L20) Inference
The Third Direction
When the Grammar Itself is Unknown
Generating assumes that the rules are known. Recognizing too. But what happens when we only have examples — and we have to guess the rules? This third use of a grammar is the most difficult of the three. To the point that from positive examples alone, it is simply impossible.
Where Does This Article Fit In?
L13 established the triad: a grammar can be used to generate, to recognize, or to infer. Previous articles explored the first two directions. This one tackles the third — the least studied, the hardest — and shows that it is not a separate field, but the extreme end of a continuum where recognition occupies the other end. This is dimension D5 of the research article that this series popularizes.
Why Is This Important?
Grammatical inference is the problem of acquisition: how a child learns their language, how a system discovers the structure of a corpus without being given it. In music, it is also the computational analyst’s dream: making the grammar of a style emerge from a corpus of works (M10).
However, this problem has a deceptive reputation. We imagine it as “difficult but feasible.” Theory says otherwise: in its purest framework, it is impossible — and the loopholes that make it practicable reveal exactly what must be known in advance in order to learn.
The Idea in One Sentence
Inference is not a separate operation but the extreme case of recognition when knowledge of the grammar drops to zero — a regime where Gold’s theorem forbids learning from positive examples alone, and where learning amounts to compressing.
Explaining Step by Step
1. Three Uses, Not Two
Reminder from L13:
| Operation | Given | Sought |
|---|---|---|
| Generation | the grammar $G$ | a string $s$ |
| Recognition | $G$ + a string $s$ | the structure of $s$ |
| Inference | a corpus $\{s_1, \dots, s_k\}$ | the grammar $G$ |
The difference is obvious: in the first two, the grammar is known. In the third, it is precisely what we are looking for. Inference presupposes nothing — neither the grammar nor the structure. Everything is to be discovered.
2. Inference as the Extreme Case of Recognition
Rather than opposing recognition and inference, we can place them on the same axis: that of available grammatical knowledge, which we will denote as $\kappa$ (kappa).
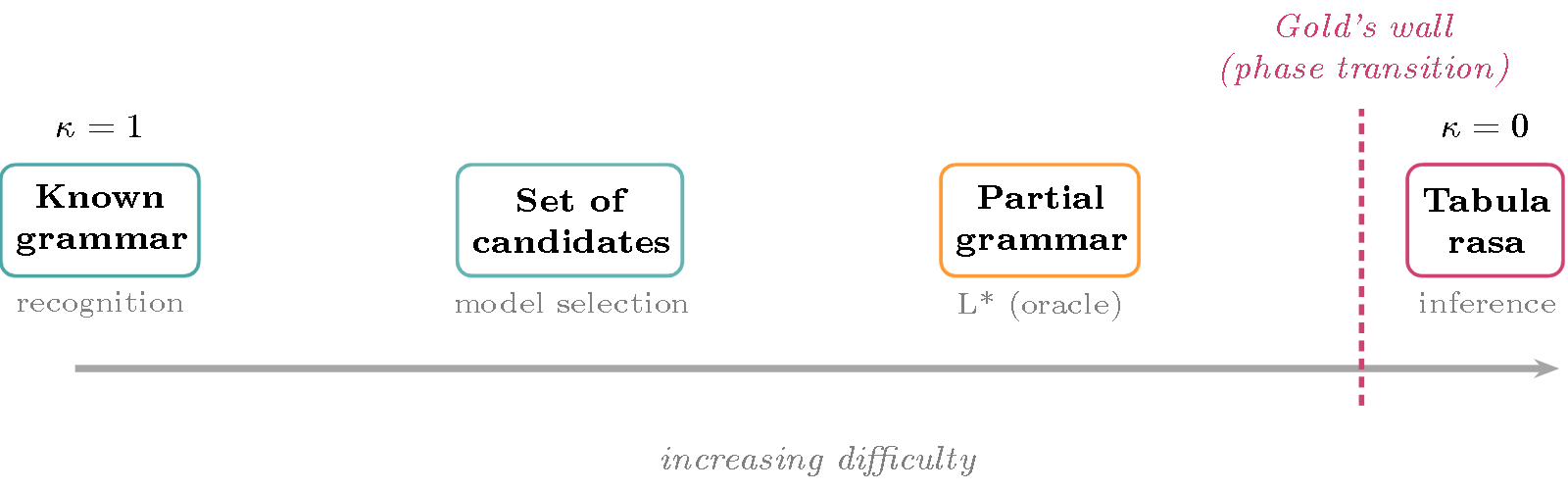
Figure 1 — The knowledge gradient $\kappa$. On the left ($\kappa = 1$), the grammar is fully known: this is standard recognition. On the right ($\kappa = 0$), no prior knowledge: this is pure inference. In between are intermediate regimes (set of candidate grammars, partial grammar with oracle). Gold’s wall marks a phase transition near $\kappa = 0$: just before it, learning remains possible in principle; at $\kappa = 0$, it becomes impossible for rich classes.
Inference is therefore not “something else” than recognition: it is what it becomes when all prior knowledge is removed. And this retreat is not gradual — it hits a wall.
3. Gold’s Theorem: Impossibility
In 1967, E. Mark Gold demonstrated a foundational result, identification in the limit:
Theorem (Gold, 1967). Let there be a class of languages containing all finite languages and at least one infinite language (a so-called superfinite class). Then this class is not identifiable in the limit from positive data alone: no algorithm can guarantee convergence to the correct grammar by seeing only valid examples.
Decrypting — “identification in the limit”. The learner receives examples one by one and proposes a grammar after each. They “identify in the limit” if they eventually, after a finite number of examples, propose the correct grammar and no longer change it. Gold proves that for interesting classes (which include regular languages and beyond), no learner can guarantee this.
Why? Because with positive examples alone, nothing ever prevents overgeneralization: if we have seen ab, aabb, aaabbb, should we conjecture $\{a^n b^n\}$, or $\{a^m b^n\}$, or “all strings”? Without counter-examples (strings outside the language), we cannot decide. This is the phase transition in Figure 1: a hint of prior knowledge makes learning possible; zero knowledge makes it impossible.
4. Why It Is Qualitatively Harder
The gap between recognition and inference is deeper than that between generation and recognition. Two results quantify this.
Pitt & Warmuth (1993): the problem of the smallest deterministic finite automaton (DFA) consistent with the data is not only NP-hard — it is not approximable within any polynomial. Even finding an approximate solution is out of reach.
Kearns & Valiant (1994): learning DFAs in the PAC framework is as difficult as breaking RSA encryption. In other words, an efficient learner would provide an efficient algorithm for breaking public-key cryptography — which we hold to be impossible. This is a cryptographic lower bound on the difficulty of inference.
Decrypting — PAC. Probably Approximately Correct: a learning framework where one asks for an approximately correct hypothesis with high probability. This is the standard framework of learning theory.
Where parsing is polynomial for common grammars, inference hits walls of impossibility and cryptography. It is not “slower”: it is of a different nature.
5. Loopholes — and What They Cost
Inference is therefore impossible within Gold’s framework. But we do learn languages, and machines do induce models. How? By changing the framework — and each change reveals what must be known in advance.
- The probabilistic / Bayesian framework. If we learn stochastic grammars (PCFG — see B1) with a prior distribution, this prior breaks the symmetry that Gold exploited: it penalizes overly general grammars. Learning becomes possible in principle (de la Higuera 2010, ch. 16), but the computational cost remains prohibitive for large grammars.
- The membership oracle. Angluin’s L\ algorithm (1987) efficiently learns regular languages — but it requires an oracle* that answers “is this string in the language?”. Yet answering this question is… recognition. Efficient inference presupposes recognition. We are at the intermediate $\kappa$ point in Figure 1, not at $\kappa = 0$.
Every loophole confirms the lesson: we do not learn from nothing. A bias (the prior) or a recognition capability (the oracle) is required.
6. Inferring Is Compressing
There is an elegant way to understand why inference is the inverse of generation. The MDL principle (Minimum Description Length, Rissanen 1978; Grünwald 2007) reformulates learning as compression: the best grammar is the one that minimizes the total description = size of the grammar + size of the data encoded with it.
Gregory Chaitin states it bluntly:
“A theory is good to the extent that it compresses the data into a much smaller set of theoretical assumptions. The greater the compression, the better!”
— Chaitin (2005)
Hence a clear symmetry with L18:
- Generating = decompressing: deploying a compact description (the grammar) into data (strings).
- Inferring = compressing: finding the compact description that accounts for the data.
And compressing is notoriously more difficult than decompressing. The compression/decompression asymmetry is another manifestation of the same divide — the one that runs through this entire article.
7. In Music: The Ear That Learns a Style
Musical grammatical inference is the inverse problem of composition by grammar. Instead of writing the rules of a style and generating, we start from a corpus (improvisations, a repertoire) and infer the rules. This is the subject of M10: Gold, Sequitur, MDL, COSIATEC, and Bernard Bel’s QAVAID system for bol analysis.
Gold’s wall is concrete here: a corpus consists of positive examples (what was played), rarely explicit counter-examples (what would be “wrong” in the style). Hence the difficulty of inferring a style grammar without a strong bias — exactly what theory predicts.
And the human ear? It manages because it is never at $\kappa = 0$: it arrives with biases (preference for regularity, tonal expectations — see L19) and an implicit oracle (the feeling that “it sounds right” or “wrong”). The musical learner does not infer in a vacuum: they infer from a rich $\kappa > 0$.
Key Takeaways
- Inference is the third use of a grammar: guessing the rules from examples alone.
- It is not a separate field but the extreme case of recognition, at the end of the knowledge gradient $\kappa$ (from known grammar to tabula rasa).
- Gold’s theorem (1967): from positive data alone, rich classes are not identifiable — a phase transition, not a gradual degradation.
- It is qualitatively harder: non-approximable (Pitt & Warmuth), as difficult as breaking RSA (Kearns & Valiant).
- The loopholes (Bayesian prior, L* membership oracle) confirm that we do not learn from nothing: a bias or a recognition capability is required.
- Inferring = compressing (MDL); generating = decompressing. The same asymmetry, seen from the perspective of information theory.
- In music, Gold’s wall explains the difficulty of inducing a style grammar; the human ear escapes it because it is never at $\kappa = 0$.
To Go Further
Grammatical Inference
- Gold, E.M. (1967). “Language Identification in the Limit.” Information and Control 10(5), 447-474 — the impossibility theorem.
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press — the field’s reference.
- de la Higuera, C. (2005). “A Bibliographical Study of Grammatical Inference.” Pattern Recognition 38(9), 1332-1348. DOI:10.1016/j.patcog.2005.01.003
- Angluin, D. (1987). “Learning Regular Sets from Queries and Counterexamples.” Information and Computation 75(2), 87-106 — the L* algorithm.
Hardness Bounds
- Pitt, L. & Warmuth, M.K. (1993). “The Minimum Consistent DFA Problem Cannot Be Approximated within Any Polynomial.” Journal of the ACM 40(1), 95-142.
- Kearns, M. & Valiant, L. (1994). “Cryptographic Limitations on Learning Boolean Formulae and Finite Automata.” Journal of the ACM 41(1), 67-95.
Compression and MDL
- Rissanen, J. (1978). “Modeling by Shortest Data Description.” Automatica 14(5), 465-471.
- Grünwald, P. (2007). The Minimum Description Length Principle. MIT Press.
- Chaitin, G.J. (2005). Meta Math!: The Quest for Omega. Pantheon Books.
The Popularized Research Article
- Peyrichou, R. (2026). The Generation-Recognition Asymmetry… §4.5 develops inference as dimension D5 and the knowledge gradient. arXiv preprint:2603.10139 — https://arxiv.org/abs/2603.10139
Within the Corpus
- L13 — The three uses of a grammar
- M10 — Musical grammar induction (Gold, Sequitur, MDL, QAVAID)
- L18 — Generation = decompression, the counterpart of inference
- L19 — Error prediction as a driver of learning
- B1 — Probabilistic grammars
Glossary
- Grammatical inference (induction): discovering a grammar from a corpus of examples, without it being given.
- Identification in the limit: Gold’s criterion; the learner converges to the correct grammar after a finite number of examples and no longer changes it.
- Superfinite class: a class of languages containing all finite languages and at least one infinite one; not identifiable from positive data alone.
- Positive data: examples belonging to the language (without explicit counter-examples of what is excluded).
- Knowledge gradient ($\kappa$): the amount of available grammatical knowledge, from 1 (known grammar, recognition) to 0 (tabula rasa, inference).
- PAC (Probably Approximately Correct): a learning framework requiring an approximately correct hypothesis with high probability.
- Membership oracle: a procedure answering “is this string in the language?”; required by L*, thus presupposing recognition.
- MDL (Minimum Description Length): the principle that the best model minimizes the total size (model + encoded data). Learning = compressing.
Links in the Series
- L13 — Generating or recognizing — the triad and dimension D5
- M10 — Induction of musical grammars — inference applied to music
- L18 — The sign reversal — compression vs decompression
- L19 — The P-chain — learning through error prediction
Prerequisites: L13, L1
Reading time: 11 min
Tags: #grammatical-inference #Gold #MDL #compression #learning #knowledge-gradient