L1) La hiérarchie de Chomsky expliquée simplement
Peut-on classer tous les langages de programmation, les langues humaines et même les notations musicales selon leur complexité ? Noam Chomsky a proposé une réponse en 1956.
Où se situe cet article ?
Cet article ouvre la série Langages formels (L). Il pose les fondations théoriques de toute la série en classifiant les langages par complexité selon les quatre niveaux classiques de Chomsky. Les articles L2 à L7 et la série B (BP3) s’appuient sur cette classification. Nous verrons dans L9 que cette hiérarchie en quatre niveaux est en réalité une simplification — entre le Type 2 et le Type 1 se cache une zone intermédiaire fascinante, que nous appelons Type 2+ (mildly context-sensitive), cruciale pour la musique et le langage naturel.
Pourquoi c’est important ?
Imaginez que vous deviez écrire un programme capable de comprendre du texte. Pas n’importe quel texte : parfois une simple recherche de mots-clés, parfois du code Python, parfois du français parlé. Intuitivement, on sent que ces trois tâches n’ont pas la même difficulté. Mais comment quantifier cette différence ?
La hiérarchie de Chomsky apporte une réponse mathématique à cette question. Elle classe les langages (au sens large : langues naturelles, langages de programmation, notations) en quatre niveaux selon la puissance nécessaire pour les reconnaître ou les générer. Cette classification a des conséquences pratiques directes : elle détermine quel type d’outil utiliser pour analyser un langage donné.
Pour le projet BP2SC (Bol Processor to SuperCollider) — un transpileur (traducteur de code source à code source, voir B7) de notation musicale — cette hiérarchie nous aide à comprendre pourquoi certaines constructions de BP3 (Bol Processor 3, voir I2) nécessitent des techniques d’analyse plus sophistiquées que d’autres.
L’idée en une phrase
La hiérarchie de Chomsky classe les langages en quatre niveaux (Type 0 à Type 3) selon la complexité des règles nécessaires pour les décrire.
Les quatre niveaux, du plus simple au plus complexe
Type 3 : Langages réguliers — « La mémoire d’un poisson rouge »
Ce qu’ils peuvent faire : Reconnaître des motifs simples, répétitifs, sans imbrication.
L’automate fini : la machine qui reconnaît ces langages
Un automate fini est une machine abstraite très simple : elle possède un nombre fixe d’états (comme des cases sur un plateau de jeu) et des transitions entre ces états (comme des flèches indiquant où aller selon ce qu’on lit). Elle lit une entrée caractère par caractère, change d’état à chaque lecture, et à la fin dit « accepté » ou « rejeté » selon l’état où elle se trouve.
Analogie : le tourniquet de métro. Un tourniquet a deux états : bloqué et débloqué. Si vous insérez un ticket, il passe de bloqué à débloqué. Si vous poussez, il passe de débloqué à bloqué (et vous laisse passer). Le tourniquet ne sait pas combien de personnes sont passées avant vous — il connaît seulement son état actuel. C’est exactement ainsi que fonctionne un automate fini : il réagit à chaque entrée en changeant d’état, sans mémoire du passé.
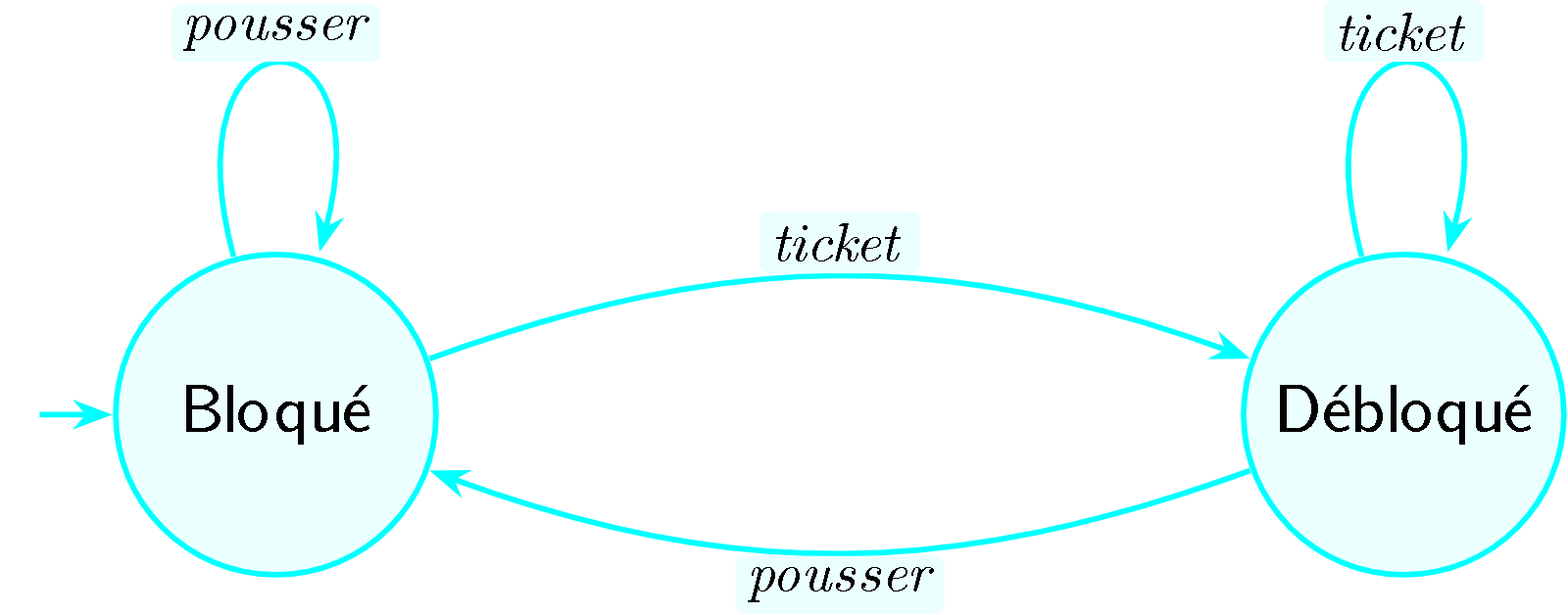
Figure 1 — Automate fini du tourniquet de métro. Deux états (Bloqué, Débloqué) et quatre transitions. La machine ne retient que son état courant, sans mémoire du passé.
Les expressions régulières : l’outil pratique
Une expression régulière (ou regex) est une notation compacte pour décrire un motif textuel. Elle définit exactement ce qu’un automate fini peut reconnaître, mais sous une forme lisible par les humains.
Exemple concret :
Valider un numéro de téléphone français : 06 12 34 56 78
Regex : 0[67] (\d{2} ){4}
Ici, 0[67] signifie « 0 suivi de 6 ou 7 », \d{2} signifie « deux chiffres », et {4} signifie « répété 4 fois ».
Ce que les langages réguliers peuvent décrire
- Identifiants de variables (
[a-zA-Z_][a-zA-Z0-9_]*) - Formats de dates simples (
\d{4}-\d{2}-\d{2}) - Mots-clés d’un langage
- Adresses email (forme simplifiée)
Limitation fondamentale : pas de mémoire = pas de comptage
Un langage régulier ne peut pas « compter ». Il ne peut pas vérifier qu’il y a autant de parenthèses ouvrantes que fermantes, car cela nécessiterait de se souvenir du nombre de ( déjà vus.
Ce qu’on ne peut PAS décrire :
aⁿbⁿ(n fois ‘a’ suivi de n fois ‘b’) — il faudrait compter les ‘a’- Les parenthèses correctement appariées —
((()))est valide,(()ne l’est pas - Les balises HTML imbriquées —
<div><p></p></div>nécessite de savoir quelle balise fermer
Type 2 : Langages context-free — « La pile magique »
Ce qu’ils peuvent faire : Gérer les structures imbriquées, les récursions, les parenthèses.
L’automate à pile : ajouter une mémoire
Un automate à pile est un automate fini augmenté d’une pile — une mémoire de type « dernier entré, premier sorti » (LIFO). Contrairement à l’automate fini qui ne retient qu’un état, l’automate à pile peut empiler des symboles pour « se souvenir » de ce qu’il a vu, puis les dépiler quand c’est nécessaire.
Pile vs File : deux façons de gérer une mémoire
Structure Principe Analogie Acronyme Pile (stack) Dernier entré, premier sorti Une pile d’assiettes : on prend toujours celle du dessus LIFO (Last In, First Out) File (queue) Premier entré, premier sorti Une file d’attente : le premier arrivé est servi en premier FIFO (First In, First Out) >
L’automate à pile utilise une pile car c’est ce dont on a besoin pour gérer l’imbrication : quand on ouvre une parenthèse(, on l’empile ; quand on ferme), on dépile la dernière parenthèse ouverte — pas la première.
Exemple concret : Pour vérifier que les parenthèses sont équilibrées dans ((a + b) * c) :
- Lecture de
(→ empile( - Lecture de
(→ empile((pile :(() - Lecture de
)→ dépile (pile :() - Lecture de
)→ dépile (pile vide) - Fin de lecture, pile vide → accepté
Les grammaires context-free (CFG) : décrire la structure
Une grammaire context-free (CFG) est un ensemble de règles de réécriture où chaque règle a la forme $A \to \gamma$ : un seul symbole $A$ (appelé non-terminal) peut être remplacé par une séquence $\gamma$, indépendamment de ce qui l’entoure. C’est ce qui fait qu’elle est « sans contexte » (context-free).
Exemple — Les expressions arithmétiques :
Grammaire :
E → E + T | T
T → T * F | F
F → ( E ) | nombre
Permet de parser : 2 + 3 * (4 + 5)
Le symbole | signifie « ou » : la règle E → E + T | T se lit « E peut devenir soit E + T, soit simplement T« . C’est une notation compacte pour écrire deux règles en une.
La règle E → E + T dit simplement « un E peut toujours être remplacé par E + T », peu importe ce qu’il y a avant ou après.
Les parseurs : transformer du texte en structure
Un parseur est un programme qui analyse un texte selon une grammaire et construit une structure (souvent un arbre). Il existe deux grandes familles :
- Parseurs descendants (top-down) : partent du symbole de départ et essaient de dériver le texte. Exemple : les parseurs récursifs descendants, où chaque règle de la grammaire devient une fonction qui s’appelle récursivement.
- Parseurs ascendants (bottom-up) : partent du texte et essaient de remonter vers le symbole de départ en réduisant des groupes de symboles. Exemple : les parseurs LR (Left-to-right, Rightmost derivation, lecture de gauche à droite avec dérivation la plus à droite).
Ce que les langages context-free peuvent décrire
- La plupart des langages de programmation (syntaxe)
- HTML (structure des balises)
- JSON
- Les expressions mathématiques
- La structure de base des phrases (sujet-verbe-complément)
Ce qu’on ne peut PAS décrire
- Vérifier qu’une variable est déclarée avant d’être utilisée — cela nécessite de « se souvenir » de toutes les déclarations précédentes
- Les accords grammaticaux complexes — en français, « les chats mangent » mais « le chat mange » : l’accord dépend d’un élément distant
- Les références croisées — quand un élément du texte fait référence à un autre élément défini ailleurs (comme une note de bas de page qui renvoie à une référence bibliographique, ou un lien hypertexte vers une ancre)
Type 1 : Langages context-sensitive — « Le contexte compte »
Ce qu’ils peuvent faire : Les règles de réécriture peuvent dépendre du contexte.
Formalisme :
Une règle comme $\alpha A \beta \to \alpha \gamma \beta$ signifie « A peut devenir $\gamma$, mais seulement si A est entouré de $\alpha$ à gauche et $\beta$ à droite ».
Exemple classique :
L = { a^n b^n c^n | n ≥ 1 }
= { abc, aabbcc, aaabbbccc, ... }
Ce langage simple (« autant de a, puis autant de b, puis autant de c ») est impossible à décrire avec une grammaire context-free. Il faut pouvoir « compter » sur deux compteurs simultanés.
Analogie :
Si les langages context-free sont comme des phrases où chaque mot peut être remplacé indépendamment, les langages context-sensitive sont comme des phrases où le remplacement dépend des mots voisins — comme l’accord en genre et en nombre en français.
Applications :
- Analyse sémantique des langages de programmation
- Vérification de types
- Certaines structures des langues naturelles
Type 0 : Langages récursivement énumérables — « Tout est possible, mais… »
Ce qu’ils peuvent faire : Décrire n’importe quel processus calculable.
La machine de Turing : le modèle universel de calcul
Une machine de Turing est un modèle théorique inventé par Alan Turing en 1936. Elle se compose de :
- Un ruban infini divisé en cases, chacune contenant un symbole
- Une tête de lecture/écriture qui peut lire, écrire et se déplacer d’une case à gauche ou à droite
- Un ensemble fini d’états et de règles de transition
Contrairement à l’automate à pile (mémoire limitée à une pile), la machine de Turing a accès à une mémoire illimitée et peut y accéder dans n’importe quel ordre. C’est le modèle le plus puissant : tout ce qui est calculable peut l’être par une machine de Turing.
Analogie : Imaginez un employé de bureau avec un rouleau de papier infini, un crayon et une gomme. Il peut écrire, effacer, avancer, reculer, et suivre des instructions. C’est essentiellement ce que fait un ordinateur.
Le problème : la non-terminaison
Pour ces langages, il n’existe pas toujours d’algorithme qui s’arrête pour dire « oui » ou « non ». Un analyseur peut tourner indéfiniment sur certaines entrées — et on ne peut pas savoir à l’avance s’il va s’arrêter ou non (c’est le fameux « problème de l’arrêt », démontré indécidable par Turing).
En pratique
On n’utilise presque jamais ce niveau directement en informatique. C’est le domaine de la théorie de la calculabilité et des problèmes indécidables. Mais comprendre cette limite est important : elle nous dit qu’il existe des problèmes qu’aucun programme ne peut résoudre dans tous les cas.
Tableau récapitulatif
| Type | Nom | Automate | Outil pratique | Mémoire | Peut décrire | Ne peut pas décrire |
|---|---|---|---|---|---|---|
| 3 | Régulier | Automate fini | Regex | Aucune (juste l’état courant) | Motifs simples, tokens, formats | Parenthèses imbriquées, aⁿbⁿ |
| 2 | Context-free | Automate à pile | Parseurs (ANTLR, Lark, Yacc) | Une pile (LIFO) | JSON, HTML, syntaxe des langages | Références croisées, accords distants |
| 1 | Context-sensitive | Machine linéairement bornée | Analyseurs sémantiques | Mémoire proportionnelle à l’entrée | aⁿbⁿcⁿ, vérification de types |
Problèmes indécidables |
| 0 | Récursivement énumérable | Machine de Turing | Tout programme | Mémoire illimitée | Tout ce qui est calculable | Problème de l’arrêt |
Forme des règles de production
| Type | Forme des règles | Signification |
|---|---|---|
| 3 | $A \to aB$ ou $A \to a$ | Un non-terminal donne un terminal + éventuellement un non-terminal |
| 2 | $A \to \gamma$ | Un non-terminal donne n’importe quelle séquence |
| 1 | $\alpha A \beta \to \alpha \gamma \beta$ avec $\lvert\gamma\rvert \geq 1$ | Réécriture dépendante du contexte, jamais contractante |
| 0 | $\alpha \to \beta$ | N’importe quelle réécriture |
Inclusion stricte
$\text{Type 3} \subset \text{Type 2} \subset \text{Type 1} \subset \text{Type 0}$
Tout langage régulier est context-free.
Tout langage context-free est context-sensitive.
Mais l’inverse est faux.
Autrement dit : un outil qui reconnaît les langages de Type 2 reconnaît aussi tous les langages de Type 3, mais l’inverse n’est pas vrai.
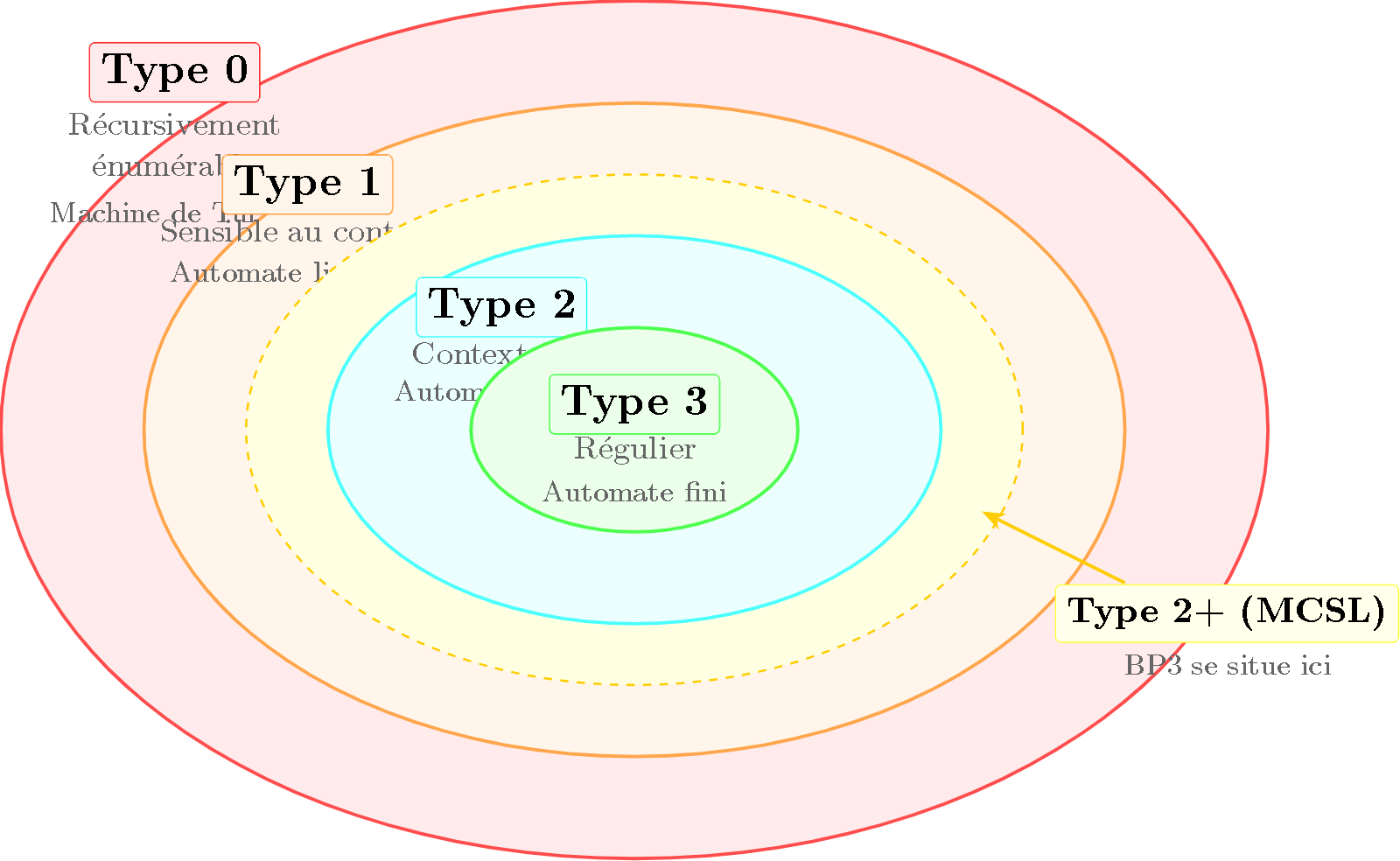
Figure 2 — Les quatre niveaux de la hiérarchie de Chomsky en ellipses concentriques, avec la zone intermédiaire Type 2+ (MCSL, mildly context-sensitive languages) en pointillés entre Type 2 et Type 1. BP3 se situe dans cette zone.
Note : Cette présentation en quatre niveaux est une simplification. Entre le Type 2 (context-free) et le Type 1 (context-sensitive), il existe en réalité une zone intermédiaire riche et structurée — les langages Type 2+ (mildly context-sensitive) — où vivent les formalismes les plus utiles pour la linguistique et la musique, dont BP3. C’est le sujet de L9.
Et BP3 dans tout ça ?
Le langage BP3 (Bol Processor) est particulièrement intéressant car il se situe dans la zone Type 2+ — entre le Type 2 pur et le Type 1.
Sa syntaxe (la structure des fichiers de grammaire) est context-free (Type 2) : on peut la décrire avec une grammaire EBNF (Extended Backus-Naur Form, voir L3) standard, et un parseur classique suffit.
Sa sémantique (ce que les règles signifient lors de l’exécution) est Type 2+ (mildly context-sensitive, voir L9). Pourquoi ?
- Les règles à contexte : BP3 permet d’écrire des règles comme :
|o| |miny| --> |o1| |miny|
Ici, |o| n’est réécrit que si |miny| est présent à côté. C’est exactement la définition d’une règle context-sensitive.
- Les flags : Des variables comme
/Ideas/modifient le comportement selon l’état global :
/Ideas/ S --> A B /Ideas-1/
La règle ne s’applique que si Ideas > 0, puis décrémente le compteur.
- Les poids dynamiques : Les poids comme
<50-12>changent à chaque utilisation, créant une dépendance temporelle.
Cependant, BP3 reste au niveau Type 2+ (et non pleinement Type 1) car :
- Le contexte est toujours local (symboles adjacents)
- Il n’y a pas de règles contractantes (la sortie est au moins aussi longue que l’entrée)
- En pratique, les programmes terminent toujours
Cette position Type 2+ explique pourquoi le transpileur BP2SC utilise un parseur context-free pour la syntaxe, mais doit générer du code SuperCollider avec des routines (Prout, un Pattern qui évalue une fonction à chaque appel) pour capturer les comportements mildly context-sensitive à l’exécution.
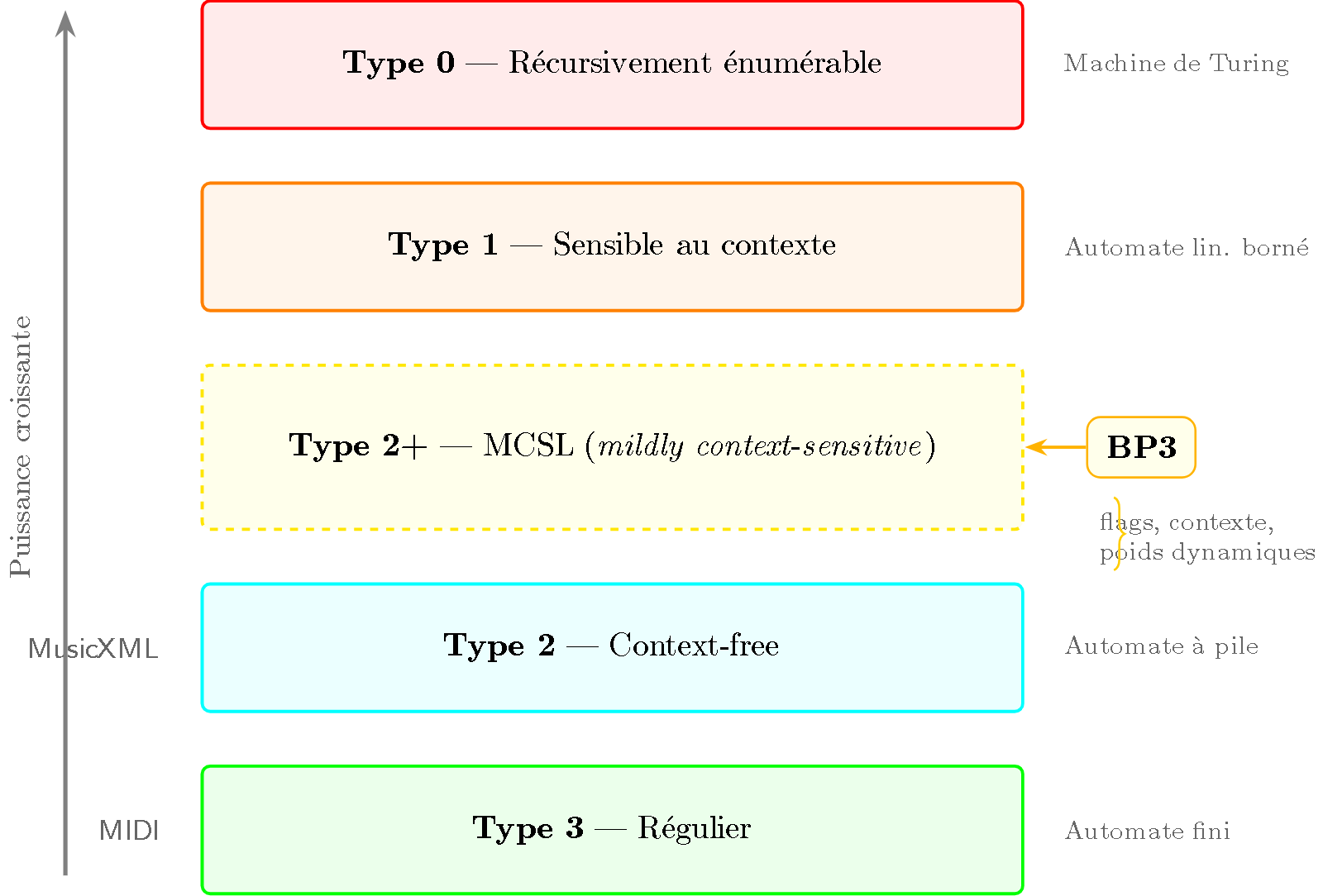
Figure 3 — Position de BP3 dans la hiérarchie de Chomsky. La zone MCSL (Type 2+, en pointillés) se situe entre le Type 2 (context-free) et le Type 1 (context-sensitive). BP3 y est placé grâce à ses flags, ses règles contextuelles et ses poids dynamiques, qui dépassent les capacités d’une grammaire context-free pure.
Ce qu’il faut retenir
- Type 3 (régulier) : Pas de mémoire. Parfait pour les motifs simples. → Regex.
- Type 2 (context-free) : Une pile pour gérer l’imbrication. Suffisant pour la syntaxe de la plupart des langages. → Parseurs classiques.
- Type 2+ (mildly context-sensitive) : Entre Type 2 et Type 1 — contexte local, sans explosion combinatoire. C’est là que se situe BP3 (voir L9).
- Type 1 (context-sensitive) : Le contexte influence les règles. Nécessaire pour la sémantique et les langues naturelles.
- Type 0 (récursivement énumérable) : La puissance maximale, mais pas toujours décidable. Rarement utilisé en pratique.
- En pratique : La plupart des langages de programmation ont une syntaxe Type 2 mais une sémantique qui nécessite des analyses supplémentaires — souvent au niveau Type 2+.
Pour aller plus loin
- Livre fondateur : Hopcroft, Motwani & Ullman, Introduction to Automata Theory, Languages, and Computation
- Article original : Chomsky, N. (1956). « Three models for the description of language »
- Visualisation interactive : The Chomsky Hierarchy
Glossaire
- Automate fini : Machine abstraite avec un nombre fini d’états, sans mémoire externe. Lit une entrée caractère par caractère et change d’état selon des règles de transition.
- Automate à pile : Automate fini augmenté d’une pile (mémoire LIFO). Peut empiler et dépiler des symboles, ce qui permet de gérer l’imbrication.
- Context-free : Se dit d’une grammaire dont les règles peuvent s’appliquer indépendamment du contexte (ce qui entoure le symbole à réécrire).
- Expression régulière (regex) : Notation compacte pour décrire des motifs textuels. Équivalente en puissance à un automate fini.
- Grammaire : Ensemble de règles pour générer ou reconnaître un langage. Définie par des symboles terminaux, non-terminaux et des règles de production.
- Grammaire context-free (CFG) : Grammaire dont toutes les règles ont la forme $A \to \gamma$ (un seul non-terminal à gauche).
- Langage formel : Ensemble de chaînes de symboles définies par des règles précises.
- Machine de Turing : Modèle théorique de calcul avec un ruban infini, une tête de lecture/écriture et des règles de transition. Peut calculer tout ce qui est calculable.
- Non-terminal : Symbole intermédiaire dans une grammaire, destiné à être remplacé par d’autres symboles.
- Parseur : Programme qui analyse un texte selon une grammaire et construit une structure (arbre de syntaxe).
- Parseur ascendant : Parseur qui part du texte et remonte vers le symbole de départ en réduisant des groupes de symboles.
- Parseur descendant : Parseur qui part du symbole de départ et essaie de dériver le texte en appliquant les règles.
- Références croisées : Liens entre éléments d’un texte où un élément fait référence à un autre défini ailleurs (ex: liens hypertextes, notes de bas de page).
- Règle de production : Règle de la forme $A \to \gamma$ indiquant comment réécrire un symbole.
- Terminal : Symbole final dans une grammaire, qui apparaît dans le résultat (par opposition aux non-terminaux).
Prérequis : Aucun
Temps de lecture : 10 min
Tags : #chomsky #langages-formels #automates #grammaires
Prochain article : L2 — Grammaires context-free : la base de tout