L18) The Sign Reversal
Why “generation is easy, parsing is hard” is false
Everyone repeats it: producing a sentence is trivial, understanding it is costly. This is a half-truth that becomes a lie as soon as you look closely. Under the right constraint, generating can be strictly more difficult than parsing — and this is not an intuition, it’s a theorem.
Where does this article fit in?
This article extends the first dimension (D1, Complexity) of the generation-recognition asymmetry studied in L13 and L17. The complexity matrix from L17 already showed that constrained generation “heats up”; here we take the reasoning to its conclusion and name the phenomenon: the sign reversal. This is the most counter-intuitive result from the research paper that this series popularizes.
Why is this important?
The slogan “generation is easy, parsing is hard” structures much of the intuition in computer science and computational linguistics. It justifies dedicating decades of research to parsing algorithms (LL, LR, Earley, CYK — see L14) and much less to generation. But if the slogan is false in the cases that matter, then our mental map of difficulty is wrong.
The stakes are not rhetorical. Designing a system that generates text, music, or code under constraints (a target meaning, an imposed format, a security requirement) means confronting precisely the case where generation becomes costly. Understanding when and why prevents under-sizing an entire system.
The idea in one sentence
Unconstrained generation is trivial ($\mathcal{O}(n)$), but semantic-constrained generation can be exponential or even NP-complete — thus strictly more difficult than parsing — because the real factor is not “which operation,” but “who imposes the constraint.”
Let’s explain step by step
1. The naive view, and why it’s appealing
The intuition behind the slogan is real. To generate, one simply starts from the grammar’s axiom and applies rules randomly until terminal symbols are reached. No difficult decisions: at each step, a rule is chosen and applied. To parse, on the contrary, one must reconstruct a hidden structure from the surface alone — resolving ambiguities, exploring competing hypotheses.
Hence the mental picture: generation $= \mathcal{O}(n)$ (linear in the length of the derivation), parsing $= \mathcal{O}(n^3)$ for context-free grammars (the bound of the CYK algorithm — see L15). Generation easy, parsing hard. End of story?
2. Yes, unconstrained generation is indeed trivial
Let’s start by acknowledging what is true. Free generation — applying rules without aiming for a particular output — is indeed $\mathcal{O}(n)$ for any formalism, from the simplest to the most powerful. This is the first row of the L17 matrix, uniformly green.
The problem is that this result is useless. A randomly generated string is “grammatical” (it belongs to language $L(G)$) but says nothing. Nobody generates randomly. A composer doesn’t place random notes; a dialogue system doesn’t respond with any random French sentence. Real generation always operates under constraints: a meaning to express, a form to respect, a register to maintain.
3. Constrained generation changes everything
Let’s formalize the constraint. We no longer ask “produce any string from $L(G)$,” but “produce a string from $L(G)$ that also satisfies an external condition $C$” — for example: “that expresses this precise meaning,” “that contains exactly these lexical units,” “that respects this format.”
For regular languages ($k=3$ in Chomsky’s hierarchy — see L1), everything is still fine. The constraint is encoded as a second automaton $A_C$, and generation amounts to producing a string in the intersection of the two languages, $L(G) \cap L(A_C)$ — computable by automaton product in polynomial time. Mohri (1997) shows that the output of a deterministic transducer remains linear in the size of the input. No drama.
The drama begins one step higher, with enriched context-free grammars — those that carry feature structures (attribute-value annotations attached to constituents, to express subject-verb agreement, gender, number, or verb subcategorization). These are the grammars of linguists: LFG, HPSG, FTAG. And there, complexity explodes.
4. Kay’s (1996) result: exponential
Martin Kay, one of the founders of computational linguistics, established that generating from a “flat” semantic representation is intrinsically exponential in the worst case. His formulation is clear:
« The process is exponential in the worst case because, if a sentence contains a word with $k$ modifiers, then a version will be generated with each of the $2^k$ subsets of those modifiers, all but one of them being rejected when it is finally discovered that their semantics does not subsume the entire input. »
— Kay (1996, p. 202)
The intuition: in parsing, the string provides a positional index — “between position 3 and position 7, there is a noun phrase.” This index is precisely what makes parsing polynomial (CYK’s dynamic programming exploits positions). In generation, the string does not yet exist: it is the output being constructed. Without a positional index, the generator must consider all compatible semantic groupings — and there is an exponential number of them ($2^k$ for $k$ modifiers).
Decryption — “subsume.” One semantic representation subsumes another if it contains it as a particular case. The generator only knows at the end if the subset of modifiers it has assembled exactly covers the intended meaning — hence the waste: $2^k – 1$ discarded attempts.
5. Brew’s (1992) result: NP-complete, proven
Kay’s analysis describes a worst-case difficulty. Chris Brew goes further: he demonstrates that the problem is NP-complete, based on a minimal scheme of generation from a bag (multiset) of lexical signs. The proof involves a polynomial reduction from a known NP-complete problem, 3-Dimensional Matching:
« We now provide a polynomial-time reduction from an arbitrary instance of MENAGE A TROIS to an instance of Shake-and-Bake generation, which allows the same conclusion to be drawn for this problem. »
— Brew (1992, §2.1.3, p. 611)
Decryption — reduction. Reducing problem A to problem B means showing that solving B would allow solving A. If A is already known to be NP-complete (like 3-Dimensional Matching), then B is at least as difficult. Brew’s reduction transforms any instance of 3-Dimensional Matching into a generation instance: therefore, generating is NP-complete.
Why is Brew important beyond Kay? Because he establishes the intrinsic difficulty — a property of the problem itself, independent of the algorithm — and not just a worst-case slowness of a particular method. On a scheme stripped of all auxiliary machinery, generating remains NP-complete.
And moving further up the hierarchy, towards context-sensitive grammars ($k=1$), Barton, Berwick & Ristad (1987) show that the membership decision for agreement grammars (CFGs enriched with limited features) is already NP-complete by reduction from 3-SAT — which transfers to constrained generation.
6. The sign reversal
Let’s put the two sides face to face. On the recognition side, complexity grows with the expressive power of the grammar: $\Theta(n)$ for regular, $\mathcal{O}(n^3)$ for context-free, and so on (see L17). On the generation side, free or simply terminating, it remains polynomial everywhere. So far, the slogan holds.
But for semantic-constrained generation, the asymmetry changes sign starting from $k=2$ with features: generation becomes exponential (Kay) or NP-complete (Brew), while recognition remains polynomial ($\mathcal{O}(n^3)$). In other words: for the same grammar class, generating surpasses parsing.
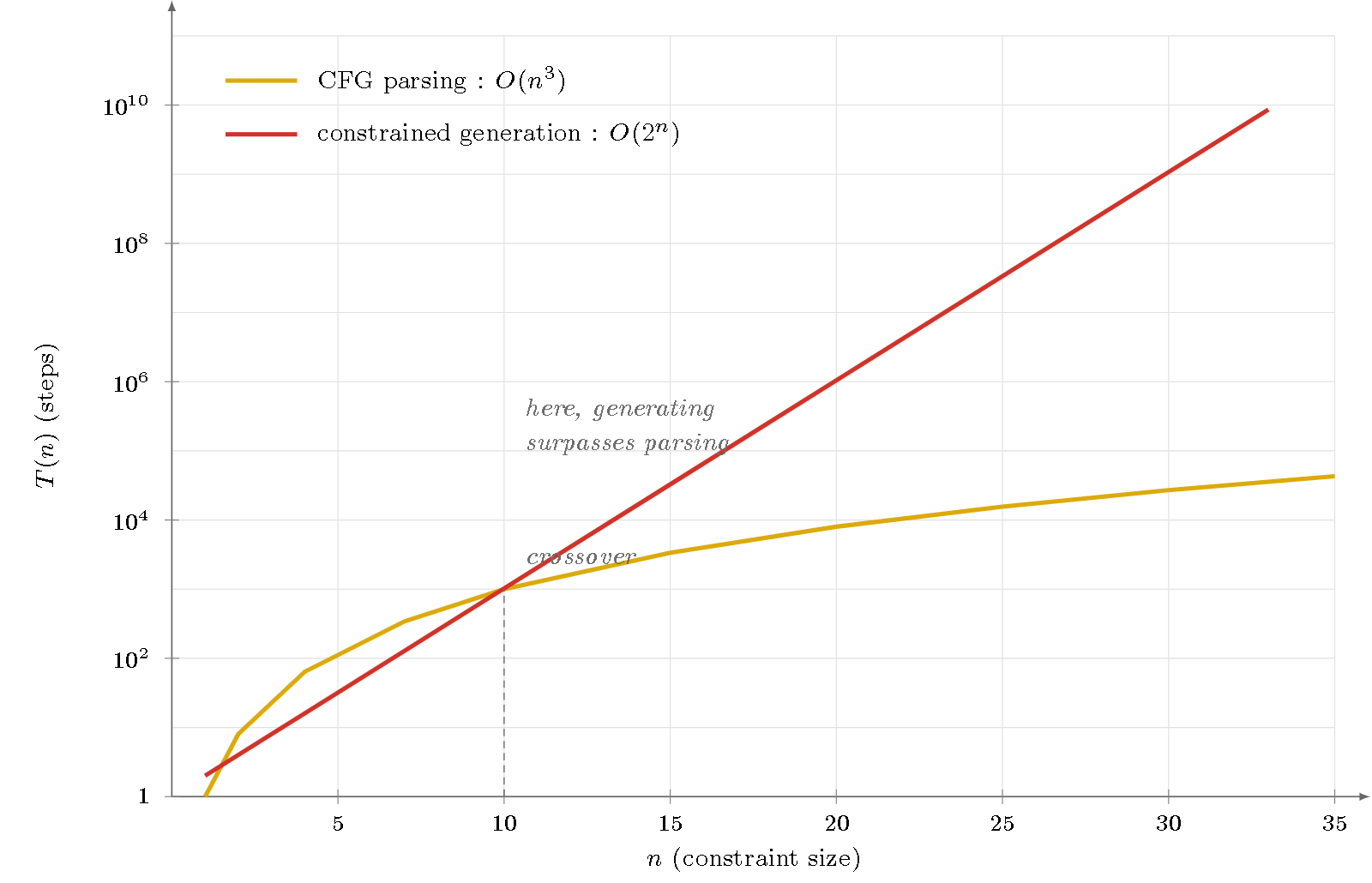
Figure 1 — The sign reversal (semi-logarithmic scale). For small constraints, generation appears faster; but its exponential curve ($\mathcal{O}(2^n)$, red) crosses and then surpasses the polynomial curve of parsing ($\mathcal{O}(n^3)$, yellow) around $n \approx 10$. Beyond that, constrained generation costs more than parsing — the exact opposite of the common slogan.
7. The true asymmetry is structural
If the slogan is false, what is true? The asymmetry is not a difference in difficulty between two operations; it lies in the locus of the constraint:
- The parser is always constrained: the input is given to it, non-negotiable. It has no choice in its difficulty — it is imposed by the received string.
- The generator can be constrained, or not, depending on the task. Without constraint, it benefits from $\mathcal{O}(n)$. Under strong constraint, it matches or surpasses parsing.
The divide is therefore not “generation vs. recognition” but “chosen constraint vs. suffered constraint.” This is the rigorous formulation of the intuition from L13: the receiver does not have the luxury of choice.
8. In music and large language models
The reversal is directly observable in real systems.
In computer-assisted composition: generating any melody within a style grammar is trivial. Generating a melody that modulates to a target key, respects an imposed meter and quotes a given motif — this is multi-constrained generation, precisely the costly regime. The composer using I2 in production mode feels it: the more safeguards they add, the tighter and more complicated the search space becomes.
In large language models (GPT and co.): autoregressive sampling seems instantaneous, at $\mathcal{O}(n)$ per token. But as soon as the output is constrained — format compliance (valid JSON), factual accuracy, security filters — the analytical cost is reintroduced. Constrained generation in LLMs materializes the sign reversal in modern architectures: what seemed free becomes expensive as soon as something precise is demanded.
Key takeaways
- Unconstrained generation is trivial ($\mathcal{O}(n)$) but useless: nobody generates randomly.
- Semantic-constrained generation can be exponential (Kay 1996) or proven NP-complete (Brew 1992, by reduction from 3-Dimensional Matching).
- The sign reversal: for the same grammar, constrained generation can be strictly more difficult than parsing — the inverse of the common slogan.
- The structural cause: without the string, the generator lacks a positional index and must explore an exponential number of semantic coverings.
- The true asymmetry is not a difference in difficulty between operations, but the locus of the constraint: the parser always suffers it, the generator chooses it.
To go further
Constrained generation
- Kay, M. (1996). “Chart Generation.” Proceedings of ACL, 200-204 — the exponentiality argument.
- Brew, C. (1992). “Letting the Cat out of the Bag: Generation for Shake-and-Bake MT.” COLING 1992, 610-616 — the NP-completeness proof. DOI:10.3115/992133.992165
- Barton, G.E., Berwick, R.C. & Ristad, E.S. (1987). Computational Complexity and Natural Language. MIT Press — NP-completeness of agreement grammars (ch. 3).
- Mohri, M. (1997). “Finite-State Transducers in Language and Speech Processing.” Computational Linguistics 23(2), 269-311 — the regular case remains linear.
- Russell, G., Carroll, J. & Warwick-Armstrong, S. (1990). “Asymmetry in Parsing and Generating with Unification Grammars: Case Studies from ELU.” ACL 1990, 205-211 ��� case studies (clitics, empty semantic heads). DOI:10.3115/981823.981849
The popularized research article
- Peyrichou, R. (2026). The Generation-Recognition Asymmetry: Six Dimensions of a Fundamental Divide in Formal Language Theory. §4.1 develops the sign reversal. Preprint arXiv:2603.10139 — https://arxiv.org/abs/2603.10139
In the corpus
- L13 — Overview of asymmetry (6 dimensions)
- L15 — Mathematical formalizations
- L17 — The class × task matrix and differential coupling
- L1 — The classes of grammars
- L9 — Mildly context-sensitive formalisms
Glossary
- Free generation: applying grammar rules without aiming for a particular output. Always $\mathcal{O}(n)$.
- Constrained generation: producing a string that satisfies an external condition $C$ (target meaning, format, lexical occurrences). Can be NP-complete starting from CFGs enriched with features.
- Feature structure: attribute-value annotation attached to a grammatical constituent (agreement, gender, number, subcategorization).
- NP-complete: belongs to the class of the most difficult problems among those whose solution can be verified in polynomial time; no known polynomial algorithm, and likely none exists (unless $P = NP$).
- Reduction (polynomial): transformation, in polynomial time, of instances of one problem into instances of another; used to transfer difficulty.
- 3-Dimensional Matching: a three-set matching problem, a reference NP-complete problem, starting point for Brew’s reduction.
- Positional index: positional information in the input string (“from position $i$ to $j$“), which makes parsing polynomial and is lacking in generation.
- Sign reversal: the fact that, under semantic constraint, the asymmetry of difficulty reverses — generation becomes more costly than recognition.
Links in the series
- L13 — Generate or recognize — the asymmetry in 6 dimensions, including the naive view (§1.3)
- L15 — The formulas of asymmetry — where $\mathcal{O}(n^3)$ and Catalan numbers come from
- L17 — The complexity matrix — the “constrained” row that this article deepens
- L14 — The direction of parsing — why the parser has a degree of freedom
Prerequisites: L13, L15, L17
Reading time: 11 min
Tags: #asymmetry #constrained-generation #NP-completeness #Kay #Brew #sign-reversal