L13) Generate or Recognize
The Duality of Formal Grammars
A grammar is not only used to produce sentences. It can also analyze them. But these two uses—generation and recognition—are neither symmetric nor equivalent. This asymmetry, rarely discussed, is nevertheless at the heart of music.
Where Does This Article Fit In?
In L1, we discovered the hierarchy of formal languages. In L2, we learned how to construct grammars that produce sentences through derivation. But we have always worked in a single direction: from meaning to sentences.
This article poses a question: what happens when we reverse the direction? When, instead of producing a sentence from a grammar, we receive a sentence and seek to understand whether it belongs to the language—and what structure the grammar assigns to it?
This is the difference between composing and analyzing, between speaking and listening, between encoding and decoding. And this difference is far from trivial.
Why It Matters
A Famous Terminological Pitfall
The most cited book in formal music theory is titled A Generative Theory of Tonal Music (GTTM, Lerdahl & Jackendoff, 1983—over 5,000 citations). Yet, GTTM does not generate any music. It is an analytical theory: given an existing musical piece, it provides preference rules to assign it a hierarchical structure (grouping, metrical structure, time-span reduction).
The term “generative” is used in the original Chomskyan sense—a set of formally explicit rules—and not in the sense of “production.” Lerdahl himself clarified that GTTM models the listener (reception), not the composer (emission) [Lerdahl2009].
This confusion illustrates a deeper problem: we use the same word—”grammar”—for two fundamentally different activities.
Two Sides of the Same Coin
Every formal grammar defines a language—a set of valid strings. But it can be used in two ways:
| Direction | Technical Name | Question Asked | Musical Analogy |
|---|---|---|---|
| → Generation | Production / Derivation | “What sentences can this grammar produce?” | The composer writes a piece |
| ← Recognition | Parsing / Analysis | “Does this sentence belong to the language? What structure corresponds to it?” | The musicologist analyzes a musical production |
Mathematically, both uses define the same language: the set of strings is identical. But operationally, the two directions are radically different.
The Idea in One Sentence
A formal grammar is a bidirectional object: it can generate sentences or analyze them, but the two directions differ along at least six independent dimensions—complexity, ambiguity, direction, information, inference, and temporality. The asymmetry is structural: the parser is always constrained, while the generator is not necessarily so.
Step-by-Step Explanation
1. Computational Asymmetry
The first difference is algorithmic in nature. For a context-free grammar (CFG, Context-Free Grammar—L2):
- Generating a sentence is fast: we start from the axiom (start symbol—the starting symbol of the grammar), apply the rewriting rules, and each step is a local choice. The complexity is linear in the length of the derivation.
- Recognizing a sentence is more costly: given a string of $n$ symbols, determining whether it belongs to the language and reconstructing its structure is done in $O(n^3)$ time with the CYK (Cocke-Younger-Kasami) or Earley algorithm. The known optimal theoretical bound is actually $O(n^\omega)$ with $\omega \approx 2.37$ (quasi-quadratic), via Valiant’s reduction (1975) to matrix multiplication—but remains super-linear.
For more expressive formalisms, the gap widens dramatically. Context-sensitive grammars (Type 1, L1) have a recognition problem that is PSPACE-complete (Polynomial Space complete—a complexity class for which no efficient algorithm is known in general) [Kuroda1964; Savitch1970].
In other words: producing is generally easier than analyzing.
But beware: this formulation is misleading. Unconstrained generation—applying rules at random—is trivial for any formalism. The result is “grammatical” but useless. Real generation operates under constraints (a target meaning, a style, aesthetic rules), and constrained generation can be just as difficult—or even strictly more difficult—than parsing (the sign reversal, demonstrated by Kay 1996 and Brew 1992; see L18). The true asymmetry is structural: parsing is always constrained (the input is given, non-negotiable), whereas generation may or may not be.
→ For the mathematical formalizations of this gap (the $T_{\text{parse}}$ formula per Chomsky level, semi-log graph), see L15.
Sidebar: The Puzzle Analogy
Building a 1,000-piece puzzle from the complete image is relatively simple: you determine how you are going to cut it, so you know which piece goes where. But receiving a scrambled puzzle and understanding how to assemble it—in what order, by what strategy—is a completely different problem. The grammar is the reference image; generation builds the puzzle; parsing disassembles it to understand its structure.
2. Ambiguity Asymmetry
The second difference concerns structural ambiguity—a unique phenomenon that manifests in three related aspects:
Determinism. In generation, one can choose one derivation at each step (possibly randomly, as in probabilistic PCFGs—see B1). The result is a single sentence. In recognition, a sentence can have multiple valid analyses: the same sequence of words can correspond to several derivation trees (L4).
In linguistics, the sentence “I saw the man with the telescope” has two analyses: I use the telescope to see, or the man has the telescope. In music, the same harmonic progression can be analyzed in several ways by GTTM (M6).
Non-injectivity. Formally, generation is an injective function: a derivation path produces a single sentence. Parsing is non-injective: the same sentence can correspond to $k$ derivation trees. Generation is a one-to-one process, recognition a one-to-many process.
Cardinality (Eco). Umberto Eco, in The Open Work (1962), formalized the same asymmetry in the aesthetic domain: a single production (the work) admits multiple interpretations (analyses). In music, the composer knows why they chose a particular note; the listener must infer this intention. The generation function converges (multiple intentions → one work), while the analysis function diverges (one work → multiple interpretations).
These three aspects—determinism, non-injectivity, and cardinality—are one and the same phenomenon viewed from three different angles.
3. Directional Asymmetry
The third difference is the most invisible—by virtue of being so familiar.
Generation has a fixed direction: it is intrinsically top-down. We start from the axiom (the intention, the “what to say”) and descend toward the terminal symbols (the surface, the words or notes). As Chomsky formulated it: a grammar generates “from top to bottom, not from left to right.”
Parsing, on the other hand, has a choice of direction. It can go top-down (LL, recursive descent), bottom-up (LR, shift-reduce), or combine both (Earley, left-corner). The Dragon Book—the reference book on compiler design—dedicates entire chapters to this choice. A choice that exists only for the parser.
The most striking observation: the parsing strategy most different from generation (LR, bottom-up) is the most powerful. The one that mimics generation (LL, top-down) is the weakest.
→ This dimension is developed in detail in L14.
4. Information Asymmetry
The generator has access to everything: the communicative intention, the stylistic constraints, the pragmatic context. The analyzer only has access to the observable signal—the acoustic surface, the sequence of symbols.
This is the fundamental problem of all music analysis: creative constraints are available to the generator but must be reconstructed by the analyzer. Shannon’s model (see section below) formalizes this asymmetry at the most fundamental level: the encoder knows the source, the decoder does not.
5. Temporal Asymmetry: Offline vs. Real-Time
The four previous asymmetries implicitly assume that we have all the time we need—that we are working offline. But when the constraint of real-time is added, the asymmetry deepens.
- Generating in real-time is relatively natural: we produce symbol by symbol, on the fly. A musician improvising, a live coder modifying their code during a concert—each decision is local and immediate.
- Analyzing in real-time is much more difficult: we receive the signal as it unfolds, without knowing what comes next. The analyzer must maintain multiple hypotheses about the ongoing structure—this is the problem of incremental parsing [Hale2001].
In music, this asymmetry is omnipresent. A listener at a concert hears notes one by one. They cannot “go back” to re-analyze a passage. Their analysis is constrained by the flow—they must interpret in real-time, with partial information.
Sidebar: The Concert vs. The Score
A musicologist analyzing a Beethoven sonata has the complete score in front of them—they can go back and forth, compare distant passages, and revise their interpretations. A listener at a concert only has the sound flow: each second erases the previous one (except in memory). Both perform “analysis,” but under radically different temporal constraints. The former works offline (all information available at once); the latter works in streaming (partial, sequential, irreversible information).
The IDyOM model formalizes exactly this situation: it predicts the next note based on the notes already heard, without ever seeing the future. It is an incremental decoder in the Shannon sense—and this is precisely what makes it more difficult than generation.
→ Surprisal theory (Hale, Levy) mathematically formalizes this temporal asymmetry: see L15 §6.
6. The Bridge: Analysis-by-Synthesis
The analysis-by-synthesis paradigm, born in speech perception research in the 1960s, offers a bridge between the two directions: to recognize a signal, one generates internal candidates and compares them to the received signal [HalleStevens1962].
Analysis contains synthesis as a sub-process. The receiver is not a simple passive filter: it possesses an internal generative model that produces hypotheses, which are tested against the input.
In music, this corresponds to the experience of the expert listener: when you hear a ii-V-I (the subdominant → dominant → tonic progression, for example Dm7 → G7 → Cmaj7 in C major), you anticipate the resolution because your internal model has generated this expectation. Models like IDyOM (Information Dynamics of Music—a musical prediction model based on corpus statistics) formalize exactly this predictive process [Pearce2018].
7. Reversible Grammars
Some formalisms are designed to work in both directions using the same grammar:
- GF (Grammatical Framework, Ranta, 2019)—a multilingual formalism where grammars are explicitly reversible, allowing both parsing and generation [Ranta2019]
- Unification grammars—used in bidirectional machine translation [vanNoord1990]
- Steedman (1984 → 2014)—the same CCG (Combinatory Categorial Grammar—L9) grammar for jazz progressions was used first to generate chord sequences [Steedman1984], and then 30 years later to parse them (analyze them automatically) [GranrothWilding2014]. This is a remarkable example of the same musical grammar being used in both directions—with very different computational challenges.
But reversibility is not automatic. Strzalkowski (1993) showed that a grammar designed for parsing requires transformations (an “inversion”) to be used in generation. The very fact that an inversion process is necessary proves the operational asymmetry [Strzalkowski1993].
→ Bidirectionality has existed for 50 years in NLP—why is it not everywhere? See L16.
8. In Music: Three Paradigms
The generation/recognition duality structures the entirety of computational musicology. We can classify formal musical systems into three paradigms, depending on the directions they support:

Figure 1 — Chronological taxonomy of formal musical systems according to the directions they support: analytical (blue), generative (green), neural (purple), bidirectional (red). The dashed line between Steedman 1984 and the 2014 parser illustrates the 30-year gap between generation and parsing for the same CCG grammar.
The analytical paradigm—grammar as a listening tool. These systems receive an existing piece and determine a structure that corresponds to it:
- GTTM (Lerdahl & Jackendoff, 1983): listener model, not composer model (M6)
- Computational Schenkerian Analysis (Mavromatis & Brown, 2004): parsing of an existing piece to extract its deep structure
- IDyOM (Pearce, 2018): statistical model of musical prediction—the listener as an inference machine
- Melodic Graph Grammar (Finkensiep et al., 2019): melodic parsing of Hindustani music—an analytical tool applied to a non-Western repertoire
- Grammar-Based Compression (Humphreys et al., 2021): grammar induction as an implicit analytical tool—compressing a piece means extracting its structure
The generative paradigm—grammar as a composition tool. These systems produce music from rules or patterns, but cannot analyze:
- Generative Musical Grammars (Holtzman, 1981): pioneering use of context-free grammars for automatic composition
- Max (Puckette, 1988/IRCAM): visual dataflow programming for real-time audio—born at IRCAM, it has become the dominant platform for electroacoustic creation and interactive art
- SuperCollider (McCartney, 1996): open-source platform for audio synthesis and algorithmic composition—its pattern library (Pbind, Pseq, Prand…) constitutes a generative formalism embedded in the language. It is also the target of BP2SC (I1) and the host of TidalCycles (I3)
- OpenMusic (Assayag et al., 1999/IRCAM): computer-assisted composition environment—visual programming in Lisp with constraint solving, used by many contemporary composers (Music Representation Team, IRCAM)
- Euterpea (Quick & Hudak, 2013): functional composition in Haskell—music as an algebraic data type
- TidalCycles (McLean, 2014): live coding via temporal patterns—direct heir of Bel (M11), runs on SuperCollider
- Musical L-systems (Roncoroni, 2021): Lindenmayer parallel grammars applied to generative remixing—an intrinsically unidirectional formalism
- CFG+Markov System (Kamberaj et al., 2025): CFG for chord progressions and Markov chains for melody—a fully generative system
Beyond formal approaches, neural generation has transformed the landscape since 2020. These systems do not use any explicit grammar—musical “rules” are entirely implicit in the weights learned by deep learning:
- Jukebox (Dhariwal et al., 2020): raw audio generation via VQ-VAE (Vector Quantized Variational Autoencoder)—OpenAI
- MusicLM (Agostinelli et al., 2023): text-to-music generation via a hierarchical sequence-to-sequence model—Google
- MusicGen (Copet et al., 2023): single-stage autoregressive transformer, conditioned by text or melody—Meta
- Suno (2023): text-to-song generation accessible to the general public, including vocals and lyrics—unpublished architecture
These systems are powerfully generative but entirely opaque: they can neither analyze an existing piece, nor explain their choices, nor expose the “rules” they have learned. The absence of an explicit grammar is precisely what makes them inexplicable. The analytical cost has not disappeared—it has been shifted to the training phase (see L16).
The bidirectional paradigm—grammar as a bridge. These systems use the same grammar in both directions, but with highly variable degrees of integration:
- Jazz CCG (Steedman, 1984 → Granroth-Wilding, 2014): the same combinatory categorial grammar for jazz progressions, first used to generate, then 30 years later to parse. A remarkable case—but the two directions were developed separately.
- EMI (Cope, 1989): Experiments in Musical Intelligence—the system analyzes a corpus to extract stylistic conventions, then generates new pieces in the same style. Both directions in a single system, but sequentially (analysis first, generation second).
- Bol Processor (Bel & Kippen, 1992): the most integrated case. BP3 has three modes of using the same grammar:
– PROD (production, modus ponens): the grammar generates musical sequences
– ANAL (analysis, modus tollens): the grammar tests whether a sequence belongs to the language and, if so, identifies its structure
– TEMP (template exploration): the grammar exhaustively enumerates all possible derivation structures, producing structural skeletons that can optionally accelerate analysis (ANAL) or serve as an autonomous design tool
- OMax/SoMax (Assayag, Dubnov et al., 2006/IRCAM): machine improvisation based on the Factor Oracle automaton—a formal automaton (Type 3) built in real-time from a musician’s playing (analysis), then traversed to generate improvised responses. The same formalism serves both directions, but the analysis remains at the level of surface sequences (no deep structure)
- Antescofo (Cont, 2008/IRCAM): score following coupled with a reactive language for accompaniment generation—both directions function simultaneously in real-time, but rely on different formalisms (probabilistic models for analysis, synchronous language for generation)
- Unified Voice-Leading Model (Harrison & Pearce, 2019): analysis and generation of voice-leading in a single framework—a recent and rare case of explicit musical bidirectionality
The complete cycle of Bel and Kippen for the tabla perfectly illustrates the duality: a musician produces sequences of bols (mnemonic syllables of the tabla—B2), the system analyzes these sequences to infer a grammar (via QAVAID, Question Answer Validated Analytical Inference Device—an interactive grammatical inference system), and then this grammar can re-produce new sequences, which the musician evaluates. It is an analysis → grammar → generation → evaluation → analysis loop [KippenBel1989].
9. The Third Direction: Grammatical Inference
Beyond the generation/recognition duality, there is an even more fundamental third direction: grammatical inference (grammar induction)—given examples of sentences, finding the grammar itself [delaHiguera2010].
This is the inverse problem of formal language theory. The three operations form a hierarchy of increasing difficulty:
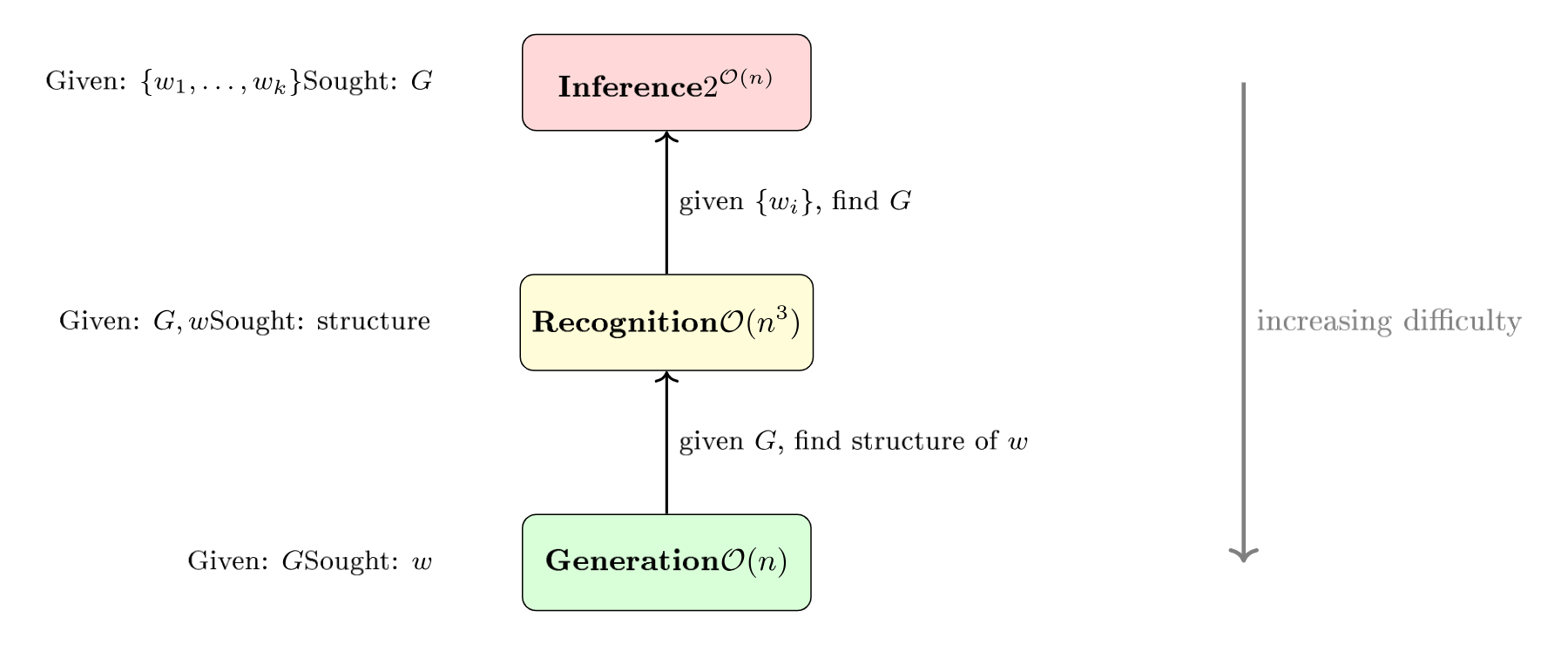
Example-generation ($\mathcal{O}(n)$) is the simplest: we apply the rules. Recognition ($\mathcal{O}(n^\omega)$, i.e., $\approx \mathcal{O}(n^{2.37})$, for CFGs—$O(n^3)$ with CYK) is more costly: we reconstruct the structure. Inference ($2^{\mathcal{O}(n)}$) is the most difficult: we find the rules themselves from examples alone. (Note: this hierarchy holds for unconstrained sub-problems; generation under semantic constraints, however, becomes NP-complete—see the sidebar in §1 and L18.)
In music, this is exactly what a musicologist does when listening to a corpus and attempting to extract its “rules”—stylistic conventions, harmonic constraints, rhythmic patterns. It is also what grammatical inference systems like QAVAID for the tabla or the work of Cruz-Alcázar & Vidal for musical style identification do [CruzAlcazar2008].
This direction will be explored in detail in M10.
The Shannon Model: Encoder $\neq$ Decoder
The diagram below shows the complete chain: a source produces a message, the encoder transforms it into a signal, the channel adds noise, and the decoder attempts to reconstruct the original message.
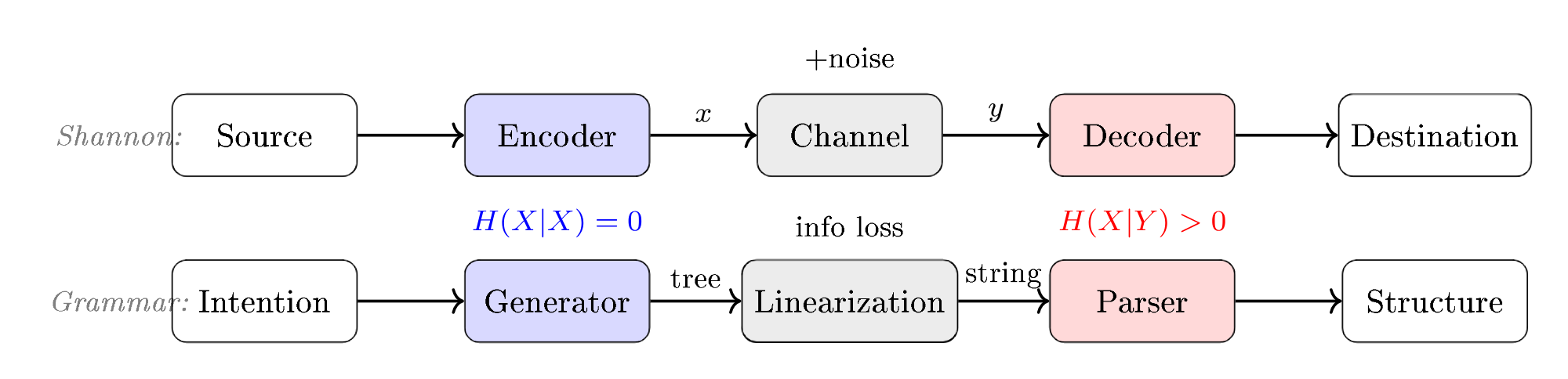
The encoder (generation) and the decoder (recognition) are not symmetric:
- The encoder transforms a message into a signal—it is a choice among possibilities
- The decoder reconstructs the message from the noisy signal—it is an inference of the most probable one
The channel introduces noise—uncertainty, loss. In music: the air is a noisy channel, the ear is an imperfect decoder, the score is a lossy encoder (it does not capture timbre, touch, or intention). Every translation between musical representations is an encoder → channel → decoder transition, with its own losses and ambiguities.
Key Takeaways
- Every grammar has two uses: generating (producing sentences) and recognizing (analyzing existing sentences).
- These two directions are mathematically equivalent (same language) but operationally asymmetric along six independent dimensions: complexity, ambiguity, direction, information, inference, and temporality.
- The asymmetry is not a simple “generating is easy, analyzing is hard.” Example-generation and recognition are both polynomial for CFGs (recognition in $O(n^\omega)$, $\omega \approx 2.37$). The true asymmetry stems from two mechanisms: a differential coupling (recognition depends on the class of grammar, generation on the task specification) and a sign reversal—generation under semantic constraints becomes NP-complete, thus harder than parsing (L18).
- In real-time, the asymmetry widens further: generating in streaming is natural (producing on the fly), while analyzing in streaming is difficult (not having seen what comes next—incremental parsing).
- Analysis-by-synthesis shows that recognition uses generation as an internal sub-process.
- In music, GTTM is analytical (despite its title), Steedman is bidirectional, and BP3 is explicitly reversible (PROD/ANAL/TEMP modes).
- Grammatical inference is the third direction: finding the grammar from examples—the fundamental problem of computational musicology.
To Go Further
Theoretical Foundations
- Berwick, R. (1984). “Strong Generative Capacity, Weak Generative Capacity, and Modern Linguistic Theories.” Computational Linguistics.
- Strzalkowski, T. (1993). Reversible Grammar in Natural Language Processing. Springer—seminal work on reversible grammars.
- de la Higuera, C. (2010). Grammatical Inference: Learning Automata and Grammars. Cambridge University Press—reference on grammatical inference.
Music
- Lerdahl, F. & Jackendoff, R. (1983). A Generative Theory of Tonal Music. MIT Press—the most influential analytical model.
- Steedman, M. (1984). “A Generative Grammar for Jazz Chord Sequences.” Music Perception—jazz grammar later used for parsing (Granroth-Wilding & Steedman, 2014).
- Puckette, M. (1988). “The Patcher.” ICMC—Max, real-time visual programming born at IRCAM.
- Bel, B. & Kippen, J. (1992). “Modelling Music with Grammars: Formal Language Representation in the Bol Processor”—the bidirectional system par excellence.
- Assayag, G., Rueda, C. & Laurson, M. (1999). “Computer-Assisted Composition at IRCAM: From PatchWork to OpenMusic.” Computer Music Journal, 23(3), 59–72—constraint-assisted composition.
- Cruz-Alcázar, P.P. & Vidal, E. (2008). “Two Grammatical Inference Applications in Music Processing.” Applied Artificial Intelligence.
- Assayag, G. & Dubnov, S. (2004). “Using Factor Oracles for Machine Improvisation.” Soft Computing, 8(9), 604–610—OMax, improvisation via Factor Oracle automaton (IRCAM).
- Cont, A. (2008). “Antescofo: Anticipatory Synchronization and Coupling.” ICMC—score following and reactive accompaniment (IRCAM).
- Finkensiep, C., Neuwirth, M. & Rohrmeier, M. (2019). “Generalized Graph Grammar for North Indian Melodic Syntax.” DLfM—melodic parsing applied to Hindustani music.
- Harrison, P.M.C. & Pearce, M.T. (2019). “A Unified Model for Voice-Leading Analysis and Generation.”—explicit musical bidirectionality for voice-leading.
- Humphreys, G. et al. (2021). “Grammar-Based Compression for Music Analysis.”—grammar-based compression as an implicit analytical tool.
- Kamberaj, B. et al. (2025). “CFG-Based Chord and Markov Melody Generation.”—fully generative system.
- McCartney, J. (2002). “Rethinking the Computer Music Language: SuperCollider.” Computer Music Journal, 26(4), 61–68—the open-source platform for audio synthesis and algorithmic composition.
- Roncoroni, L. (2021). “L-Systems for Musical Remixing.”—Lindenmayer parallel grammars applied to musical generation.
Neural Generation
- Dhariwal, P. et al. (2020). “Jukebox: A Generative Model for Music.” arXiv:2005.00341—raw audio generation via VQ-VAE (OpenAI).
- Agostinelli, A. et al. (2023). “MusicLM: Generating Music From Text.” arXiv:2301.11325—hierarchical text-to-music generation (Google).
- Copet, J. et al. (2023). “Simple and Controllable Music Generation.” NeurIPS—MusicGen, single-stage transformer, text/melody conditioning (Meta).
Temporal Asymmetry and Incremental Parsing
- Hale, J. (2001). “A Probabilistic Earley Parser as a Psycholinguistic Model.” NAACL—foundational model of probabilistic incremental parsing.
Analysis-by-Synthesis
- Halle, M. & Stevens, K.N. (1962). “Speech Recognition: A Model and a Program for Research.” IRE Transactions on Information Theory.
- Poeppel, D. & Monahan, P.J. (2011). “Feedforward and Feedback in Speech Perception: Revisiting Analysis by Synthesis.” Language and Cognitive Processes.
Deepening the Asymmetry
- L14 — The direction of parsing: LL, LR, and the Dragon Book (D3)
- L15 — The formulas of asymmetry: T_parse, surprisal, Birman-Ullman
- L16 — The paradox of bidirectionality: 50 years of forgotten reversible grammars
In the Corpus
- L1 — Complexity levels
- L2 — Grammars that produce
- L9 — Mildly context-sensitive formalisms (TAG, CCG)
- L18 — Sign reversal: when generating exceeds parsing
- L19 — The P-chain: the cognitive bridge (predicting by producing)
- L20 — Inference: the third direction
- M6 — GTTM: the analytical paradigm applied
- M10 — Grammatical inference in music (forthcoming)
- B6 — BP3 wildcards: pattern matching in the grammar
Glossary
- Analysis-by-synthesis: A recognition paradigm where the receiver generates internal candidates and compares them to the received signal. Analysis contains synthesis as a sub-process.
- ANAL (mode): Analytical mode of the Bol Processor—the grammar tests whether a sequence belongs to the language (modus tollens).
- Structural ambiguity: Property of a sentence that admits multiple derivation trees for the same grammar. Common in recognition, absent in generation.
- Encoder / Decoder: In the Shannon model, the encoder transforms a message into a signal (generation), and the decoder reconstructs the message from the signal (recognition). They are not symmetric.
- Reversible grammar: A grammar designed to be used in both directions (generation and parsing) without transformation. Examples: GF, unification grammars.
- IDyOM (Information Dynamics of Music): A statistical model of musical prediction based on the entropy of a corpus. It models the listener as an inference machine.
- Grammatical inference (grammar induction): The “third direction”—finding the grammar from examples of sentences. The inverse problem of formal language theory.
- Modus ponens / modus tollens: In logic, modus ponens goes from the rule to the consequence (if A then B, A, therefore B—generative direction). Modus tollens goes from the observation to the premise (if A then B, B observed, therefore A is plausible—analytical direction).
- NLG / NLU (Natural Language Generation / Understanding): The two sub-fields of NLP (Natural Language Processing) that embody the generation/recognition duality.
- Incremental parsing: Syntactic analysis that processes the input symbol by symbol, as it is received, without waiting for the end of the sentence. Necessary for real-time analysis. More difficult than offline parsing because the analyzer does not have access to the rest of the signal.
- Parsing (syntactic analysis): The process that, given a sentence and a grammar, determines whether the sentence belongs to the language and reconstructs its structure (derivation tree).
- PROD (mode): Production mode of the Bol Processor—the grammar generates musical sequences (modus ponens).
- QAVAID (Question Answer Validated Analytical Inference Device): An interactive grammatical inference system by Bel & Kippen for the tabla. The name also means “grammar” in Arabic/Urdu.
Prerequisites: L1, L2
Reading time: 14 min
Tags: #grammars #duality #generation #recognition #parsing #analysis-by-synthesis #BP3