L15) Les formules de l’asymétrie
[!info] Série « Asymétrie génération-reconnaissance »
Cet article accompagne l’article de recherche The Generation-Recognition Asymmetry: Six Dimensions of a Fundamental Divide in Formal Language Theory (📄 arXiv).
Fil de lecture : L13 · L14 · L15 · L16 · L17 · L18 · L19 · L20 — ou l’index complet.
De T_parse à la surprisal
Dans L13, nous avons vu que génération et reconnaissance sont « opérationnellement asymétriques ». Mais nous sommes restés au niveau de l’intuition : O(n) contre O(n³), « la génération est plus facile ». Cet article va plus loin : il décortique les formules, une par une, pour montrer que l’asymétrie n’est pas un slogan — c’est un résultat mathématique en six dimensions indépendantes.
Où se situe cet article ?
Cet article est le compagnon technique de L13. Là où L13 présentait l’asymétrie en termes accessibles — puzzles, concerts, compositeurs — cet article présente les formules qui la fondent. C’est un article de la série L (langages formels), avec les formules au premier plan mais toujours expliquées : aucune équation n’apparaît sans qu’on dise ce qu’elle signifie et pourquoi elle compte.
Si vous êtes à l’aise avec les notations de L1 et L6, vous serez en terrain connu.
Pourquoi c’est important ?
L’intuition « générer est facile, analyser est difficile » est à la fois vraie et trompeuse. Vraie : il y a un vrai écart de complexité. Trompeuse : la vraie asymétrie n’est pas un simple écart de difficulté — elle est structurelle. Le parser fait face à des contraintes imposées (l’entrée est donnée, non négociable) ; le générateur fait face à des contraintes choisies (il peut ou non se les imposer).
Les formules qu’on va voir ne disent pas seulement « l’un est plus lent que l’autre ». Elles montrent que l’asymétrie se manifeste sur six axes indépendants — complexité, ambiguïté, direction, information, inférence, temporalité — et qu’elle est intrinsèque aux langages formels, pas un artefact de telle ou telle implémentation.
L’idée en une phrase
L’asymétrie génération-reconnaissance se formalise en six dimensions mathématiquement indépendantes — de l’écart de complexité (reconnaissance CFG en $\mathcal{O}(n^\omega)$, $\omega \approx 2{,}37$) à la surprisal $S = 0$ du générateur contre $S > 0$ du parser — sans pour autant se réduire à un « générer est facile, analyser est difficile ».
Expliquons pas à pas
1. L’écart de complexité : T_gen vs T_parse
En quoi mesure-t-on tout ça ? Avant la moindre formule, il faut fixer l’unité. Toutes les complexités de cet article comptent le nombre d’opérations élémentaires — les étapes de calcul de base (comparer deux symboles, lire une case mémoire, appliquer une règle) qu’effectue une machine abstraite déterministe — dans le pire cas, et à grammaire fixée (la taille de la grammaire $|G|$ n’entre dans le compte que lorsqu’on l’indique explicitement). C’est cette unité qui donne le $\mathcal{O}(n^3)$ de CYK ou le $\mathcal{O}(n^6)$ de TAG.
Une exception assumée. La génération libre (appliquer des règles sans viser de sortie précise) se mesure non pas en opérations élémentaires mais en étapes de dérivation — une étape = une réécriture d’un non-terminal. La raison : tant qu’aucune chaîne n’est visée, il n’existe pas d’entrée de longueur $n$ à parcourir ; compter les réécritures isole le coût propre de la réécriture, indépendamment de la structure de données qui gère les non-terminaux en attente (file ou pile : $\mathcal{O}(1)$ par étape ; scan naïf de la forme sententielle : $\mathcal{O}(n)$). Ce n’est pas un mélange d’unités déguisé : l’article de recherche explicite ce changement à chaque endroit où il s’écarte de l’unité de base.
La génération non contrainte est linéaire quelle que soit la classe de grammaire : $T_{\text{gen}} = \mathcal{O}(n)$. La reconnaissance, elle, dépend dramatiquement du niveau de Chomsky :
| Niveau Chomsky | $T_{\text{gen}}$ | $T_{\text{parse}}$ | Écart |
|---|---|---|---|
| Type 3 (régulier) | $\mathcal{O}(n)$ | $\mathcal{O}(n)$ | nul |
| Type 2 (context-free) | $\mathcal{O}(n)$ | $\mathcal{O}(n^\omega)$, $\omega\approx2{,}37$ (CYK : $O(n^3)$) | super-linéaire |
| Type 2+ (TAG/MCFG) | $\mathcal{O}(n)$ | $\mathcal{O}(n^6)$ | puissance 6 |
| Type 1 (context-sensitive) | $\mathcal{O}(n)$ | PSPACE-complet | exponentiel |
| Type 0 (r.e.) | $\mathcal{O}(n)$ | $\to \infty$ | infini |
L’asymétrie croît avec le pouvoir expressif. Mais cette vue unidimensionnelle est trompeuse : en réalité, chaque opération dépend de deux axes orthogonaux — la classe de grammaire et la spécification de tâche — avec une sensibilité inversée. C’est le couplage différentiel : la génération est sensible à la tâche (libre vs contrainte), la reconnaissance est sensible à la grammaire (Type 3 vs Type 0).
→ Pour les deux matrices de complexité complètes et le couplage différentiel, voir L17.
Précision (v2.1). Le tableau ci-dessus résume la génération à $\mathcal{O}(n)$, mais cela ne vaut que pour la génération libre ou terminante. Chaque opération se décompose en réalité en trois sous-problèmes (côté reconnaissance : appartenance, un arbre, tous les arbres ; côté génération : libre, terminante, sous contrainte). Et pour la génération sous contrainte sémantique, l’asymétrie change de signe — elle peut devenir exponentielle (Kay 1996) ou NP-complète prouvée (Brew 1992), donc plus difficile que le parsing. Voir L18.
2. Gen et parse comme fonctions
On peut formaliser la génération et le parsing comme deux fonctions mathématiques :
$\text{gen}: G \times D \to \Sigma^*$
La génération prend une grammaire $G$ et une séquence de dérivation $d$ (la suite de choix : quelle règle appliquer à chaque étape), et produit une chaîne $w$. Pour un $d$ fixé, la sortie $w$ est unique : gen est une fonction (univoque). Attention au faux ami : ce n’est pas de l’injectivité — deux dérivations distinctes peuvent produire la même chaîne. Le point n’est pas l’injectivité, mais que l’entrée — (grammaire + dérivation) — fixe la sortie.
$\text{parse}: G \times \Sigma^* \to 2^{\mathcal{T}}$
Le parsing prend une grammaire $G$ et une chaîne $w$, et retourne un ensemble d’arbres de dérivation $\{t_1, t_2, \ldots, t_k\}$. La notation $2^{\mathcal{T}}$ signifie « un sous-ensemble de l’ensemble de tous les arbres possibles ». Trois cas :
- $k = 0$ : la chaîne n’appartient pas au langage
- $k = 1$ : parsing non ambigu (un seul arbre)
- $k > 1$ : parsing ambigu (plusieurs arbres valides pour la même chaîne)
parse est une relation (multivoque) : une même chaîne peut correspondre à plusieurs structures. La cause profonde n’est pas une propriété intrinsèque de la reconnaissance, mais l’informativité différentielle de l’entrée : le parser ne reçoit que (grammaire + chaîne), strictement moins informatif que (grammaire + dérivation) — son entrée sous-détermine l’arbre.
En résumé :
- gen : (grammaire + dérivation) → une phrase — entrée qui fixe la sortie (fonction univoque)
- parse : (grammaire + phrase) → plusieurs arbres — entrée qui sous-détermine la sortie (relation multivoque)
3. Les nombres de Catalan : pourquoi l’ambiguïté explose
Quand $k > 1$ (la chaîne est ambiguë), combien d’arbres de dérivation peut-on avoir ? La réponse est donnée par les nombres de Catalan :
$C_n = \frac{1}{n+1}\binom{2n}{n} \sim \frac{4^n}{n^{3/2}\sqrt{\pi}}$
$C_n$ est le nombre de façons d’associer $n$ éléments par paires — ce qui correspond au nombre d’arbres binaires à $n$ nœuds. En pratique :
| $n$ (syntagmes) | $C_n$ (arbres possibles) |
|---|---|
| 2 | 2 |
| 3 | 5 |
| 4 | 14 |
| 5 | 42 |
| 10 | 16 796 |
| 15 | 9 694 845 |
Pour 3 syntagmes prépositionnels (« J’ai vu l’homme avec le télescope sur la colline »), il y a déjà 5 arbres de dérivation possibles. Pour 10, plus de 16 000. La croissance est exponentielle : $\sim 4^n$.
Les forêts de dérivation partagées (Billot & Lang, 1989) permettent de représenter compactement un nombre exponentiel d’arbres en espace $\mathcal{O}(n^3)$ — mais le nombre d’arbres sous-jacents reste exponentiellement grand. Le non-déterminisme est comprimé, pas éliminé.
4. Parikh et l’ambiguïté intrinsèque
On pourrait espérer qu’en réécrivant la grammaire plus intelligemment, on pourrait toujours éliminer l’ambiguïté. Le théorème de Parikh (1966) détruit cet espoir :
Théorème (Parikh, 1966). Il existe des langages context-free intrinsèquement ambigus — des langages pour lesquels aucune grammaire ne peut être écrite sans ambiguïté.
L’exemple classique :
$L = \{a^n b^n c^m d^m \mid n, m \geq 1\} \cup \{a^n b^m c^m d^n \mid n, m \geq 1\}$
Ce langage est l’union de deux langages context-free. Toute chaîne de la forme $a^n b^n c^n d^n$ (quand $n = m$) appartient aux deux sous-langages — et cette double appartenance ne peut être éliminée par aucun choix de grammaire.
Brabrand, Giegerich et Moller (2007) ajoutent un résultat encore plus fort : il est indécidable de déterminer si une grammaire est ambiguë. On ne peut même pas vérifier, en général, si une grammaire donnée exhibe le problème.
5. Le paradoxe de Birman-Ullman
Birman et Ullman (1973) ont observé un paradoxe :
« Transformer une grammaire de Chomsky en mécanisme de parsing est considérablement difficile ; mais transformer un schéma de parsing en mécanisme de génération est bien plus facile. »
À première vue, cela inverse l’asymétrie. N’est-ce pas la génération qui est plus difficile ?
La résolution réside dans la distinction entre transformer d’un mode à l’autre et opérer au sein d’un mode.
Un schéma de parsing contient déjà l’analyse structurelle — il a résolu les ambiguïtés, exploré l’espace de dérivation, encodé la stratégie de reconnaissance. Le convertir en générateur est une « rétrogradation informationnelle » : on rejette la structure analytique et on ne garde que le chemin génératif. C’est facile parce qu’on jette de l’information.
Convertir une grammaire générative en parser est une « mise à niveau informationnelle » : on doit ajouter la machinerie analytique (lookahead, désambiguïsation, récupération d’erreurs) absente de la grammaire. C’est difficile parce qu’on crée de l’information.
L’observation de Birman-Ullman confirme donc l’asymétrie : le parsing contient plus d’information que la génération. L’asymétrie de la transformation est l’image miroir de l’asymétrie de l’opération.
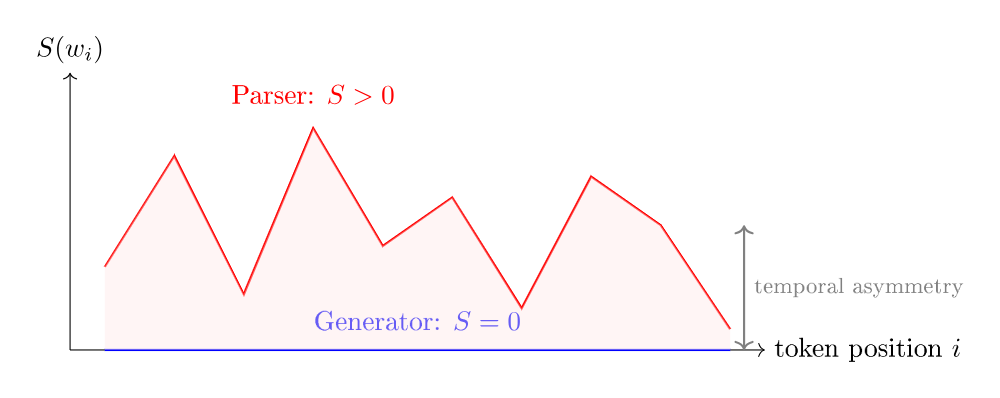
6. La surprisal : l’asymétrie temporelle formalisée
La dimension la plus surprenante (c’est le cas de le dire) est peut-être la temporelle. La surprisal de Hale (2001) la formalise.
La surprisal du $i$-ème token est :
$S(w_i) = -\log_2 P(w_i \mid w_1, w_2, \ldots, w_{i-1})$
En français : « combien de bits d’information ce token apporte-t-il, étant donné ce qu’on a déjà vu ? ». Plus un token est inattendu, plus sa surprisal est élevée.
Pour un générateur déterministe, le système sait quel token il va produire :
$P_{\text{gen}}(w_i \mid w_1, \ldots, w_{i-1}) = 1 \quad \Longrightarrow \quad S_{\text{gen}}(w_i) = 0$
Le générateur n’est jamais surpris. Il crée le futur — il le connaît d’avance. Surprisal = zéro, toujours.
Pour un parser incrémental, le système a vu $w_1, \ldots, w_i$ mais pas la suite. Il maintient des hypothèses concurrentes :
$P_{\text{parse}}(w_i \mid w_1, \ldots, w_{i-1}) < 1 \quad \Longrightarrow \quad S_{\text{parse}}(w_i) > 0$
Le parser est surpris — à chaque token, il doit réévaluer ses hypothèses. Surprisal > 0, toujours.
La surprisal quantifie l’asymétrie temporelle : exactement zéro pour le générateur, strictement positive pour le parser. C’est la formalisation mathématique de l’intuition : le compositeur sait ce qu’il va écrire ; l’auditeur découvre au fur et à mesure.
Encart : l’analogue en traitement du signal
En traitement numérique du signal, un système causal au temps $t$ ne dépend que des entrées passées ($\leq t$). Un système anti-causal peut accéder aux entrées futures. Le générateur est causal (il crée le futur) ; le parser sans lookahead est causal aussi (il ne voit que le passé), mais un parser avec lookahead est partiellement anti-causal — il regarde l’avenir. Les encodeurs bidirectionnels comme BERT accèdent à toute la séquence : une capacité analytique pure.
7. Le tableau récapitulatif
Voici les six dimensions réunies dans un tableau unique :
| Dim | Nom | Génération | Reconnaissance | Référence clé |
|---|---|---|---|---|
| D1 | Complexité | $\mathcal{O}(n)$ (gen-exemple) | $\mathcal{O}(n^\omega)$ à indécidable | Valiant 1975, Aho et al. 1986 |
| D2 | Ambiguïté | Fonction univoque — entrée (grammaire + dérivation) qui fixe la sortie | Relation multivoque, $C_n \sim 4^n$ arbres — entrée (grammaire + chaîne) qui sous-détermine | Parikh 1966, Brabrand 2007 |
| D3 | Direction | Toujours descendante | Choix libre (LL, LR, …) | Shieber 1988 |
| D4 | Information | Connaissance complète | Inférence depuis la surface | Shannon 1948 |
| D5 | Inférence | gen < recog < infer | — | Gold 1967 |
| D6 | Temporalité | Causal : $S = 0$ | Prédictif : $S > 0$ | Hale 2001 |
Ce qu’il faut retenir
- L’écart de complexité côté reconnaissance croît avec le pouvoir expressif : de nul (Type 3, $\Theta(n)$) à indécidable (Type 0). Mais ce n’est qu’un axe : le couplage différentiel (reconnaissance ← classe de grammaire, génération ← spécification de tâche) et le renversement de signe (génération sous contrainte = NP-complète) interdisent de réduire l’asymétrie à « générer est facile » — voir L17 et L18.
- La génération est une fonction (univoque — pas « injective » : son entrée fixe la sortie) ; le parsing est une relation (une phrase → $k$ arbres) parce que son entrée est moins informative. Les nombres de Catalan $C_n \sim 4^n$ quantifient la croissance de l’ambiguïté.
- L’ambiguïté est intrinsèque à certains langages (Parikh 1966) et indécidable en général (Brabrand 2007). On ne peut ni l’éliminer ni même la détecter.
- Le paradoxe de Birman-Ullman confirme l’asymétrie : transformer un parser en générateur est facile (rétrogradation informationnelle), l’inverse est difficile (mise à niveau informationnelle).
- La surprisal formalise l’asymétrie temporelle : $S = 0$ pour le générateur (il crée le futur), $S > 0$ pour le parser (il prédit sous incertitude).
- Les six dimensions sont indépendantes : chacune capture un aspect distinct de la fracture génération-reconnaissance.
Pour aller plus loin
Complexité
- Aho, A.V., Sethi, R. & Ullman, J.D. (1986). Compilers: Principles, Techniques, and Tools. Addison-Wesley — complexités de CYK, Earley, LL, LR.
- Hopcroft, J.E. & Ullman, J.D. (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley — résultats fondamentaux.
Ambiguïté et multivocité
- Parikh, R.J. (1966). « On Context-Free Languages. » Journal of the ACM, 13(4), 570–581 — ambiguïté intrinsèque des CFL.
- Brabrand, C., Giegerich, R. & Møller, A. (2007). « Analyzing Ambiguity of Context-Free Grammars. » Science of Computer Programming — indécidabilité de l’ambiguïté.
- Billot, S. & Lang, B. (1989). « The Structure of Shared Forests in Ambiguous Parsing. » ACL — forêts de dérivation partagées.
- Jurafsky, D. & Martin, J.H. (2023). Speech and Language Processing (3rd ed.) — nombres de Catalan et ambiguïté.
Birman-Ullman
- Birman, A. & Ullman, J.D. (1973). « Parsing Algorithms with Backtrack. » Information and Control, 23(1), 1–34 — le paradoxe original.
Surprisal et temporalité
- Hale, J. (2001). « A Probabilistic Earley Parser as a Psycholinguistic Model. » NAACL — la surprisal comme modèle de difficulté de traitement.
- Levy, R. (2008). « Expectation-Based Syntactic Comprehension. » Cognition, 106(3), 1126–1177 — compréhension fondée sur l’attente.
- Stolcke, A. (1995). « An Efficient Probabilistic Context-Free Parsing Algorithm. » Computational Linguistics — parser Earley probabiliste, probabilités de préfixe.
Inférence grammaticale
- Gold, E.M. (1967). « Language Identification in the Limit. » Information and Control, 10(5), 447–474 — le résultat d’impossibilité fondamental.
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press — référence complète.
Dans le corpus
- L1 — Les niveaux de la hiérarchie et leurs automates
- L6 — Sémantique opérationnelle : un autre formalisme mathématique de la série L
- L9 — Type 2+ : TAG, CCG, MCFG
- L13 — Vue d’ensemble de l’asymétrie (version vulgarisée)
- L14 — La direction du parsing : LL, LR et le Dragon Book
- L16 — Pourquoi la bidirectionnalité n’a pas été transférée
- L17 — La matrice classe × tâche et le couplage différentiel
- L18 — Le renversement de signe : quand générer dépasse parser
- L19 — Le P-chain : le surprisal comme trace de la prédiction (D6)
- L20 — L’inférence : la troisième direction (D5)
Glossaire
- Ambiguïté intrinsèque : Propriété d’un langage (pas d’une grammaire) tel que toute grammaire qui l’engendre est ambiguë. Découverte par Parikh (1966).
- Birman-Ullman (paradoxe de) : L’observation que transformer un parser en générateur est facile, tandis que transformer une grammaire en parser est difficile — apparemment l’inverse de l’asymétrie, mais en réalité sa confirmation.
- Causal (système) : En traitement du signal, un système dont la sortie au temps $t$ ne dépend que des entrées aux temps $\leq t$. Le générateur est causal ; le parser sans lookahead aussi.
- Catalan (nombres de) : La suite $C_n = \frac{1}{n+1}\binom{2n}{n}$ qui compte le nombre d’arbres binaires à $n$ nœuds. Croissance exponentielle $\sim 4^n / n^{3/2}\sqrt{\pi}$.
- Forêt de dérivation partagée : Structure de données qui représente compactement (en $\mathcal{O}(n^3)$) un nombre exponentiellement grand d’arbres de dérivation. Le non-déterminisme est comprimé, pas éliminé.
- Fonction (gen) vs relation (parse) : La génération est une fonction (univoque) : son entrée — (grammaire + dérivation) — fixe la sortie. Ce n’est pas de l’injectivité (deux dérivations peuvent donner la même chaîne). Le parsing est une relation (une phrase → plusieurs arbres) car son entrée — (grammaire + chaîne) — est moins informative et sous-détermine l’arbre.
- PSPACE-complet : Classe de problèmes résolubles en espace polynomial mais pour lesquels aucun algorithme en temps polynomial n’est connu. Le parsing des grammaires context-sensitive est PSPACE-complet.
- Surprisal : $S(w_i) = -\log_2 P(w_i | w_1 \ldots w_{i-1})$. Mesure l’information apportée par un token en contexte. Zéro pour le générateur, positive pour le parser.
- $T_{\text{gen}}$, $T_{\text{parse}}$ : Fonctions de complexité en temps pour la génération et la reconnaissance respectivement, paramétrées par le niveau de Chomsky $k$ et la longueur $n$.
Prérequis : L1, L6, L13
Temps de lecture : 15 min
Tags : #formules #asymétrie #complexité #surprisal #Catalan #Parikh #Birman-Ullman