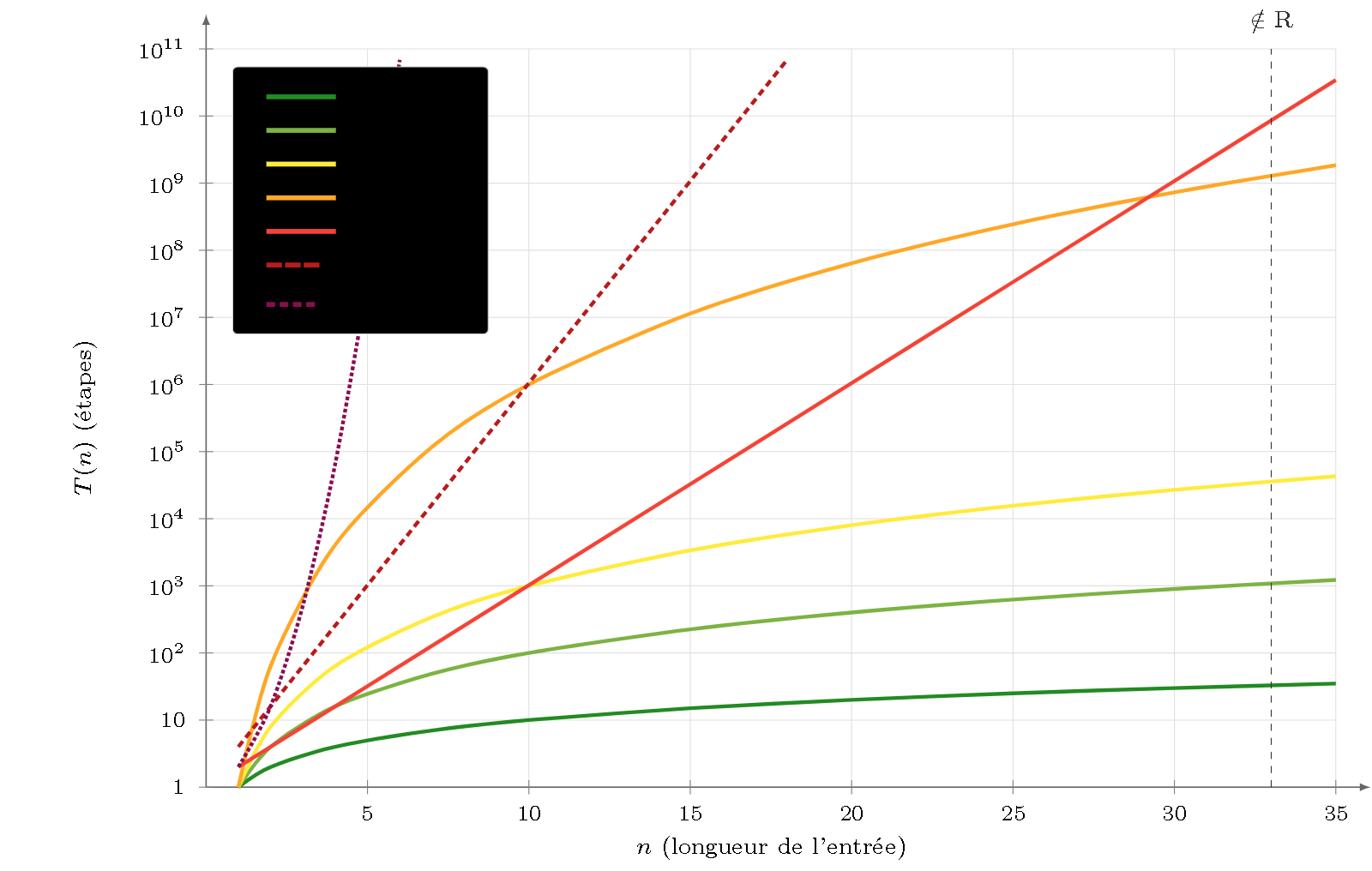
Figure 3 — L’écart de complexité (échelle semi-log). Sept courbes correspondant aux niveaux de complexité identifiés dans les heatmaps, avec la même palette de couleurs. Les bornes polynomiales apparaissent comme des droites ; les bornes exponentielles divergent. La ligne verticale tiretée marque l’indécidabilité ($\notin \mathrm{R}$).
Sur un graphe semi-logarithmique (axe vertical en $\log_{10}$), les complexités polynomiales ($n$, $n^3$, $n^6$) sont des droites dont la pente croît avec l’exposant. Les complexités exponentielles ($2^n$, $4^n$, $2^{n^2}$) divergent vers le haut. Pour une entrée de 20 symboles :
| Complexité | Opérations |
|---|---|
| $\mathcal{O}(n)$ | 20 |
| $\mathcal{O}(n^3)$ | 8 000 |
| $\mathcal{O}(n^6)$ | 64 000 000 |
| $\mathcal{O}(2^n)$ | 1 048 576 |
| $\mathcal{O}(4^n)$ | $\approx 10^{12}$ |
L’asymétrie n’est pas un facteur constant : elle croît avec le pouvoir expressif. C’est pourquoi les formalismes mildly context-sensitive ($k = 2^+$, cf. L9) — ceux qui dominent la linguistique computationnelle — se trouvent dans une zone critique : assez expressifs pour capturer les phénomènes linguistiques intéressants, mais avec un parsing en $\mathcal{O}(n^6)$ qui rend les applications à grande échelle difficiles.
6. En musique
Le couplage différentiel s’observe directement dans les systèmes musicaux :
- BP3 en mode PROD (I2) : la grammaire génère librement des séquences de bols. Quel que soit le pouvoir expressif des règles, la génération reste rapide — on est dans la première ligne de la matrice (tout vert).
- BP3 en mode ANAL : la même grammaire analyse une séquence donnée. La complexité dépend maintenant du pouvoir expressif des règles — on est dans la matrice de droite, où les colonnes déterminent la couleur.
- GTTM (M6) : pur parsing analytique. Les règles de préférence sont context-sensitive (les décisions dépendent du contexte global), ce qui place GTTM dans les colonnes droites de la matrice de reconnaissance — là où le rouge domine.
- Les générateurs neuronaux (Jukebox, MusicGen) : génération libre en $\mathcal{O}(n)$ par token, mais avec un coût d’entraînement colossal qui encode implicitement tout le travail analytique.
La matrice explique pourquoi les systèmes musicaux sont majoritairement unidirectionnels (L16) : le couplage différentiel signifie que les deux directions ont des profils de performance radicalement différents pour la même grammaire.
Ce qu’il faut retenir
- La complexité de chaque opération dépend de deux axes orthogonaux : la classe de grammaire (hiérarchie de Chomsky) et la spécification de tâche.
- La matrice de génération montre un gradient horizontal (sensible à la tâche) ; la matrice de reconnaissance montre un gradient vertical (sensible à la grammaire).
- Ce couplage différentiel est le vrai mécanisme de l’asymétrie : augmenter le pouvoir expressif pénalise le parsing mais pas la génération libre ; augmenter les contraintes pénalise la génération mais pas le parsing.
- L’asymétrie croît avec le pouvoir expressif : de nulle (Type 3) à infinie (Type 0).
- En musique, le couplage différentiel explique pourquoi la même grammaire BP3 génère rapidement (PROD) mais analyse plus lentement (ANAL).
Pour aller plus loin
Complexité computationnelle
- Aho, A.V., Sethi, R. & Ullman, J.D. (1986). Compilers: Principles, Techniques, and Tools. Addison-Wesley — complexités de CYK, Earley, LL, LR.
- Hopcroft, J.E. & Ullman, J.D. (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley — résultats fondamentaux.
- Satta, G. (1994). « Tree-Adjoining Grammar Parsing and Boolean Matrix Multiplication. » Computational Linguistics — complexité $\mathcal{O}(n^6)$ pour TAG.
Génération contrainte
- Barton, G.E., Berwick, R.C. & Ristad, E.S. (1987). Computational Complexity and Natural Language. MIT Press — preuves de NP-complétude.
- Song, L. et al. (2016). « AMR-to-text Generation as a Travelling Salesman Problem. » EMNLP — génération NP-difficile.
- Adolfi, F., Wareham, T. & van Rooij, I. (2022). « Intractability in Parsing and Segmentation. » — NP-dureté intrinsèque.
Dans le corpus
- L1 — Les niveaux de la hiérarchie et leurs automates
- L9 — Type 2+ : TAG, CCG, MCFG
- L13 — Vue d’ensemble de l’asymétrie (6 dimensions)
- L15 — Les formalisations mathématiques des 6 dimensions
- L16 — Pourquoi la bidirectionnalité n’a pas été transférée
- M6 — GTTM : le paradigme analytique appliqué
Glossaire
- Classe de grammaire ($k$) : Le niveau dans la hiérarchie de Chomsky. $k = 3$ (régulier), $k = 2$ (context-free), $k = 2^+$ (mildly context-sensitive), $k = 1$ (context-sensitive), $k = 0$ (récursivement énumérable).
- Couplage différentiel : Le fait que la génération et la reconnaissance sont toutes deux sensibles aux deux axes (classe de grammaire et spécification de tâche), mais avec une sensibilité principale inversée. La génération réagit d’abord à la tâche ; la reconnaissance réagit d’abord à la grammaire.
- Génération contrainte : Génération qui doit produire une chaîne spécifique $w$, pas n’importe quelle chaîne du langage. Peut être NP-difficile dès Type 2.
- Génération libre : Génération sans objectif de sortie — on applique les règles et on observe le résultat. Toujours en $\mathcal{O}(n)$, quelle que soit la classe de grammaire.
- Heatmap (carte thermique) : Représentation visuelle d’une matrice où la couleur code l’intensité d’une valeur. Ici, le vert code la complexité faible ($\mathcal{O}(n)$) et le gris foncé code l’indécidabilité.
- Spécification de tâche : Ce qu’on demande à l’opération de produire. Pour la génération : libre, terminante, contrainte. Pour la reconnaissance : appartenance, un arbre, tous les arbres.
Prérequis : L1, L13, L15
Temps de lecture : 12 min
Tags : #complexité #asymétrie #heatmap #couplage-différentiel #Chomsky #matrice
← Retour à l’index