B8) Deux directions, trois modes
Un compositeur écrit de la musique. Un musicologue l’analyse. Un pédagogue veut vérifier la conformité d’une performance. BP3 fait tout cela — avec la même grammaire.
Où se situe cet article ?
Dans L13, nous avons découvert que toute grammaire formelle a deux faces : elle peut produire des phrases (génération) ou les analyser (reconnaissance). Nous avons vu que ces deux directions sont asymétriques — plus facile de produire que d’analyser.
Cet article montre comment BP3 (Bol Processor 3, cf. I2) met cette dualité en pratique. Contrairement à la plupart des systèmes musicaux formels qui ne fonctionnent que dans une direction, BP3 a été conçu dès l’origine pour opérer dans trois modes : produire, analyser, et explorer exhaustivement les structures possibles de la grammaire.
Pourquoi c’est important ?
La plupart des outils musicaux formels sont unidirectionnels (quelques exemples) :
- GTTM (M6) : analytique seulement — il assigne des structures à des pièces existantes, mais ne compose rien
- EMI (David Cope) : génératif seulement — il compose à partir de patterns extraits, mais n’offre pas de mode d’analyse formel
- SuperCollider (I3) : génératif seulement — il produit du son, il ne l’analyse pas structurellement
D’après nos études comparatives, BP3 est a priori le seul système grammatical où la même grammaire sert aux deux directions — produire et analyser — au sein du même formalisme :
| Système | Génère ? | Analyse formelle ? | Infère ? | Même formalisme ? |
|---|---|---|---|---|
| GTTM (Lerdahl & Jackendoff) | Non | Oui (règles de préférence) | Non | — |
| Steedman CCG (jazz) | Oui (1984) | Oui, parsing (2014) | Non | Oui (2/3) |
| EMI (David Cope) | Oui | Non (pattern matching) | Oui (extraction) | Non (processus séparés) |
| GF (Ranta) | Oui | Oui (parsing) | Non | Oui (2/3) |
| Continuator (Pachet) | Oui | Non (pas de membership test) | Oui (Markov) | Non |
| BP3 (Bel & Kippen) | Oui (PROD) | Oui (ANAL) | QAVAID† | Oui (2/3) + QAVAID† |
† QAVAID = programme Prolog II séparé (Bel & Kippen, 1988-1990), jamais intégré à BP3, abandonné. L’écosystème Bel-Kippen couvrait les 3 directions, mais BP3 lui-même en couvre 2.
C’est cette double capacité — produire et analyser avec la même grammaire — qui a permis à Bernard Bel et James Kippen de mener leur projet ethnomusicologique sur le tabla de Lucknow. Avec QAVAID, un programme séparé écrit en Prolog II, ils visaient aussi l’inférence grammaticale — mais cette troisième direction est restée expérimentale [BelKippen1992a].
L’idée en une phrase
BP3 utilise la même grammaire dans trois modes : produire de la musique (PROD), vérifier qu’une séquence est grammaticale (ANAL), et cataloguer exhaustivement les formes structurelles possibles (TEMP).
Expliquons pas à pas
1. Mode PROD — le compositeur
Le mode PROD (production) est celui que nous connaissons déjà : la grammaire génère des séquences musicales par dérivation. C’est le sujet des articles B3 à B6.
En logique, ce mode correspond au modus ponens (mode d’affirmation) — le raisonnement direct :
Prémisse : La grammaire G a pour règle S → A B
Prémisse : On veut dériver S
Conclusion : On obtient A B
Le modus ponens avance : « si la grammaire dit que S peut devenir A B, alors je produis A B ». C’est le raisonnement du compositeur : je connais les règles, je les applique pour créer.
En BP3, le mode PROD utilise les cinq modes de dérivation (B3) — ORD, RND, LIN, SUB, SUB1 — avec les probabilités (B1), les flags (B4), les variables et les homomorphismes (B6).
Exemple :
gram#1[1] S --> |x| - |x| - |x|
gram#1[2] |x| --> dha tirakita dhin dhin
gram#1[3] |x| --> tin ta dha ge na
En mode PROD, cette grammaire produit un tihāī (cadence où un motif est répété trois fois pour tomber sur sam, le premier temps du cycle tāla — cf. B6).
La traduction de ces constructions en SuperCollider — flags, poids décrémentaux, Prout et embedInStream — est détaillée dans B7.
2. Mode ANAL — le musicologue
[!warning] État d’implémentation (mars 2026)
Le mode ANAL est défini dans le code source de BP3 (
#define ANAL 0dansBP2.h) et était pleinement fonctionnel dans BP2. Cependant, ANAL n’est pas encore implémenté dans BP3 (cf. bolprocessor.org : « This feature is not (yet) implemented in BP3 »). Bernard Bel travaille activement à sa restauration. La description ci-dessous est basée sur le fonctionnement documenté de BP2 et sur le code source — elle décrit le comportement prévu, pas l’état actuel de BP3.
Le mode ANAL (analysis) inverse la direction : au lieu de produire, la grammaire teste si une séquence donnée appartient au langage. C’est le test d’appartenance (membership test) — la question « cette séquence est-elle grammaticale ? »
En logique, ce mode correspond au modus tollens (mode de négation) — le raisonnement inverse :
Prémisse : La grammaire G engendre le langage L(G)
Observation : La séquence s n'est PAS dans L(G)
Conclusion : s n'est pas une production valide de G
Le modus tollens recule : « si la séquence ne correspond à aucune dérivation possible de la grammaire, alors elle n’est pas grammaticale ». C’est le raisonnement du musicologue : je reçois une performance, je vérifie si elle respecte les règles.
Encart : Modus ponens et modus tollens — le compositeur et le critique
Imaginez un tabliste et un guru (maître) :
- Le tabliste (modus ponens / PROD) : « Les règles disent que je peux jouer dha tirakita dhin dhin. Je le joue. »
- Le guru (modus tollens / ANAL) : « Mon élève a joué dha tirakita tin na. Est-ce que ça correspond à une dérivation valide de la grammaire du kayda ? »
Le guru ne compose pas — il évalue. BP3 permet de formaliser les deux rôles avec la même grammaire [KippenBel1989b].
Comment fonctionne le mode ANAL
Le processus d’analyse repose sur la correspondance de gabarits (template matching). Le code source révèle qu’ANAL possède deux stratégies de reconnaissance :
- Stratégie directe (toujours disponible) : BP3 reçoit une séquence à analyser et tente de la faire correspondre aux règles de la grammaire par recherche dans l’espace de dérivation
- Stratégie par templates (optionnelle) : si des templates ont été pré-calculés par le mode TEMP (cf. §3), BP3 propose à l’utilisateur de les utiliser. Il vérifie alors d’abord si la forme de la séquence correspond à un squelette connu, avant de tenter le parsing complet
Dans les deux cas, si une correspondance est trouvée, la séquence est acceptée comme appartenant au langage
En termes shannoniens, le mode ANAL est le décodeur de la chaîne de communication musicale (cf. L13). Il opère en deux temps : d’abord séparer le signal du bruit — ce qui est grammatical de ce qui ne l’est pas —, puis faire émerger le sens de l’information — assigner une structure, une interprétation à la séquence acceptée. Et comme tout décodage, cette opération n’est pas univoque : une même séquence peut admettre plusieurs analyses valides, plusieurs arbres de dérivation. L’ambiguïté n’est pas un accident — c’est une propriété fondamentale de la reconnaissance.
Note : membership test ≠ identification de langage
Le mode ANAL teste l’appartenance d’une séquence à une seule grammaire — celle qui est chargée. Il ne permet pas de tester une séquence contre une famille de grammaires pour déterminer à laquelle elle appartient. C’est la différence entre le membership test (« s ∈ L(G) ? ») et le language identification (« à quel L(Gᵢ) appartient s ? »). Ce second problème — « cette performance relève-t-elle du kayda X ou du kayda Y ? » — est un problème de classification, plus difficile et non couvert par BP3 dans son état actuel.
Dans le mode ANAL, les wildcards (?1, ?2 — cf. B6) prennent tout leur sens, ce sont les outils de pattern matching qui permettent à la grammaire de « chercher » les motifs dans une séquence reçue.
Wildcards en mode analytique
Les wildcards de BP3 sont analogues aux groupes de capture des expressions régulières (regex), mais opèrent dans le cadre des grammaires formelles :
| Syntaxe | Rôle en PROD | Rôle en ANAL |
|---|---|---|
? |
Placeholder anonyme | Accepte n’importe quel terminal |
?1 |
Capture nommée | Capture un motif et vérifie sa cohérence |
?1 ... ?1 |
Réplication du motif capturé | Vérifie que le même motif apparaît aux deux positions |
Exemple en mode ANAL :
gram#1[1] S --> ?1 - ?1 - ?1
Cette règle, en mode ANAL, signifie : « la séquence à analyser doit être de la forme X – X – X, où X est le même motif aux trois positions ». C’est exactement le test de tihāī — la grammaire vérifie que la cadence respecte la structure de triple répétition.
En mode PROD, la même règle génère un motif pour ?1 et le réplique aux trois positions — c’est un générateur de tihāī. En mode ANAL, elle capture le motif à la première occurrence et vérifie qu’il est identique aux deux autres — c’est un vérificateur de tihāī. Les deux directions fonctionnent, avec des rôles complémentaires : l’homomorphisme de B6 garantit la cohérence dans les deux sens.
Apprentissage des poids
Un aspect remarquable du mode ANAL est l’apprentissage des poids. Quand une séquence est analysée avec succès, les règles qui ont été utilisées pendant la reconnaissance voient leur poids incrémentés (B4). Autrement dit :
- Les règles fréquemment confirmées par les exemples deviennent plus probables
- Les règles rarement confirmées perdent en probabilité relative
- La grammaire s’adapte progressivement au corpus analysé
C’est un mécanisme d’apprentissage embryonnaire : la grammaire ne change pas ses règles, mais ajuste leur fréquence relative en fonction des données. On passe d’une PCFG (Probabilistic Context-Free Grammar — B1) « a priori » à une PCFG calibrée par l’expérience.
3. Mode TEMP — le cartographe des structures
Le mode TEMP (producing templates) répond à une question simple : quelles formes structurelles cette grammaire peut-elle produire ?
Ce que fait TEMP
Imaginez une grammaire qui peut produire des centaines de variations d’un kayda. Chaque variation a une forme différente — un agencement structurel de motifs — mais les motifs eux-mêmes varient. TEMP explore exhaustivement toutes ces formes possibles.
Pour cela, TEMP dérive la grammaire de manière exhaustive — il explore toutes les structures possibles, là où PROD en tire une au hasard selon les poids. Il ne s’intéresse pas aux terminaux (les bols concrets), seulement aux squelettes : où sont les positions, combien de motifs, quelle imbrication.
Le résultat est un catalogue de toutes les formes structurelles que la grammaire autorise — ses templates — affiché directement dans la fenêtre grammaire sous une section TEMPLATES:.
Un outil de design en soi
TEMP est accessible comme commande indépendante dans BP3 — pas besoin de lancer une analyse pour s’en servir. C’est d’abord un outil pour le concepteur de grammaires :
- Explorer : « quelles formes ma grammaire peut-elle produire ? » — voir d’un coup l’espace structurel complet, là où PROD n’en montre qu’un échantillon aléatoire
- Vérifier : « ma grammaire couvre-t-elle bien toutes les structures que je voulais ? » — détecter des formes manquantes ou des dérivations inattendues
- Debugger : quand une grammaire produit des résultats surprenants, TEMP permet de comprendre pourquoi en montrant toutes les structures possibles
C’est l’équivalent d’un mode « aperçu avant impression » pour les grammaires : on voit la forme sans le contenu.
TEMP et ANAL : une relation optionnelle
TEMP n’est pas un prérequis d’ANAL. Le code source de BP3 le confirme : ANAL possède deux chemins de reconnaissance indépendants :
- Sans templates : ANAL fait la reconnaissance directement depuis les règles de la grammaire — un parsing classique par recherche dans l’espace de dérivation
- Avec templates : si des templates ont été pré-calculés par TEMP, BP3 propose à l’utilisateur de les utiliser (« Use templates? »). ANAL peut alors vérifier d’abord si la forme de la séquence correspond à un squelette connu, avant de tenter le parsing complet
La seconde stratégie est plus rapide — comparer une forme à un catalogue de squelettes est moins coûteux qu’un parsing complet —, mais elle est optionnelle. ANAL fonctionne parfaitement sans que TEMP ait jamais été lancé.
TEMP est donc mieux décrit comme un outil d’exploration structurelle qui peut aussi accélérer l’analyse, plutôt que comme un simple auxiliaire d’ANAL.
Deux différences clés avec PROD
TEMP est exhaustif, PROD est stochastique. PROD respecte les poids des règles (B1) et produit une séquence choisie probabilistiquement. TEMP ignore les poids et énumère toutes les dérivations structurelles possibles.
TEMP s’arrête à la structure, PROD va jusqu’aux terminaux. PROD dérive toutes les règles jusqu’à obtenir des bols concrets (dha tirakita dhin dhin). TEMP s’arrête aux squelettes abstraits — la forme sans le contenu.
C’est ici qu’un trait unique de BP3 prend tout son sens : les flèches directionnelles. Chaque règle porte une annotation de direction — --> (production seulement), <-- (analyse seulement), ou <--> (bidirectionnelle). Cette distinction, absente des formalismes grammaticaux classiques, permet à une même grammaire de contrôler finement quelles règles sont actives dans chaque mode.
Encart : QAVAID — la troisième direction avortée
Au-delà des trois modes de BP3, Bel et Kippen ont développé QAVAID (Question Answer Validated Analytical Inference Device, قواعد qavā’id = « grammaire » en arabe/ourdou) — un programme Prolog II séparé pour l’inférence grammaticale interactive (1988-1990). Le musicien servait d’oracle : la machine proposait des généralisations à partir d’exemples de tabla, et le guru les acceptait ou les rejetait. L’algorithme construisait un automate fini presque minimal par fusion d’états [Bel1990-JFA].
QAVAID n’a jamais été intégré à BP3. Le projet a été abandonné : les machines étaient trop lentes, les corpus insuffisants, et James Kippen est parti à l’Université de Toronto. Comme Kippen le résume en 2021 : « it only proved that it would be feasible » [Kippen2021].
Le code est archivé sur bolprocessor.org/misc/QAVAID/. L’ambition reste : les approches ML contemporaines pourraient reprendre le flambeau de l’inférence grammaticale musicale interactive (cf. M10).
4. Le cycle complet
La puissance de BP3 réside dans la boucle entre ses modes :
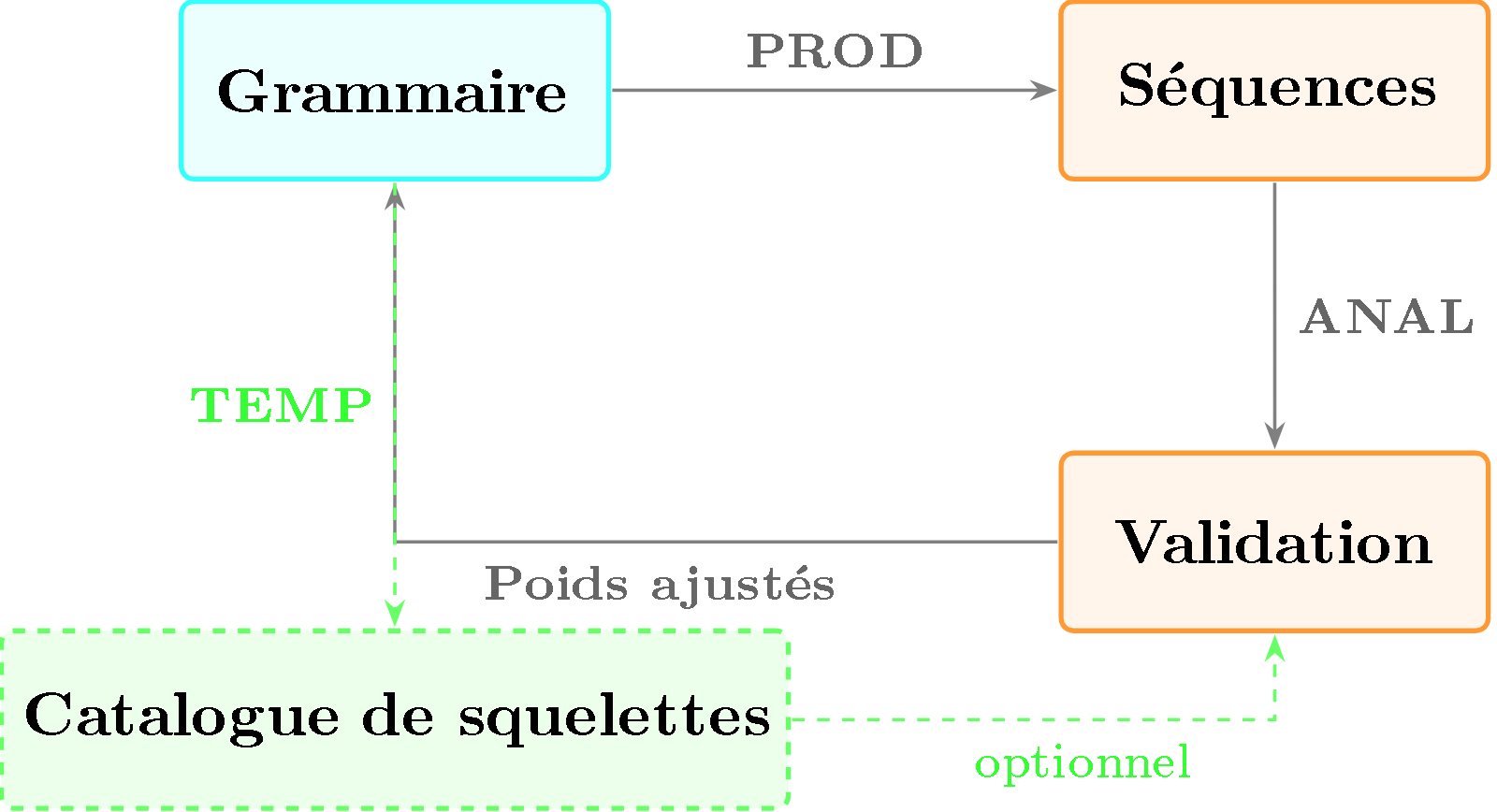
Figure 1 — Cycle complet de BP3. PROD genere des sequences, ANAL les valide et ajuste les poids, TEMP fournit optionnellement un catalogue de squelettes structurels a ANAL.
Le cycle réel que BP3 implémente :
- Le mode PROD génère des séquences musicales par dérivation stochastique
- Le mode ANAL vérifie si de nouveaux exemples appartiennent au langage (optionnellement assisté par des templates TEMP)
- Les poids des règles confirmées par l’analyse sont incrémentés — la grammaire s’adapte
- Retour à l’étape 2 : les nouvelles productions reflètent les poids ajustés
C’est un processus d’analysis-by-synthesis appliqué à la musique — le même paradigme que Halle et Stevens (1962) ont proposé pour la perception de la parole, mais ici incarné dans un système interactif homme-machine [KippenBel1989].
QAVAID visait à ajouter une troisième direction — l’inférence — pour fermer complètement le cycle : construire automatiquement la grammaire à partir d’exemples, plutôt que de l’écrire à la main. Ce programme séparé en Prolog II n’a pas abouti (cf. encart ci-dessus), mais l’idée reste pertinente.
Le test ultime — le round-trip test — est : « les séquences produites par la grammaire sont-elles acceptées comme valides par le musicien expert ? ». Si oui, la grammaire a capturé quelque chose des règles tacites de l’improvisation.
Trois cadres théoriques : Chomsky, Shannon, Morris
Les trois modes de BP3 ne sont pas une invention isolée. Ils s’inscrivent dans trois cadres théoriques complémentaires — un triptyque qui éclaire chacun une dimension différente de la bidirectionnalité.
Chomsky : la complexité structurelle
Les trois modes opèrent sur des grammaires classées dans la hiérarchie de Chomsky (L1). BP3 est un formalisme Type 2+ — context-free augmenté par des flags, des poids et des homomorphismes qui le poussent vers les langages mildly context-sensitive (L9).
Cette position dans la hiérarchie contraint ce que chaque mode peut faire. L’asymétrie computationnelle décrite dans L13 s’applique directement :
- En mode PROD, la dérivation est linéaire en la longueur de la sortie — chaque pas est un choix local
- En mode ANAL, le test d’appartenance est au minimum O(n³) pour les CFG — et potentiellement plus coûteux pour les extensions de BP3
Produire est intrinsèquement plus facile qu’analyser. Ce n’est pas un défaut d’implémentation — c’est une propriété mathématique du formalisme.
Shannon : encodeur, canal, décodeur
Le modèle de communication de Claude Shannon (1948) cartographie directement les modes de BP3 :

Figure 2 — Modes BP3 vus a travers le modele de Shannon. PROD encode l’intention musicale en sequence de symboles, ANAL decode la sequence pour en extraire la structure.
PROD est l’encodeur : il transforme une intention musicale — le sens capturé par la grammaire — en une séquence de symboles. Chaque dérivation est un acte d’encodage : le choix d’une forme parmi les possibles.
ANAL est le décodeur : il reçoit la séquence et doit en extraire le sens. Comme nous l’avons vu plus haut, ce décodage opère en deux temps — séparer le signal du bruit (le test d’appartenance : est-ce grammatical ?), puis faire émerger le sens de l’information (l’assignation d’une structure : quel arbre de dérivation ?). Et cette reconstruction d’intention est intrinsèquement ambiguë : une même séquence de bols peut correspondre à plusieurs dérivations valides, comme une même phrase peut avoir plusieurs analyses syntaxiques.
TEMP construit le dictionnaire du décodeur : en énumérant exhaustivement les templates structurels possibles, il fournit à ANAL une table de référence optionnelle qui peut accélérer le décodage — comme un dictionnaire de codebook qui permet au récepteur de reconnaître plus vite les messages valides. Mais ANAL peut aussi décoder sans dictionnaire, directement depuis les règles.
Le bruit du canal, en musique, prend des formes multiples : variations d’interprétation, erreurs de transcription, ambiguïté entre bols résonants et secs, liberté stylistique du musicien. L’asymétrie fondamentale de Shannon — il est plus facile d’encoder que de décoder un message bruité — est exactement l’asymétrie PROD/ANAL.
Morris : la correction du cycle
En 1973, James Morris a formalisé la correction d’un compilateur par un diagramme commutatif (L11) : compiler puis exécuter le programme cible doit donner le même résultat qu’interpréter directement le source.
Le cycle que BP3 implémente réellement — vu dans la section précédente — est un test de commutativité de Morris appliqué à la musique :
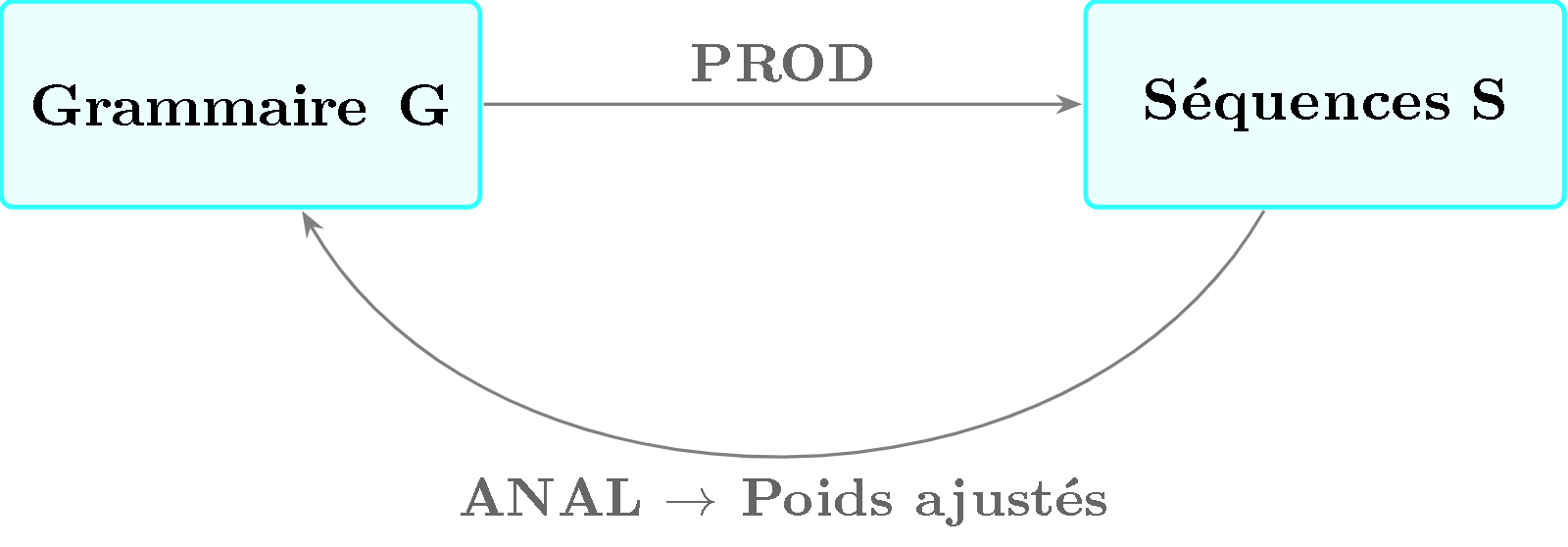
Figure 3 — Diagramme commutatif de Morris applique a BP3. Le cycle PROD puis ANAL avec ajustement des poids doit converger : les sequences produites par G doivent etre acceptees comme grammaticales, et les poids ajustes doivent conduire a des productions jugees valides par l’expert.
Le diagramme commute si : les séquences produites par la grammaire G sont acceptées comme grammaticales par ANAL, et les poids ajustés par ANAL conduisent PROD à produire des séquences que le musicien expert juge valides. C’est la version musicale de la preuve de correction d’un compilateur.
QAVAID visait à enrichir ce cycle en ajoutant l’inférence — construire G automatiquement plutôt que manuellement. Si cette troisième direction avait abouti, le diagramme aurait eu un chemin supplémentaire : exemples → QAVAID → grammaire inférée G₂, avec le test L(G₂) ≈ L(G₁). Mais dans BP3 tel qu’il existe, le cycle se ferme par l’ajustement des poids, pas par l’inférence.
La polymétrie comme concurrence
Quand les modes opèrent sur des structures polymétriques ({v1, v2} — cf. B5), ils entrent dans le domaine de la concurrence formalisé dans L12 :
- PROD sur la polymétrie = générer une composition parallèle au sens de CCS ($v_1 \mid v_2$) ou de CSP ($v_1 \parallel_{\text{downbeat}} v_2$). Le producteur crée deux flux temporels indépendants qui se synchronisent aux downbeats.
- ANAL sur la polymétrie = parser des flux concurrents — un problème sensiblement plus difficile que le parsing séquentiel. Il faut vérifier que chaque voix est grammaticale et que leurs relations temporelles sont cohérentes.
La polymétrie transforme le parsing d’un problème séquentiel (une chaîne de symboles) en un problème de vérification de systèmes concurrents — un saut de complexité que les algèbres de processus et les réseaux de Petri permettent de formaliser.
Position dans la série B
| Article | Direction | Constructions couvertes |
|---|---|---|
| B1 – B6 | → PROD (production) | Règles, modes, poids, flags, polymétrie, variables, homomorphismes |
| B7 | → PROD → SC | Traduction en SuperCollider |
| B8 (cet article) | ← ANAL + TEMP (exploration structurelle) | Test d’appartenance, wildcards analytiques, templates structurels |
Les articles B1 à B7 couvrent la direction production de BP3. Cet article complète le tableau en explorant la direction inverse — l’analyse — et le mode TEMP d’exploration structurelle, montrant pourquoi BP3 est un système fondamentalement bidirectionnel, pas juste un générateur.
Ce qu’il faut retenir
- BP3 a trois modes d’utilisation d’une grammaire : PROD (produire), ANAL (analyser), TEMP (explorer exhaustivement les structures possibles). Ces trois modes couvrent deux directions : production et analyse.
- Le mode PROD (modus ponens) est le compositeur — il produit des séquences par dérivation stochastique.
- Le mode ANAL (modus tollens) est le musicologue — il sépare signal et bruit, puis fait émerger le sens avec ses ambiguïtés d’interprétation.
- Le mode TEMP est le cartographe des structures — il énumère exhaustivement tous les squelettes structurels possibles (en ignorant les poids). ANAL peut optionnellement utiliser ce catalogue pour accélérer la reconnaissance, mais fonctionne aussi sans.
- Les wildcards (
?1,?2) fonctionnent dans les deux directions : en mode PROD, ils génèrent et répliquent (générateur de tihāī) ; en mode ANAL, ils capturent et vérifient (vérificateur de tihāī). - Les poids des règles s’ajustent automatiquement en mode ANAL — la grammaire apprend de ce qu’elle analyse.
- QAVAID (qavā’id = grammaire en arabe/ourdou) était un programme Prolog II séparé (1988-1990), jamais intégré à BP3, visant l’inférence grammaticale interactive. Le projet a été abandonné.
- Le cycle réel de BP3 — PROD → ANAL → poids ajustés → re-PROD — fait de BP3 un cas rare de système grammatical musical bidirectionnel.
- Le triptyque Chomsky-Shannon-Morris éclaire les dimensions : Chomsky contraint la complexité (PROD linéaire vs ANAL cubique), Shannon cartographie les directions (encodeur/décodeur/bruit), Morris formalise la correction du cycle (le round-trip test comme commutativité).
- La polymétrie transforme chaque mode en problème de concurrence (L12) : produire
{v1, v2}c’est générer une composition parallèle, l’analyser c’est parser des flux concurrents.
Pour aller plus loin
Publications clés
- Kippen, J. & Bel, B. (1989). « Can the Computer Help Resolve the Problem of Ethnographic Description? » Anthropological Quarterly, 62(3). — Discussion explicite du modus ponens et du modus tollens dans le contexte BP.
- Bel, B. & Kippen, J. (1992). « Modelling Music with Grammars: Formal Language Representation in the Bol Processor. » — L’article le plus cité (46 citations), détaillant le membership test.
- Bel, B. (1990). Acquisition et représentation de connaissances en musique. Thèse de doctorat, Université Aix-Marseille III. — La fondation théorique complète.
Contexte théorique
- Shannon, C.E. (1948). « A Mathematical Theory of Communication. » Bell System Technical Journal, 27(3). — Le modèle encodeur/canal/décodeur qui fonde l’analogie PROD/ANAL.
- Morris, J.H. (1973). « Types are not sets. » POPL ’73. — Le diagramme commutatif qui formalise la correction des compilateurs — et du cycle PROD→ANAL→poids→re-PROD.
- Strzalkowski, T. (1993). Reversible Grammar in Natural Language Processing. Springer. — Grammaires réversibles.
QAVAID et inférence grammaticale
- Kippen, J. & Bel, B. (1989). « The Identification and Modelling of a Percussion ‘Language,’ and the Emergence of Musical Concepts in a Machine-Learning Experimental Set-up. » Computers and the Humanities, 23(3). — L’article fondateur de QAVAID (programme Prolog II séparé).
- Bel, B. (1990). « Inférence de langages réguliers. » Journées Françaises de l’Apprentissage, Lannion. — La méthode formelle d’inférence par automates finis.
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press. — Référence sur l’inférence grammaticale.
Dans le corpus
- L13 — La dualité génération/reconnaissance : l’asymétrie fondamentale
- L12 — Réseaux de Petri et algèbres de processus : la concurrence formalisée
- L11 — Le diagramme de Morris et la sémantique traductionnelle
- B3 — Les cinq modes de dérivation (direction production)
- B5 — Polymétrie : les structures concurrentes que les modes traitent
- B6 — Variables, wildcards, homomorphismes (constructions avancées)
- B1 — Grammaires probabilistes (les poids qui s’ajustent en mode ANAL)
- M10 — L’inférence grammaticale en musique (à venir)
Glossaire
- ANAL (mode) : Mode analytique de BP3 — la grammaire teste si une séquence appartient au langage. Utilise le template matching et les wildcards. Correspond au modus tollens.
- Analysis-by-synthesis (analyse par synthèse) : Paradigme où la reconnaissance utilise la génération comme sous-processus interne. Le récepteur génère des hypothèses et les compare au signal reçu (cf. L13).
- Automate fini presque minimal : Représentation compacte d’un langage régulier construite par QAVAID (programme Prolog II séparé) à partir d’exemples. « Presque » minimal car la minimisation exacte peut sur-généraliser.
- Kayda : Composition de tabla avec un thème fixe et des variations systématiques. Le cadre typique pour l’inférence grammaticale avec QAVAID.
- Membership test (test d’appartenance) : Le problème de décision : « cette séquence appartient-elle au langage engendré par cette grammaire ? ». En BP3, résolu par template matching en mode ANAL.
- Modus ponens : Raisonnement logique direct : « si A implique B, et A est vrai, alors B est vrai ». En BP3 : si la grammaire a la règle S → A B, on peut produire A B. Direction : PROD.
- Modus tollens : Raisonnement logique inverse : « si A implique B, et B est faux, alors A est faux ». En BP3 : si une séquence ne correspond à aucune dérivation de la grammaire, elle n’est pas grammaticale. Direction : ANAL.
- Oracle : Dans le contexte de l’inférence grammaticale, l’expert (le musicien) qui valide ou rejette les généralisations proposées par le système.
- PROD (mode) : Mode production de BP3 — la grammaire génère des séquences musicales par dérivation. Correspond au modus ponens.
- QAVAID (Question Answer Validated Analytical Inference Device) : Programme Prolog II séparé (1988-1990) pour l’inférence grammaticale interactive, développé par Bel & Kippen. Jamais intégré à BP3, abandonné. Le nom signifie aussi « grammaire » (قواعد) en arabe/ourdou.
- Round-trip test : Test de validation où les séquences produites par une grammaire inférée sont soumises au musicien qui a fourni les exemples originaux. Si elles sont acceptées, la grammaire a capturé les règles tacites. Équivalent musical du test de commutativité de Morris.
- TEMP (mode) : Mode d’exploration structurelle de BP3 — énumère exhaustivement tous les squelettes structurels que la grammaire peut produire (en ignorant les poids). Le catalogue résultant peut optionnellement être utilisé par ANAL comme stratégie de reconnaissance alternative. TEMP n’est pas un prérequis d’ANAL. En termes shannoniens : construit le dictionnaire du décodeur.
- Template matching (correspondance de gabarits) : Mécanisme central du mode ANAL : superposer une séquence à analyser sur les patrons définis par les règles de la grammaire.
- Triptyque Chomsky-Shannon-Morris : Trois cadres théoriques complémentaires pour comprendre les modes de BP3. Chomsky = complexité structurelle (hiérarchie), Shannon = encodage/décodage (direction), Morris = correction du cycle (commutativité).
- Diagramme de Morris : Diagramme commutatif (Morris, 1973) qui formalise la correction d’un compilateur : le résultat doit être le même qu’on passe par le chemin « compiler puis exécuter » ou « interpréter directement ». Appliqué au cycle PROD→ANAL→poids ajustés→re-PROD.
Prérequis : B3, B6, L13
Temps de lecture : 15 min
Tags : #BP3 #production #analyse #TEMP #wildcards #tabla