L13) Générer ou reconnaître
La dualité des grammaires formelles
Une grammaire ne sert pas qu’à produire des phrases. Elle peut aussi les analyser. Mais ces deux usages — génération et reconnaissance — ne sont ni symétriques ni équivalents. Cette asymétrie, rarement discutée, est pourtant au cœur de la musique.
Où se situe cet article ?
Dans L1, nous avons découvert la hiérarchie des langages formels. Dans L2, nous avons appris à construire des grammaires qui produisent des phrases par dérivation. Mais nous avons toujours travaillé dans une seule direction : du sens vers les phrases.
Cet article pose une question rarement formulée : que se passe-t-il quand on inverse la direction ? Quand, au lieu de produire une phrase à partir d’une grammaire, on reçoit une phrase et on cherche à comprendre si elle appartient au langage — et quelle structure la grammaire lui assigne ?
C’est la différence entre composer et analyser, entre parler et écouter, entre encoder et décoder. Et cette différence est loin d’être triviale.
Pourquoi c’est important ?
Un piège terminologique célèbre
Le livre le plus cité en théorie musicale formelle s’intitule A Generative Theory of Tonal Music (GTTM, Lerdahl & Jackendoff, 1983 — plus de 5 000 citations). Pourtant, GTTM ne génère aucune musique. C’est une théorie analytique : étant donné une pièce musicale existante, elle fournit des règles de préférence pour lui assigner une structure hiérarchique (groupement, structure métrique, réduction temporelle).
Le terme « generative » est utilisé au sens chomskyen originel — un ensemble de règles formellement explicites — et non au sens de « production ». Lerdahl lui-même a clarifié que GTTM modélise l’auditeur (réception), pas le compositeur (émission) [Lerdahl2009].
Cette confusion illustre un problème plus profond : on utilise le même mot — « grammaire » — pour deux activités fondamentalement différentes.
Deux faces d’une même pièce
Toute grammaire formelle définit un langage — un ensemble de chaînes valides. Mais elle peut être utilisée de deux façons :
| Direction | Nom technique | Question posée | Analogie musicale |
|---|---|---|---|
| → Génération | Production / Dérivation | « Quelles phrases cette grammaire peut-elle produire ? » | Le compositeur écrit une pièce |
| ← Reconnaissance | Parsing / Analyse | « Cette phrase appartient-elle au langage ? Quelle structure lui correspond ? » | Le musicologue analyse une prodction musicale |
Mathématiquement, les deux usages définissent le même langage : l’ensemble des chaînes est identique. Mais opérationnellement, les deux directions sont radicalement différentes.
L’idée en une phrase
Une grammaire formelle est un objet bidirectionnel : elle peut générer des phrases ou les analyser, mais les deux directions diffèrent selon au moins six dimensions indépendantes — complexité, ambiguïté, direction, information, inférence et temporalité. L’asymétrie est structurelle : le parser est toujours contraint, le générateur ne l’est pas nécessairement.
Expliquons pas à pas
1. L’asymétrie computationnelle
La première différence est de nature algorithmique. Pour une grammaire context-free (CFG, Context-Free Grammar — L2) :
- Générer une phrase est rapide : on part de l’axiome (start symbol — le symbole de départ de la grammaire), on applique les règles de réécriture, chaque pas est un choix local. La complexité est linéaire en la longueur de la dérivation.
- Reconnaître une phrase est plus coûteux : étant donné une chaîne de $n$ symboles, déterminer si elle appartient au langage et reconstruire sa structure nécessite un algorithme comme CYK (Cocke-Younger-Kasami) ou Earley, en temps $O(n^3)$ — c’est-à-dire proportionnel au cube de la longueur de l’entrée.
Pour des formalismes plus expressifs, l’écart se creuse dramatiquement. Les grammaires context-sensitive (Type 1, L1) ont un problème de reconnaissance qui est PSPACE-complet (Polynomial Space complete — une classe de complexité pour laquelle aucun algorithme efficace n’est connu en général) [Berwick1982].
En d’autres termes : produire est généralement plus facile qu’analyser.
Mais attention : cette formulation est trompeuse. La génération non contrainte — appliquer des règles au hasard — est triviale pour tout formalisme. Le résultat est « grammatical » mais inutile. La génération réelle opère sous contraintes (un sens cible, un style, des règles esthétiques), et la génération sous contraintes peut être aussi difficile que le parsing. La vraie asymétrie est structurelle : le parsing est toujours contraint (l’entrée est donnée, non négociable), tandis que la génération peut ou non l’être.
→ Pour les formalisations mathématiques de cet écart (formule $T_{\text{parse}}$ par niveau de Chomsky, graphe semi-log), voir L15.
Encart : L’analogie du puzzle
Construire un puzzle de 1 000 pièces à partir de l’image complète est relativement simple : on détermine comment on va le découper, on sait donc quelle pièce va où. Mais recevoir un puzzle mélangé et comprendre comment l’assembler — dans quel ordre, par quelle stratégie — est un tout autre problème. La grammaire est l’image de référence ; la génération construit le puzzle ; le parsing le désassemble pour comprendre sa structure.
2. L’asymétrie d’ambiguïté
La deuxième différence concerne l’ambiguïté structurelle — un phénomène unique qui se manifeste sous trois aspects liés :
Le déterminisme. En génération, on peut choisir une dérivation à chaque étape (éventuellement aléatoirement, comme dans les PCFG probabilistes — cf. B1). Le résultat est une seule phrase. En reconnaissance, une phrase peut avoir plusieurs analyses valides : la même séquence de mots peut correspondre à plusieurs arbres de dérivation (L4).
En linguistique, la phrase « J’ai vu l’homme avec le télescope » a deux analyses : j’utilise le télescope pour voir, ou l’homme a le télescope. En musique, une même progression harmonique peut être analysée de plusieurs façons par GTTM (M6).
La non-injectivité. Formellement, la génération est une fonction injective : un chemin de dérivation produit une seule phrase. Le parsing est non injectif : une même phrase peut correspondre à $k$ arbres de dérivation. La génération est un processus one-to-one, la reconnaissance un processus one-to-many.
La cardinalité (Eco). Umberto Eco, dans L’œuvre ouverte (1962), a formalisé la même asymétrie dans le domaine esthétique : une seule production (l’œuvre) admet de multiples interprétations (analyses). En musique, le compositeur sait pourquoi il a choisi telle note ; l’auditeur doit inférer cette intention. La fonction de génération converge (multiples intentions → une œuvre), tandis que la fonction d’analyse diverge (une œuvre → multiples interprétations).
Ces trois aspects — déterminisme, non-injectivité, cardinalité — sont un seul et même phénomène vu sous trois angles.
3. L’asymétrie de direction
La troisième différence est la plus invisible — à force d’être familière.
La génération a une direction fixe : elle est intrinsèquement descendante. On part de l’axiome (l’intention, le « quoi dire ») et on descend vers les symboles terminaux (la surface, les mots ou les notes). Comme Chomsky l’a formulé : une grammaire génère « de haut en bas, pas de gauche à droite ».
Le parsing, lui, a le choix de la direction. Il peut descendre (LL, descente récursive), monter (LR, shift-reduce), ou combiner les deux (Earley, left-corner). Le Dragon Book — le livre de référence en conception de compilateurs — consacre des chapitres entiers à ce choix. Un choix qui n’existe que pour le parser.
L’observation la plus frappante : la stratégie de parsing la plus différente de la génération (LR, ascendante) est la plus puissante. Celle qui imite la génération (LL, descendante) est la plus faible.
→ Cette dimension est développée en détail dans L14.
4. L’asymétrie d’information
Le générateur a accès à tout : l’intention communicative, les contraintes stylistiques, le contexte pragmatique. L’analyseur n’a accès qu’au signal observable — la surface sonore, la séquence de symboles.
C’est le problème fondamental de toute analyse musicale : les contraintes créatives sont disponibles pour le générateur mais doivent être reconstruites par l’analyseur. Le modèle de Shannon (§ ci-dessous) formalise cette asymétrie au niveau le plus fondamental : l’encodeur connaît la source, le décodeur non.
5. L’asymétrie temporelle : offline vs temps réel
Les quatre asymétries précédentes supposent implicitement qu’on a tout le temps nécessaire — qu’on travaille offline. Mais quand la contrainte du temps réel s’ajoute, l’asymétrie se creuse.
- Générer en temps réel est relativement naturel : on produit symbole par symbole, au fil de l’eau. Un compositeur qui improvise, un live coder qui modifie son code pendant le concert — chaque décision est locale et immédiate.
- Analyser en temps réel est beaucoup plus difficile : on reçoit le signal au fur et à mesure, sans connaître la suite. L’analyseur doit maintenir des hypothèses multiples sur la structure en cours — c’est le problème du parsing incrémental [Hale2001].
En musique, cette asymétrie est omniprésente. Un auditeur au concert entend les notes une par une. Il ne peut pas « revenir en arrière » pour réanalyser un passage. Son analyse est contrainte par le flux — il doit interpréter en temps réel, avec des informations partielles.
Encart : Le concert vs la partition
Un musicologue qui analyse une sonate de Beethoven a la partition complète sous les yeux — il peut aller et venir, comparer des passages distants, réviser ses interprétations. Un auditeur au concert n’a que le flux sonore : chaque seconde efface la précédente (sauf en mémoire). Les deux font de l’« analyse », mais sous des contraintes temporelles radicalement différentes. Le premier travaille offline (toute l’information disponible d’un coup) ; le second travaille en streaming (information partielle, séquentielle, irréversible).
Le modèle IDyOM formalise exactement cette situation : il prédit la note suivante à partir des notes déjà entendues, sans jamais voir l’avenir. C’est un décodeur incrémental au sens de Shannon — et c’est précisément ce qui le rend plus difficile que la génération.
→ La théorie de la surprisal (Hale, Levy) formalise mathématiquement cette asymétrie temporelle : voir L15 §6.
6. Le pont : l’analyse par synthèse
Le paradigme analysis-by-synthesis (analyse par synthèse), né dans la recherche sur la perception de la parole dans les années 1960, propose un pont entre les deux directions : pour reconnaître un signal, on génère des candidats internes et on les compare au signal reçu [HalleStevens1962].
L’analyse contient la synthèse comme sous-processus. Le récepteur n’est pas un simple filtre passif : il possède un modèle interne génératif qui produit des hypothèses, testées contre l’entrée.
En musique, cela correspond à l’expérience de l’auditeur expert : quand vous entendez un ii-V-I (la progression sous-dominante → dominante → tonique, par exemple Dm7 → G7 → Cmaj7 en do majeur), vous anticipez la résolution parce que votre modèle interne a généré cette attente. Les modèles comme IDyOM (Information Dynamics of Music — un modèle de prédiction musicale basé sur les statistiques d’un corpus) formalisent exactement ce processus prédictif [Pearce2018].
7. Les grammaires réversibles
Certains formalismes sont conçus pour fonctionner dans les deux directions avec la même grammaire :
- GF (Grammatical Framework, Ranta, 2019) — un formalisme multilingue où les grammaires sont explicitement réversibles, permettant à la fois le parsing et la génération [Ranta2019]
- Grammaires d’unification — utilisées en traduction automatique bidirectionnelle [vanNoord1990]
- Steedman (1984 → 2014) — la même grammaire CCG (Combinatory Categorial Grammar — L9) pour les progressions de jazz a été utilisée d’abord pour générer des séquences d’accords [Steedman1984], puis 30 ans plus tard pour les parser (les analyser automatiquement) [GranrothWilding2014]. C’est un exemple remarquable de la même grammaire musicale utilisée dans les deux directions — avec des défis computationnels très différents.
Mais la réversibilité n’est pas automatique. Strzalkowski (1993) a montré qu’une grammaire conçue pour le parsing nécessite des transformations (une « inversion ») pour être utilisée en génération. Le fait même qu’un processus d’inversion soit nécessaire prouve l’asymétrie opérationnelle [Strzalkowski1993].
→ La bidirectionnalité existe depuis 50 ans en TAL — pourquoi n’est-elle pas partout ? Voir L16.
8. En musique : trois paradigmes
La dualité génération/reconnaissance structure l’ensemble de la musicologie computationnelle. On peut classer les systèmes musicaux formels en trois paradigmes, selon les directions qu’ils supportent :
\usepackage{tikz}
\usetikzlibrary{calc, positioning}
\begin{document}
\definecolor{cAnal}{RGB}{41,128,185}
\definecolor{cGen}{RGB}{39,174,96}
\definecolor{cBidi}{RGB}{192,57,43}
\definecolor{cNeural}{RGB}{142,68,173}
\begin{tikzpicture}[scale=1.5, transform shape,
every node/.style={font=\scriptsize, text=black},
sysnode/.style={fill=#1!15, draw=#1!50, rounded corners=2pt,
inner sep=2pt, font=\scriptsize\bfseries, text=black}]
% Timeline axis
\draw[black!40, line width=0.8pt, -{latex}] (0,0) -- (12.5,0);
% Year ticks
\foreach \x/\yr in {0/1980, 2/1990, 4/2000, 6/2010, 8/2020, 10/2025} {
\draw[black!40] (\x, -0.1) -- (\x, 0.1);
\node[below, font=\tiny, text=black!60] at (\x, -0.15) {\yr};
}
% Legend
\node[sysnode=cAnal] at (1.5, 4.2) {Analytique};
\node[sysnode=cGen] at (4, 4.2) {G\'{e}n\'{e}ratif};
\node[sysnode=cNeural] at (6.5, 4.2) {Neural};
\node[sysnode=cBidi] at (9, 4.2) {Bidirectionnel};
%
% === ANALYTICAL (blue, top band) ===
\node[sysnode=cAnal] at (0.6, 3.4) {GTTM};
\node[font=\tiny, text=black!50] at (0.6, 3.0) {1983};
\node[sysnode=cAnal] at (4.8, 3.4) {Schenker};
\node[font=\tiny, text=black!50] at (4.8, 3.0) {2004};
\node[sysnode=cAnal] at (7.6, 3.4) {IDyOM};
\node[font=\tiny, text=black!50] at (7.6, 3.0) {2018};
\node[sysnode=cAnal] at (9.4, 3.4) {Finkensiep};
\node[font=\tiny, text=black!50] at (9.4, 3.0) {2019};
%
% === GENERATIVE (green, upper-mid band) ===
\node[sysnode=cGen] at (0.2, 2.2) {Holtzman};
\node[font=\tiny, text=black!50] at (0.2, 1.8) {1981};
\node[sysnode=cGen] at (1.6, 2.2) {Max};
\node[font=\tiny, text=black!50] at (1.6, 1.8) {1988};
\node[sysnode=cGen] at (3.2, 2.2) {SC};
\node[font=\tiny, text=black!50] at (3.2, 1.8) {1996};
\node[sysnode=cGen] at (4.4, 2.2) {OM};
\node[font=\tiny, text=black!50] at (4.4, 1.8) {1999};
\node[sysnode=cGen] at (6.8, 2.2) {Tidal};
\node[font=\tiny, text=black!50] at (6.8, 1.8) {2014};
%
% === NEURAL (purple, lower-mid band) ===
\node[sysnode=cNeural] at (8, 1.5) {Jukebox};
\node[font=\tiny, text=black!50] at (8, 1.1) {2020};
\node[sysnode=cNeural] at (9.5, 1.5) {MusicLM};
\node[font=\tiny, text=black!50] at (9.5, 1.1) {2023};
\node[sysnode=cNeural] at (11, 1.5) {Suno};
\node[font=\tiny, text=black!50] at (11, 1.1) {2023};
%
% === BIDIRECTIONAL (red, bottom band) ===
\node[sysnode=cBidi] at (0.8, 0.6) {Steedman};
\node[font=\tiny, text=black!50] at (0.8, 0.25) {1984};
\draw[cBidi!60, dashed, line width=0.5pt] (1.5, 0.6) -- (6.6, 0.6);
\node[sysnode=cBidi] at (7.2, 0.6) {parser};
\node[font=\tiny, text=black!50] at (7.2, 0.25) {2014};
\node[sysnode=cBidi] at (2.4, 0.6) {BP3};
\node[font=\tiny, text=black!50] at (2.4, 0.25) {1992};
\node[sysnode=cBidi] at (5.2, 0.6) {OMax};
\node[font=\tiny, text=black!50] at (5.2, 0.25) {2006};
\node[sysnode=cBidi] at (8.8, 0.6) {Harrison};
\node[font=\tiny, text=black!50] at (8.8, 0.25) {2019};
\end{tikzpicture}
\end{document}
Figure 1 — Taxonomie chronologique des systèmes musicaux formels selon les directions qu’ils supportent : analytique (bleu), génératif (vert), neuronal (violet), bidirectionnel (rouge). La ligne tiretée entre Steedman 1984 et le parser 2014 illustre les 30 ans de décalage entre génération et parsing pour la même grammaire CCG.
Le paradigme analytique — la grammaire comme outil d’écoute. Ces systèmes reçoivent une pièce existante et déterminent une structure qui lui correspond :
- GTTM (Lerdahl & Jackendoff, 1983) : modèle de l’auditeur, pas du compositeur (M6)
- Analyse schenkérienne computationnelle (Mavromatis & Brown, 2004) : parsing d’une pièce existante pour en extraire la structure profonde
- IDyOM (Pearce, 2018) : modèle statistique de prédiction musicale — l’auditeur comme machine d’inférence
- Grammaire de graphe mélodique (Finkensiep et al., 2019) : parsing mélodique de la musique hindustani — un outil analytique appliqué à un répertoire non occidental
- Compression grammaticale (Humphreys et al., 2021) : l’induction de grammaire comme outil analytique implicite — compresser une pièce, c’est en extraire la structure
Le paradigme génératif — la grammaire comme outil de composition. Ces systèmes produisent de la musique à partir de règles ou de patterns, mais ne peuvent pas analyser :
- Grammaires génératives musicales (Holtzman, 1981) : utilisation pionnière de grammaires context-free pour la composition automatique
- Max (Puckette, 1988/IRCAM) : programmation visuelle par flux de données pour l’audio temps réel — né à l’IRCAM, devenu la plateforme dominante pour la création électroacoustique et l’art interactif
- SuperCollider (McCartney, 1996) : plateforme open source de synthèse et composition algorithmique — sa bibliothèque de patterns (Pbind, Pseq, Prand…) constitue un formalisme génératif embarqué dans le langage. C’est aussi la cible de BP2SC (I1) et l’hôte de TidalCycles (I3)
- OpenMusic (Assayag et al., 1999/IRCAM) : environnement de composition assistée par ordinateur — programmation visuelle en Lisp avec résolution de contraintes, utilisé par de nombreux compositeurs contemporains (Music Representation Team, IRCAM)
- Euterpea (Quick & Hudak, 2013) : composition fonctionnelle en Haskell — la musique comme type de données algébrique
- TidalCycles (McLean, 2014) : live coding par patterns temporels — héritier direct de Bel (M11), s’exécute sur SuperCollider
- L-systems musicaux (Roncoroni, 2021) : les grammaires parallèles de Lindenmayer appliquées au remixage génératif — un formalisme intrinsèquement unidirectionnel
- Système CFG+Markov (Kamberaj et al., 2025) : CFG pour les progressions d’accords et chaînes de Markov pour la mélodie — un système entièrement génératif
Au-delà des approches formelles, la génération neuronale a transformé le paysage depuis 2020. Ces systèmes n’utilisent aucune grammaire explicite — les « règles » musicales sont entièrement implicites dans les poids appris par deep learning :
- Jukebox (Dhariwal et al., 2020) : génération audio brute par VQ-VAE (Vector Quantized Variational Autoencoder) — OpenAI
- MusicLM (Agostinelli et al., 2023) : génération text-to-music par modèle séquence-à-séquence hiérarchique — Google
- MusicGen (Copet et al., 2023) : transformer autorégressif single-stage, conditionnement par texte ou mélodie — Meta
- Suno (2023) : génération text-to-song accessible au grand public, incluant voix et paroles — architecture non publiée
Ces systèmes sont puissamment génératifs mais entièrement opaques : ils ne peuvent ni analyser une pièce existante, ni expliquer leurs choix, ni exposer les « règles » qu’ils ont apprises. L’absence de grammaire explicite est précisément ce qui les rend inexplicables. Le coût analytique n’a pas disparu — il a été déplacé dans la phase d’entraînement (cf. L16).
Le paradigme bidirectionnel — la grammaire comme pont. Ces systèmes utilisent la même grammaire dans les deux directions, mais avec des degrés d’intégration très variables :
- CCG jazz (Steedman, 1984 → Granroth-Wilding, 2014) : la même grammaire catégorielle combinatoire pour les progressions de jazz, d’abord utilisée pour générer, puis 30 ans plus tard pour parser. Un cas remarquable — mais les deux directions ont été développées séparément.
- EMI (Cope, 1989) : Experiments in Musical Intelligence — le système analyse un corpus pour en extraire les conventions stylistiques, puis génère de nouvelles pièces dans le même style. Les deux directions dans un même système, mais séquentiellement (analyse d’abord, génération ensuite).
- Bol Processor (Bel & Kippen, 1992) : le cas le plus intégré. BP3 possède trois modes d’utilisation de la même grammaire :
– PROD (production, modus ponens) : la grammaire génère des séquences musicales
– ANAL (analysis, modus tollens) : la grammaire teste si une séquence appartient au langage et, le cas échéant, en identifie la structure
– TEMP (template exploration) : la grammaire énumère exhaustivement toutes les structures de dérivation possibles, produisant des squelettes structurels qui peuvent optionnellement accélérer l’analyse (ANAL) ou servir d’outil de design autonome
- OMax/SoMax (Assayag, Dubnov et al., 2006/IRCAM) : improvisation machine basée sur l’automate Factor Oracle — un automate formel (Type 3) construit en temps réel à partir du jeu d’un musicien (analyse), puis parcouru pour générer des réponses improvisées. Le même formalisme sert aux deux directions, mais l’analyse reste au niveau des séquences de surface (pas de structure profonde)
- Antescofo (Cont, 2008/IRCAM) : suivi de partition (score following) couplé à un langage réactif de génération d’accompagnement — les deux directions fonctionnent simultanément en temps réel, mais reposent sur des formalismes différents (modèles probabilistes pour l’analyse, langage synchrone pour la génération)
- Modèle unifié voice-leading (Harrison & Pearce, 2019) : analyse et génération de conduite des voix dans un seul cadre — un cas récent et rare de bidirectionnalité musicale explicite
Le cycle complet de Bel et Kippen pour le tabla illustre parfaitement la dualité : un musicien produit des séquences de bols (syllabes mnémoniques du tabla — B2), le système analyse ces séquences pour en inférer une grammaire (via QAVAID, Question Answer Validated Analytical Inference Device — un système d’inférence grammaticale interactif), puis cette grammaire peut re-produire de nouvelles séquences, que le musicien évalue. C’est une boucle analyse → grammaire → génération → évaluation → analyse [KippenBel1989].
9. La troisième direction : l’inférence grammaticale
Au-delà de la dualité génération/reconnaissance, il existe une troisième direction encore plus fondamentale : l’inférence grammaticale (grammar induction) — étant donné des exemples de phrases, retrouver la grammaire elle-même [delaHiguera2010].
C’est le problème inverse de la théorie des langages formels. Les trois opérations forment une hiérarchie de difficulté croissante :
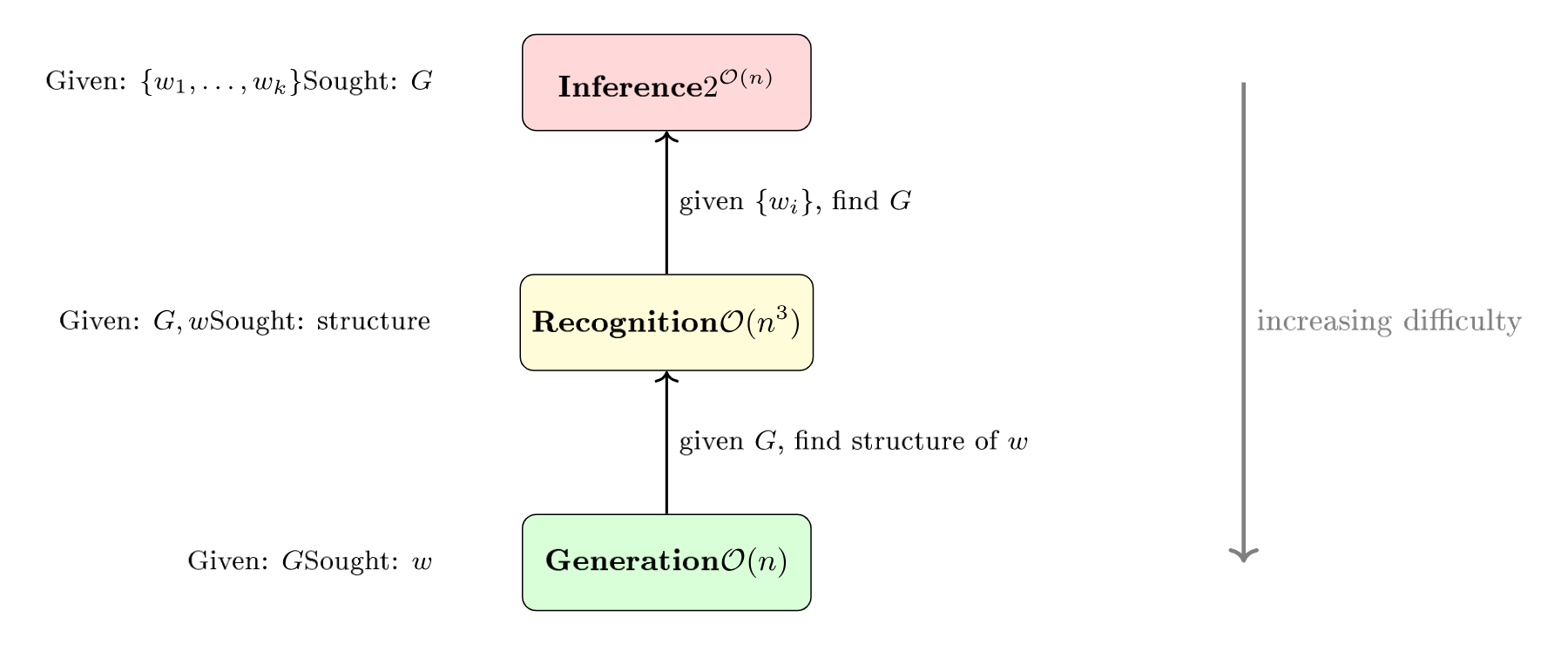
La génération ($\mathcal{O}(n)$) est la plus simple : on applique les règles. La reconnaissance ($\mathcal{O}(n^3)$ pour les CFG) est plus coûteuse : on reconstruit la structure. L’inférence ($2^{\mathcal{O}(n)}$) est la plus difficile : on retrouve les règles elles-mêmes à partir des seuls exemples.
En musique, c’est exactement ce que fait un musicologue quand il écoute un corpus et tente d’en extraire les « règles » — les conventions stylistiques, les contraintes harmoniques, les patterns rythmiques. C’est aussi ce que font les systèmes d’inférence grammaticale comme QAVAID pour le tabla ou les travaux de Cruz-Alcázar & Vidal pour l’identification de style musical [CruzAlcazar2008].
Cette direction sera explorée en détail dans M10.
Le modèle de Shannon : encodeur $\neq$ décodeur
Le modèle de communication de Claude Shannon (1948) formalise l’asymétrie au niveau le plus fondamental. Le schéma ci-dessous montre la chaîne complète : une source produit un message, l’encodeur le transforme en signal, le canal y ajoute du bruit, et le décodeur tente de reconstruire le message original.
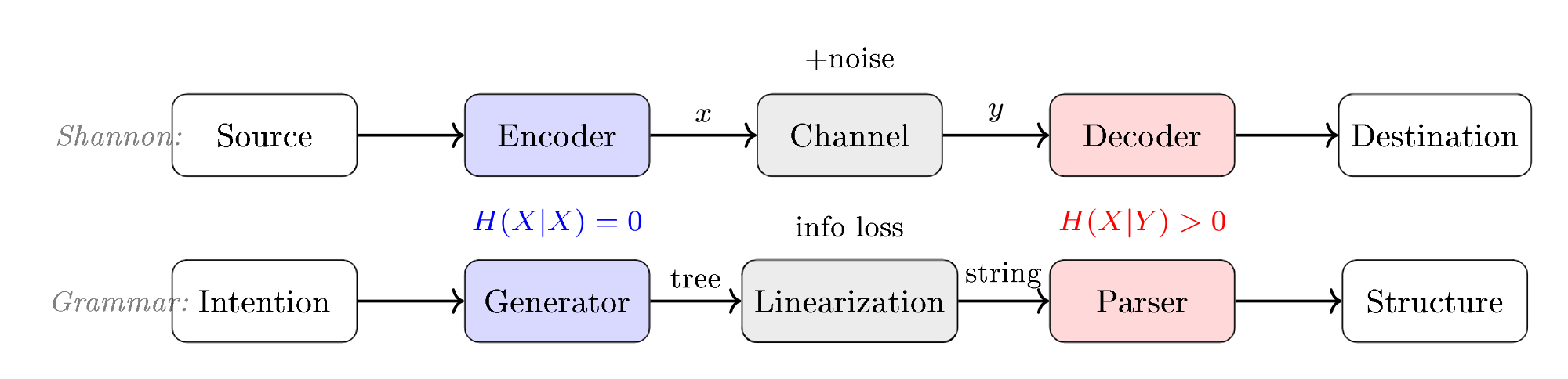
L’encodeur (génération) et le décodeur (reconnaissance) ne sont pas symétriques :
- L’encodeur transforme un message en signal — c’est un choix parmi les possibles
- Le décodeur reconstruit le message à partir du signal bruité — c’est une inférence du plus probable
Le canal introduit du bruit — de l’incertitude, de la perte. En musique : l’air est un canal bruité, l’oreille est un décodeur imparfait, la partition est un encodeur lossy (elle ne capture pas le timbre, le toucher, l’intention). Chaque traduction entre représentations musicales est un passage encodeur → canal → décodeur, avec ses propres pertes et ambiguïtés.
Ce qu’il faut retenir
- Toute grammaire a deux usages : générer (produire des phrases) et reconnaître (analyser des phrases existantes).
- Ces deux directions sont mathématiquement équivalentes (même langage) mais opérationnellement asymétriques selon six dimensions indépendantes : complexité, ambiguïté, direction, information, inférence et temporalité.
- Générer est généralement plus facile qu’analyser : $O(n)$ vs $O(n^3)$ pour les CFG, et l’écart se creuse pour les formalismes plus expressifs.
- En temps réel, l’asymétrie se creuse encore : générer en streaming est naturel (on produit au fil de l’eau), analyser en streaming est difficile (on n’a pas encore vu la suite — parsing incrémental).
- L’analyse par synthèse montre que la reconnaissance utilise la génération comme sous-processus interne.
- En musique, GTTM est analytique (malgré son titre), Steedman est bidirectionnel, et BP3 est explicitement réversible (modes PROD/ANAL/TEMP).
- L’inférence grammaticale est la troisième direction : retrouver la grammaire à partir des exemples — le problème fondamental de la musicologie computationnelle.
Pour aller plus loin
Fondements théoriques
- Berwick, R. (1984). « Strong Generative Capacity, Weak Generative Capacity, and Modern Linguistic Theories. » Computational Linguistics.
- Strzalkowski, T. (1993). Reversible Grammar in Natural Language Processing. Springer — ouvrage fondateur sur les grammaires réversibles.
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press — référence sur l’inférence grammaticale.
Musique
- Lerdahl, F. & Jackendoff, R. (1983). A Generative Theory of Tonal Music. MIT Press — le modèle analytique le plus influent.
- Steedman, M. (1984). « A Generative Grammar for Jazz Chord Sequences. » Music Perception — grammaire de jazz utilisée ensuite pour le parsing (Granroth-Wilding & Steedman, 2014).
- Puckette, M. (1988). « The Patcher. » ICMC — Max, programmation visuelle temps réel née à l’IRCAM.
- Bel, B. & Kippen, J. (1992). « Modelling Music with Grammars: Formal Language Representation in the Bol Processor » — le système bidirectionnel par excellence.
- Assayag, G., Rueda, C. & Laurson, M. (1999). « Computer-Assisted Composition at IRCAM: From PatchWork to OpenMusic. » Computer Music Journal, 23(3), 59–72 — composition assistée par contraintes.
- Cruz-Alcázar, P.P. & Vidal, E. (2008). « Two Grammatical Inference Applications in Music Processing. » Applied Artificial Intelligence.
- Assayag, G. & Dubnov, S. (2004). « Using Factor Oracles for Machine Improvisation. » Soft Computing, 8(9), 604–610 — OMax, improvisation par automate Factor Oracle (IRCAM).
- Cont, A. (2008). « Antescofo: Anticipatory Synchronization and Coupling. » ICMC — suivi de partition et accompagnement réactif (IRCAM).
- Finkensiep, C., Neuwirth, M. & Rohrmeier, M. (2019). « Generalized Graph Grammar for North Indian Melodic Syntax. » DLfM — parsing mélodique appliqué à la musique hindustani.
- Harrison, P.M.C. & Pearce, M.T. (2019). « A Unified Model for Voice-Leading Analysis and Generation. » — bidirectionnalité musicale explicite pour la conduite des voix.
- Humphreys, G. et al. (2021). « Grammar-Based Compression for Music Analysis. » — compression grammaticale comme outil analytique implicite.
- Kamberaj, B. et al. (2025). « CFG-Based Chord and Markov Melody Generation. » — système entièrement génératif.
- McCartney, J. (2002). « Rethinking the Computer Music Language: SuperCollider. » Computer Music Journal, 26(4), 61–68 — la plateforme open source de synthèse et composition algorithmique.
- Roncoroni, L. (2021). « L-Systems for Musical Remixing. » — grammaires parallèles de Lindenmayer appliquées à la génération musicale.
Génération neuronale
- Dhariwal, P. et al. (2020). « Jukebox: A Generative Model for Music. » arXiv:2005.00341 — génération audio brute par VQ-VAE (OpenAI).
- Agostinelli, A. et al. (2023). « MusicLM: Generating Music From Text. » arXiv:2301.11325 — génération text-to-music hiérarchique (Google).
- Copet, J. et al. (2023). « Simple and Controllable Music Generation. » NeurIPS — MusicGen, transformer single-stage, conditionnement texte/mélodie (Meta).
Asymétrie temporelle et parsing incrémental
- Hale, J. (2001). « A Probabilistic Earley Parser as a Psycholinguistic Model. » NAACL — modèle fondateur du parsing incrémental probabiliste.
Analysis-by-synthesis
- Halle, M. & Stevens, K.N. (1962). « Speech Recognition: A Model and a Program for Research. » IRE Transactions on Information Theory.
- Poeppel, D. & Monahan, P.J. (2011). « Feedforward and Feedback in Speech Perception: Revisiting Analysis by Synthesis. » Language and Cognitive Processes.
Approfondir l’asymétrie
- L14 — La direction du parsing : LL, LR et le Dragon Book (D3)
- L15 — Les formules de l’asymétrie : T_parse, surprisal, Birman-Ullman
- L16 — Le paradoxe de la bidirectionnalité : 50 ans de grammaires réversibles oubliées
Dans le corpus
- L1 — Les niveaux de complexité
- L2 — Les grammaires qui produisent
- L9 — Les formalismes mildly context-sensitive (TAG, CCG)
- M6 — GTTM : le paradigme analytique appliqué
- M10 — L’inférence grammaticale en musique (à venir)
- B6 — Wildcards BP3 : du pattern matching dans la grammaire
Glossaire
- Analysis-by-synthesis (analyse par synthèse) : Paradigme de reconnaissance où le récepteur génère des candidats internes et les compare au signal reçu. L’analyse contient la synthèse comme sous-processus.
- ANAL (mode) : Mode analytique du Bol Processor — la grammaire teste si une séquence appartient au langage (modus tollens).
- Ambiguïté structurelle : Propriété d’une phrase qui admet plusieurs arbres de dérivation pour la même grammaire. Fréquente en reconnaissance, absente en génération.
- Encodeur / Décodeur : Dans le modèle de Shannon, l’encodeur transforme un message en signal (génération), le décodeur reconstruit le message depuis le signal (reconnaissance). Ils ne sont pas symétriques.
- Grammaire réversible : Grammaire conçue pour être utilisée dans les deux directions (génération et parsing) sans transformation. Exemples : GF, grammaires d’unification.
- IDyOM (Information Dynamics of Music) : Modèle statistique de prédiction musicale basé sur l’entropie d’un corpus. Modélise l’auditeur comme machine d’inférence.
- Inférence grammaticale (grammar induction) : La « troisième direction » — retrouver la grammaire à partir d’exemples de phrases. Problème inverse de la théorie des langages formels.
- Modus ponens / modus tollens : En logique, le modus ponens va de la règle vers la conséquence (si A alors B, A, donc B — direction générative). Le modus tollens va de l’observation vers la prémisse (si A alors B, B observé, donc A plausible — direction analytique).
- NLG / NLU (Natural Language Generation / Understanding) : Les deux sous-domaines du NLP (Natural Language Processing, traitement automatique des langues) qui incarnent la dualité génération/reconnaissance.
- Parsing incrémental : Analyse syntaxique qui traite l’entrée symbole par symbole, au fur et à mesure de sa réception, sans attendre la fin de la phrase. Nécessaire pour l’analyse en temps réel. Plus difficile que le parsing offline car l’analyseur n’a pas accès à la suite du signal.
- Parsing (analyse syntaxique) : Processus qui, étant donné une phrase et une grammaire, détermine si la phrase appartient au langage et reconstruit sa structure (arbre de dérivation).
- PROD (mode) : Mode production du Bol Processor — la grammaire génère des séquences musicales (modus ponens).
- QAVAID (Question Answer Validated Analytical Inference Device) : Système d’inférence grammaticale interactif de Bel & Kippen pour le tabla. Le nom signifie aussi « grammaire » en arabe/ourdou.
Prérequis : L1, L2
Temps de lecture : 14 min
Tags : #grammaires #dualité #génération #reconnaissance #parsing #analyse-par-synthèse #BP3